

Google Cloud Platform 에서 제공하는 오픈 데이터인 Google Merchandise Store 를 활용해서 BigQuery에 익숙해지고, 이커머스 로그 데이터를 활용한 그로스 분석을 적용해보고자 해당 프로젝트를 시작하게 됐습니다.
Google Merchandise Store는 Google 브랜드의 상품을 판매하는 전자상거래 사이트입니다. 트래픽 소스 데이터, 콘텐츠 데이터, 거래 데이터가 담겨져있습니다.
구글 BiqQuery는 부분적으로 무료이기에 제공되는 스토리지와 쿼리양에 상한이 있습니다. 이런 이유로, Google Merchandise Store 데이터에서 데이터 샘플링을 진행했습니다.
목차
1. 빅쿼리에서 데이터셋 샘플링
해당 데이터셋은 2016년 8월 1일 ~ 2017년 8월 1일까지 총 1년간의 GA 세션 데이터를 담고 있기 때문에 데이터양이 매우 방대하다. (약 90만 행..)
GCP에서 빅쿼리를 활용해 데이터셋 샘플링을 먼저 진행했다.
테이블 샘플링은 어떻게?
먼저, 빅쿼리의 일반적인 샘플링 방식은 크게 2가지로 나뉘는데, 아래와 같다.
•
RAND() 방식과
•
TABLESAMPLE() 방식
RAND() 방식의 경우, 전체 테이블을 스캔하기 때문에 테이블이 많고, 데이터양이 많다면 오랜 시간과 비용이 발생한다. 반면에, TABLESAMPLE()의 경우, 데이터의 임의 하위 집합을 쿼리할 수 있기 때문에, RAND에 비해 시간과 비용이 절약될 수 있다.
데이터양이 방대하고, 테이블의 개수도 많다면 TABLESAMPLE() 을 쓴다고 한다 테이블 샘플링의 동작 방식
데이터가 빅쿼리 테이블에 저장되는데, 이때 테이블은 하나 이상의 블록으로 구성된다.각 블록은 물리적으로 별도의 저장소에 관리되며, 빅쿼리는 이러한 블록들을 효율적으로 관리해서 데이터의 처리, 검색 기능을 최적화한다고 보면 된다.
즉, 데이터가 적재될 때 데이터 블록들로 구성되어 저장된다는 얘기다.
→ 이런 특징이 대용량 데이터를 처리할 때 유용하게 해주고, 분할과 병렬 처리를 가능하게 해준다는 큰 장점이 있다.
TABLESAMPLE 은 이 데이터 블록들을 임의추출하여 해당 블록의 데이터를 모두 읽는 방식으로 작동한다.
이때, 하나의 데이터 블록에 저장되는 행의 개수에 따라 샘플링의 기본 단위가 결정된다. 따라서, 사용자가 샘플링의 비율을 1%, 10%,,, 등 구체적으로 명령해도, 원하는 만큼의 데이터가 샘플링되지 않을 수 있다.
즉,
•
블럭의 기존 단위 수보다 샘플링 할 개수가 많으면 블럭의 최소 단위 수까지 다운 샘플링
•
블럭의 기존 단위 수보다 샘플링 할 개수가 적으면 블럭의 최소 단위 수까지 업샘플링
하게 된다.
특징은 블럭에 저장된 행의 개수는 테이블마다 상이하고, 심지어 같은 테이블의 블럭이라고 하더라도 블럭 내 행의 개수는 조금씩 차이가 날 수 있다는 점이다.
rand() 나 tablesample은 모두 재현성이 없다. 샘플링을 반복할 때마다 매번 추출되는 데이터가 달라진다.만약, 정확한 비율로 샘플링을 하고 싶다면, 방법도 있다. → limit 와 tablesample 을 혼용해주면 해결된다.
예를 들어, 전체 데이터 셋의 1% 를 추출하고 싶지만 기존 블럭의 최소 단위수보다 크다면 원하는 샘플개수보다 적게 샘플링 된다. 따라서, 2% 로 tablesample을 업샘플링한 후, limit으로 원했던 1%의 크기수만큼 절단해주면 해결된다.
이번 프로젝트에서 얼만큼의 샘플링을 진행할지 고민하며 시도해봤다.
•
1% 의 테이블 샘플수
SELECT count(1)
FROM `bigquery-public-data.google_analytics_sample.ga_sessions_*` TABLESAMPLE SYSTEM (1 PERCENT)
SQL
복사
결과 : 11192 개
•
10% 의 테이블 샘플수
SELECT count(1)
FROM `bigquery-public-data.google_analytics_sample.ga_sessions_*` TABLESAMPLE SYSTEM (10 PERCENT)
SQL
복사
결과 : 91853 개
•
rand와 tablesample 결합
SELECT COUNT(1) FROM `bigquery-public-data.google_analytics_sample.ga_sessions_*` TABLESAMPLE SYSTEM (10 PERCENT)
WHERE RAND() < 0.1
SQL
복사
결과 : 8564
여기서, 문제는 샘플링을 매번 반복할 때마다 매번 다르게 추출되기 때문인데,
→ 이렇게 하면, 추후 머신러닝 작업을 진행할 때나, 분석 시의 결과가 계속 달라지게 된다.
이에 대안으로 나온 것이 FARM_FINGERPRINT 함수다.
•
FARM_FINGERPRINT
해시 함수
→ 문자열을 입력받으면 숫자로 반환한다.
일반적으로 해시 결과로 나온 값을 10으로 나눠서 나머지에 기반해 샘플링을 한다고 한다.
이를 적용해 1% 샘플링을 진행했다.
SELECT * FROM `bigquery-public-data.google_analytics_sample.ga_sessions_*`
WHERE MOD(ABS(FARM_FINGERPRINT(fullVisitorId)),100) < 1
SQL
복사
9146 개의 데이터셋이 샘플링됐다.
→ 추출된 데이터를 추후 분석을 위해 GA_for_eda 데이터세트의 ga_sample10 이라는 이름으로 테이블에 저장해줬다.
1% 데이터 샘플링, 괜찮을까?
얼마만큼의 데이터 양이 적당하다는 절대적인 기준은 없다.
분석하는 목적과 방법에 따라 그 정도가 달라진다고 보면 된다.
일반적으로 통계적 분석이냐, 머신러닝(혹은 딥러닝) 이냐에 따라 상대적인 데이터 크기가 달라진다.
- 통계적 분석의 경우, 최소 500개 이상
- 머신러닝(혹은 딥러닝)의 경우, 변수의 수 * 100을 곱한 것보다 많은 양
분석하는 목적과 방법에 따라 그 정도가 달라진다고 보면 된다.
일반적으로 통계적 분석이냐, 머신러닝(혹은 딥러닝) 이냐에 따라 상대적인 데이터 크기가 달라진다.
- 통계적 분석의 경우, 최소 500개 이상
- 머신러닝(혹은 딥러닝)의 경우, 변수의 수 * 100을 곱한 것보다 많은 양2. Colab환경에서 BigQuery 사용하기
GCP의 빅쿼리 결과를 → 데이터 탐색 → 구글 코랩으로 연동
을 하게 되면 코랩이 열린다.
화면에 다음과 같은 설명이 나오는데,
•
설정(setup)
•
연동된 SQL 쿼리문 보기
•
연동된 결과 테이블을 dataframe으로 변경
•
describe() 함수로 통계 값 보기
으로 어떻게 빅쿼리를 사용하는지 알려주고 있다.
1.
setup
# @title Setup
from google.colab import auth
from google.cloud import bigquery
from google.colab import data_table
project = 'just-skyline-348007' # Project ID inserted based on the query results selected to explore
location = 'US' # Location inserted based on the query results selected to explore
client = bigquery.Client(project=project, location=location)
data_table.enable_dataframe_formatter()
auth.authenticate_user()
Python
복사
2.
연동된 SQL 쿼리문 보기
# Running this code will display the query used to generate your previous job
job = client.get_job('bquxjob_3573e484_188d2e71052') # Job ID inserted based on the query results selected to explore
print(job.query)
Python
복사
get_job 인자에 작업 ID를 입력한다. 그리고 job.query()를 통해 쿼리문의 결과를 colab에서 출력할 수 있다.
빅쿼리는 쿼리문마다 작업 ID를 생성한다. 해당 Job_id는 bigquery의 쿼리 작업 정보에서 확인할 수 있다. 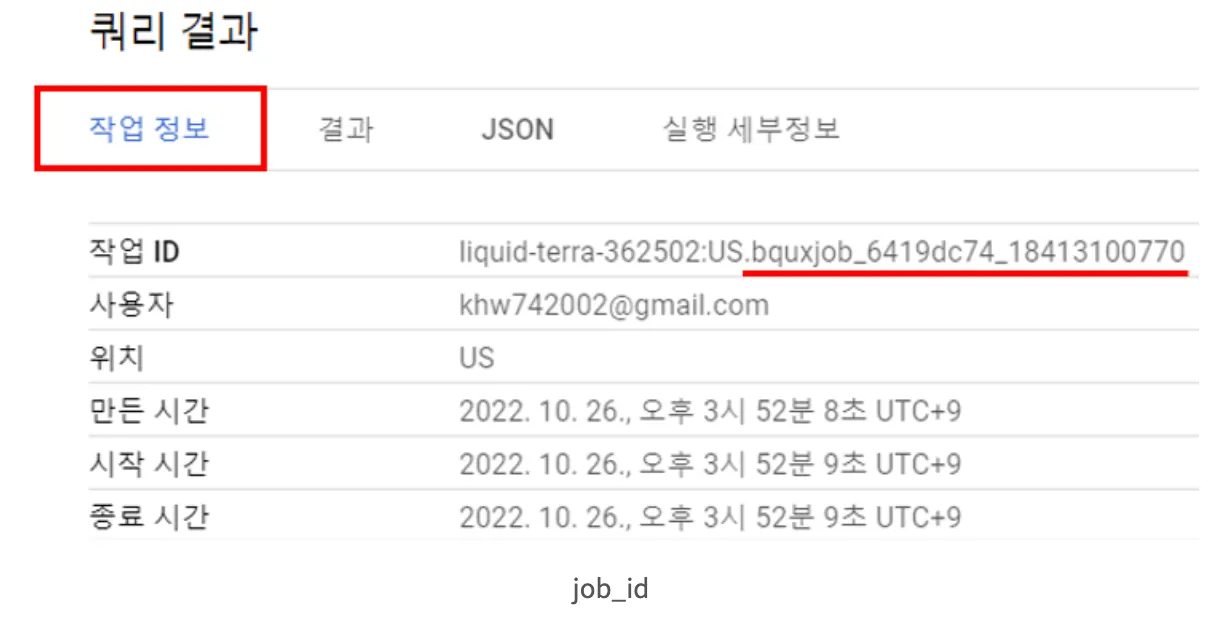
3.
연동된 결과 테이블을 DataFrame으로 변경
# Running this code will read results from your previous job
job = client.get_job('bquxjob_3573e484_188d2e71052') # Job ID inserted based on the query results selected to explore
results = job.to_dataframe()
results
Python
복사
쿼리의 결과를 담은 변수에 to_dataframe() 을 해주면 데이터프레임으로 변환해준다
disable_dataframe_formatter()를 추가로 입력하여 dataframe_format 끄기# 결괏값의 데이터프레임 포맷 끄기
data_table.disable_dataframe_formatter()
Python
복사
dataframe_format 에 익숙하지 않다면 꺼주자
colab에서 직접 BigQuery 수행하기
CASE 1.
project = 'majestic-gizmo-390314' # My Project ID
location = 'US' # Location inserted based on the query results selected to explore
auth.authenticate_user()
%%bigquery --project majestic-gizmo-390314
select *
from GA_for_eda.ga_sample10
limit 5
Python
복사
위의 방식으로 Colab 에서 빅쿼리를 돌릴 수 있고, 결과물도 확인할 수 있다.
CASE 2.
sample = '''
select visitNumber
,visitId
,fullVisitorId
,timestamp_seconds(visitStartTime) as UTC
,timestamp_seconds(safe_cast((visitStartTime) as int64) + 32400) as KOR
,date
,totals.bounces
,totals.hits
,totals.newVisits
,totals.pageviews
,totals.screenviews
,totals.sessionQualityDim
,totals.totalTransactionRevenue
,totals.transactions
,totals.UniqueScreenViews
,totals.visits
,trafficSource.adContent
,trafficSource.isTrueDirect
,trafficSource.campaign
,trafficSource.medium
,geoNetwork.country
,geoNetwork.region
,h.hitnumber
,h.eCommerceAction.action_type
,h.isEntrance
,h.isExit
,h.isInteraction
,product.isImpression
,h.type
,product.v2ProductCategory
,product.productBrand
,product.productPrice
,product.productQuantity
,product.productRevenue
,h.page.pagePath
,h.page.pageTitle
,h.eventInfo.eventCategory
,h.eventInfo.eventAction
,channelGrouping
from GA_for_eda.ga_sample10,
unnest(hits) as h,
unnest(product) as product
'''
client = bigquery.Client(project='majestic-gizmo-390314')
sample_result = client.query(sample)
# df = sample_result.to_dataframe()
# df.head()
Python
복사
위의 방식으로 똑같이 colab에서 코드를 짜고 구현할 수 있다.
CASE 1 과 CASE2 의 BigQuery 방법도 적용하면서, Pandas를 함께 활용하는 방식으로 진행했습니다.
3. 데이터 필드 선택하기
GA - 히트(Hit) / 세션(Session)
1.
히트
GA 에서 가장 작은 데이터 단위, 사용자가 웹사이트에서 행동하는 모든 개별적 상호작용 → Hit라고 한다.
2.
세션
사용자가 홈페이지에서 발생시킨 모든 행동의 집합. 1회 방문 동안 발생시킨 히트의 집합
세션이 종료되는 기준?세션의 유효 시간은 30분으로 설정되어 있다.
→ 30분 동안 아무런 활동이 없다면 세션은 종료된다.
단, 아래의 경우는 예외적으로 새로운 세션이 시작된다.
•
캠페인이 변경될 때
즉, 웹사이트 유입 경로가 변경 되면 세션은 종료된다.
즉, 네이버를 통해 방문했다가 조금 뒤에 인스타그램을 통해 웹사이트를 방문하면 다른 세션으로 기록한다.
•
날짜가 변경될 때 (자정을 넘길 경우)
날짜가 변경되면 30분이 되지 않아도 새로운 세션으로 계산한다.
예를 들어 11시 58분 PM에 방문했다가 12:03 AM 에 웹사이트를 떠나면, 첫번째 세션은 11시 59분 59초에 완료되고, 12:00 AM에 두번째 세션이 시작되는 것이다.
•
브라우저가 변경될 때
브라우저가 달라지면 세션도 달라진다. 즉, 크롬으로 웹사이트에 방문하다가, 사파리로 재방문하면 세션은 2개가 된다.
Bigquery Nested 필드 다루기

How to work with Array and Structs in BigQuery
Everything about Array, Struct, Record, Repeated, nested schema, usage, query in Google BigQuery

https://medium.com/google-cloud/how-to-work-with-array-and-structs-in-bigquery-9c0a2ea584a6

BigQuery 로 어떻게 Nested Field 에 접근하는지에 관한 글을 참고했다.

먼저, BigQuery 데이터셋을 보면, 특정 필드안에 다수의 필드가 들어가 있는 형태로 이루어진 것을 확인할 수 있다.
먼저, 빅쿼리의 대표적인(특이한) 데이터 타입 RECORD(데이터 유형) 와 REPEATED(모드) 를 살펴보자.
•
RECORD (표준 SQL : STRUCT)
중첩되거나 반복되는 데이터 유형을 record 로 지정할 수 있다.
이 안에는 여러개의 key, value 쌍이 있을 수 있다.
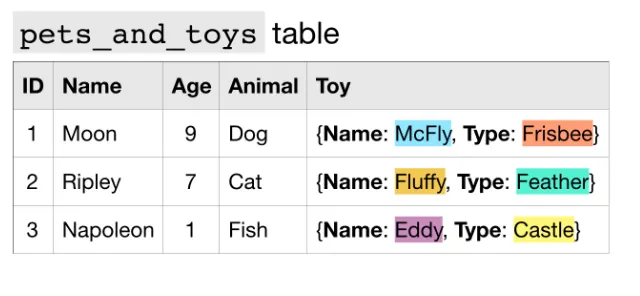
Toy 필드가 RECORD 데이터 유형이다.
안에 있는 Name이나 Type 은 매개변수들이다.

예를 들어서 위의 테이블의 경우, Toy 필드가 네스티드 필드인데, 구조를 살펴보면 오른쪽 그림과 같이 mode 가 RECORD로 되어 있는 것을 확인할 수 있다.
Toy 필드의 Name이나 Type에 접근하고 싶다면,
•
Toy.Name 또는 Toy.Type 처럼 사용해주면 된다.

다음으로, REPEATED가 있는데,
•
REPEATED (표준 SQL : ARRAY)
반복 데이터가 있는 열을 만들 때 사용하는 데이터 유형이다.
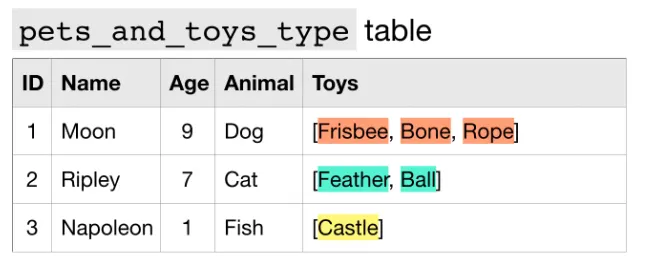
여기선 Toys 필드를 repeated data 라고 하는데, Array 형태로 하나 이상의 값을 가지고 있기 때문이다.
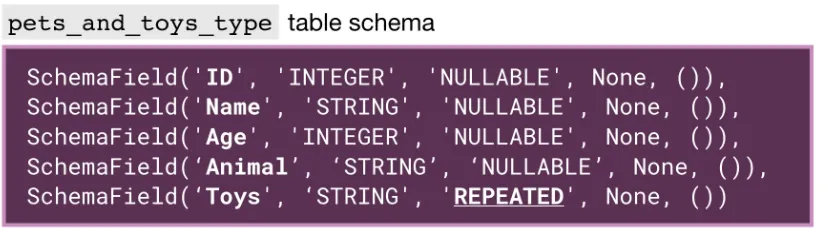
테이블 스키마를 보면, Toys 필드의 mode가 ‘REPEATED’ 로 나타나는 것을 확인할 수 있다.
어떻게 Array / Struct / Array_of_Struct 를 쿼리에 사용하나?
1.
Array
먼저, Array 의 경우에 그룹진 value 를 원한다고 하면, unnest 를 할 필요가 없다. 하지만, 해당 필드를 펼쳐서 여러 행으로 나타내고 싶다면, unnest 를 해야된다.
아래와 같은 1행에 3가지의 값을 지닌 Array 필드가 있다고 할 때, unnest 를 하지 않고 필드를 불러오면
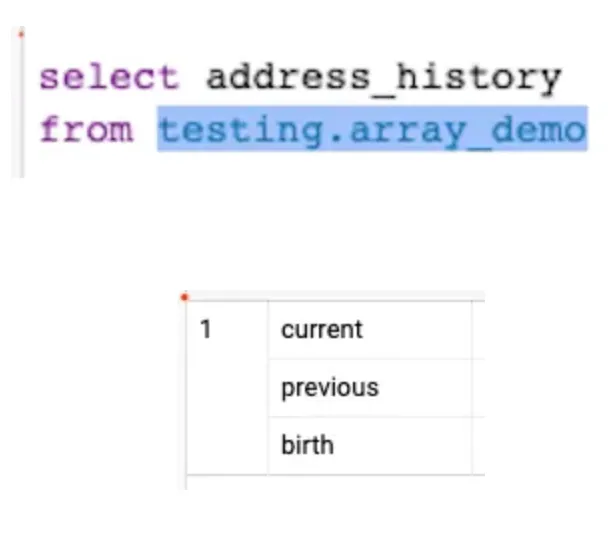
다음과 같이 결과는 1행으로 나오는 것을 확인할 수 있다.
반면에, unnest 를 해서 불러오게 되면
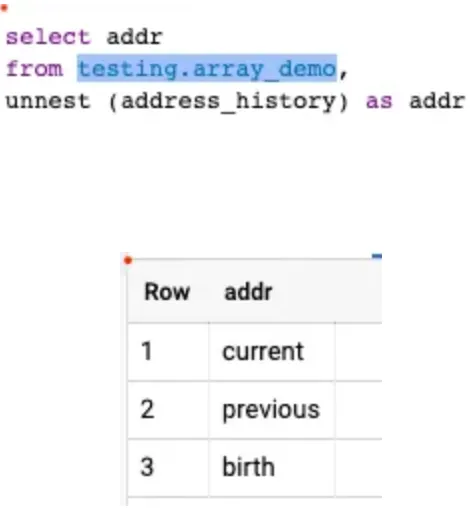
다음과 같이 결과가 3행으로 펼쳐져서 나타나는 것을 확인할 수 있다.
2.
Struct
struct 형태의 데이터타입은 unnest 할 필요는 없다.
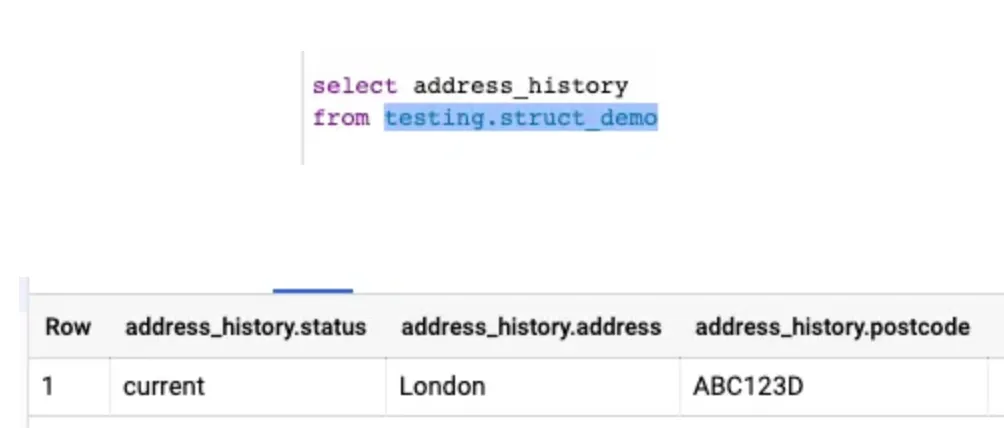
그냥 해당 필드만 입력해도, 알아서 status, address, postcode 필드를 함께 불러와준다.
물론, 구체적으로 필드 이름을 명시해서 불러올 수도 있다. 이때는 ‘ . ’ 를 이용해서 불러오면 된다.
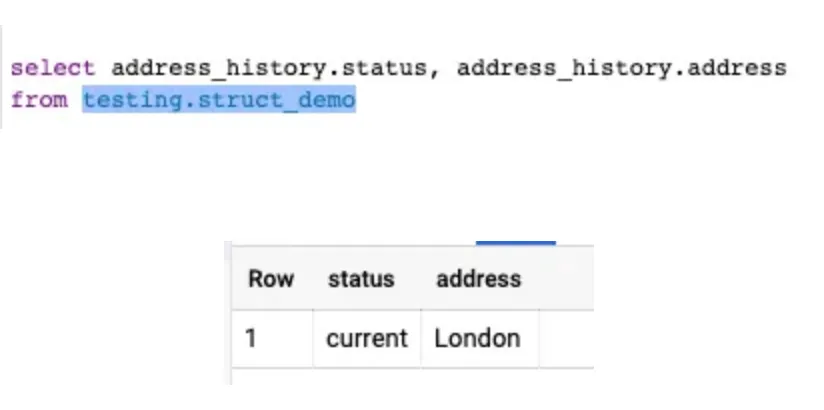
3.
Array of Structs
이 경우, 필드명만 선택해서 불러오면, 결과는 한 행으로 불러와진다.
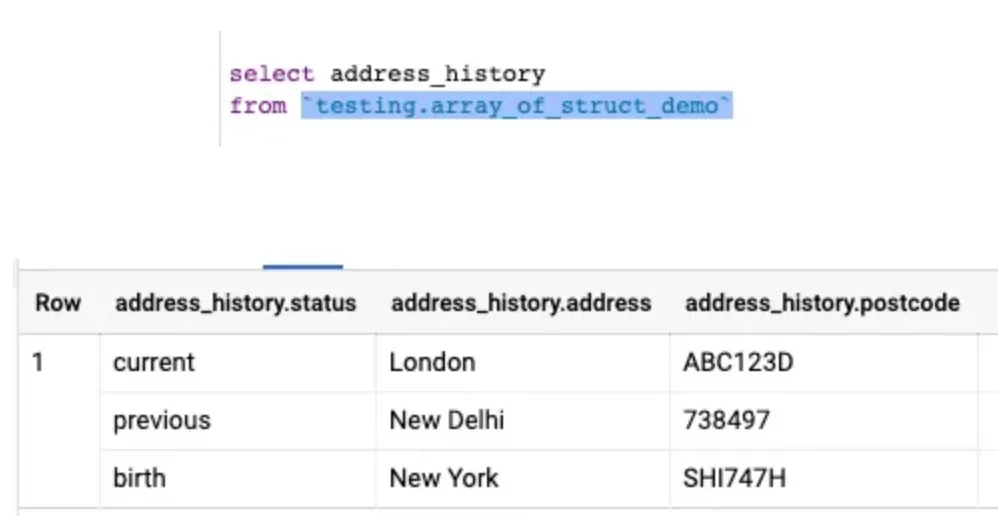
이런 식으로 각각의 struct 타입에서 반복되는 데이터들을 하나의 행으로 가져오는 것을 확인할 수 있다.
만약, 각각의 status , address, postcode 에 접근하고 싶다면, unnest 를 해서 여러 행으로 확장해주어야 한다. 그렇지 않으면 address_history.status 의 방식으로 접근했을 때, 오류가 발생한다.

위의 UNNEST() 함수를 통해서 데이터를 펼쳐낼 수 있다. 또한, Toys 필드에 alias 를 붙여줬기 때문에, nested 되어 있는 필드를 사용할 때 해당 alias 를 붙여서 사용하면 된다.
4.
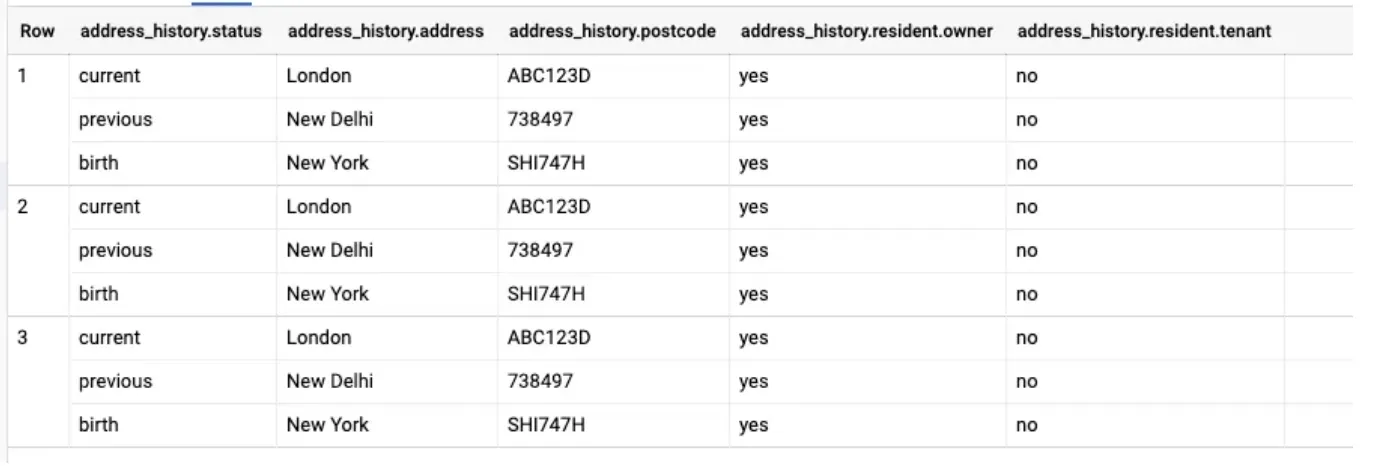
더 복잡한 Arrays having Struct inside another Struct 구조
3. 데이터 전처리
필드 선택
❗️ Campaign vs Medium vs Source
값이 존재하지 않는 필드는 제외하고, 분석에 활용할 만한 아래 필드를 선택했다.
필드 추출 쿼리
변수 타입, 형태 변환 전처리
UNIX time(= epoch time, POSIX time)
•
unix time 형태인 visitStartTime → timeStamp 으로 변환한다면?
주의 

•
visitId와 fullVisitorId 합쳐서 unique_sessionId 만들기 (가장 중요 ️)
️)◦
GA 데이터가 세션 기준으로 집계되는 것은 맞으나, 사용자마다 visitId가 겹칠 수 있기 때문에 해당 작업이 필요합니다.
•
세션이 자정을 넘어갈 경우, visitStartTime 은 두번 찍힌다.→ 예를 들어, 2/9 → 2/10

만든 고유 세션 id
Practice - 국가별 수입 분석
1년치 데이터(2016-08-01 ~ 2017-08-01) 전체에 대해서 국가별 매출액과 비율을 구해봤다.
가정 ︎ 쿼리 및 결과 추가 가능한 분석4. 가능한 분석 주제
4-1. 유입분석
•
유입기기별 유입 분석
모바일, 데스크탑, 태블릿별 유입 비율을 확인해봤다.
%%bigquery --project majestic-gizmo-390314
select device.deviceCategory AS device,
COUNT(1) / (SELECT COUNT(*) FROM GA_for_eda.ga_sample10) AS session_per_device
from GA_for_eda.ga_sample10
GROUP BY device
Python
복사

유입기기 비율을 확인해보니 데스크탑 비중이 약 75% 로 압도적인 것을 확인했다. 그외 모바일 22%, 태블릿은 약 3% 정도다. 아무래도, 웹 인터페이스를 중심으로 한 플랫폼이기 때문에 이런 수치가 나온 것으로 확인된다.
4-2. 방문수 & 페이지뷰 수 분석
순 방문자 수와 페이지뷰 수 현황을 파악해보기로 했다.
방문자 수(UV)와 페이지뷰 수(PV)를 왜 봐야하나 두 지표는 사이트의 성장 추세와 사이트의 매력도를 보여주기 때문에 꾸준히 모니터링하여 문제가 있거나 특이사항이 있다면 추가 분석을 진행해야 한다.
︎ 페이지뷰 수(PV)
︎ 페이지뷰 수(PV)페이지의 인기도를 의미할 수 있다. 하지만, 오히려 페이지 로딩 문제로 인해 페이지뷰 수가 증가하는 것일 수도 있고, 고객이 목적을 달성하기 위해 거쳐가는 여정에서 중복될 수도 있기 때문에 단순히 페이지뷰수만 크다고 해서 ‘해당 페이지가 인기가 있고, 좋은 페이지구나’ 라고 생각하면 위험하다!
상품 상세 페이지별로 분류해서 본다면, 어떤 상품이 인기가 많고, 요즘 트렌드는 어떤지 확인해볼 수 있다.
︎ 순 방문자 수(UV)
︎ 순 방문자 수(UV)그 자체로서의 의미보다는 재방문자수와 신규 방문자수 등으로 고객군을 나눠서 지표를 확인하는 것이 더 일반적이다. 특히, 방문자 수 중에서도 재방문자수를 점차 늘려가는 것이 비즈니스를 안정적으로 키워나갈 수 있는 방법이다.
집계를 어떻게 하느냐에 따라서 MAU , WAU, DAU 를 구할 수 있다. 물론, AU(active user)를 어떻게 정의하냐에 따라서 UV(unique visitor) 와는 계산이 다를 수도 있다는 점을 유의하자!
방문 수와 페이지뷰 수에 따른 해석 CASE 1 : 방문수 ↑ , 페이지뷰 수 ↑
CASE 2 : 방문수 ↑, 페이지뷰 수 ↓
CASE 3 : 방문수 ↓, 페이지뷰 수 ↑
CASE 4: 방문수 ↓, 페이지뷰 수 ↓
4-2-1. Google Merchandise Store 데이터에 적용하기
1.
방문수 & 페이지뷰 수
세션과 방문을 구분하는 것에서부터 시작했습니다!

GA 에서 [세션 / 페이지뷰 / 방문] 구별하기
적용 A.
순방문자수(UV)를 구할 때, 이벤트 조회로 유입된 사용자도 카운트하는 것으로 결정했다.
→ 고유한 세션수를 방문수로 본다면 총방문수는 다음과 같다.
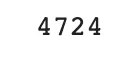
쿼리
적용 B.
•
총 순페이지뷰수
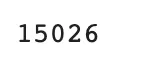
쿼리
적용 C.
•
페이지별 순페이지뷰수

•
페이지별 순페이지뷰수 비율
좀 더 직관적으로 느낌이 올 수있도록 비율도 확인해보자.

전체 순페이지뷰수 중에서
︎ ‘브랜드별 쇼핑 : 유튜브’ 페이지가 약 8% 로 가장 높은 순 페이지뷰수를 보이고 있다.
︎ ‘옷 : 남성 : 티셔츠’ 페이지가 약 3% 로 두번째 높은 순 페이지뷰수를 보였습니다.
︎ ‘브랜드별 쇼핑 : 유튜브’ 페이지가 약 8% 로 가장 높은 순 페이지뷰수를 보이고 있다.
︎ ‘옷 : 남성 : 티셔츠’ 페이지가 약 3% 로 두번째 높은 순 페이지뷰수를 보였습니다.쿼리
적용 D. 월별 추이 확인
사실상, 기간상의 변화를 봐야 문제인지 아닌지를 확실하게 판별할 수 있습니다.
•
월별 순방문자수(UV), 순페이지뷰수(UPV)
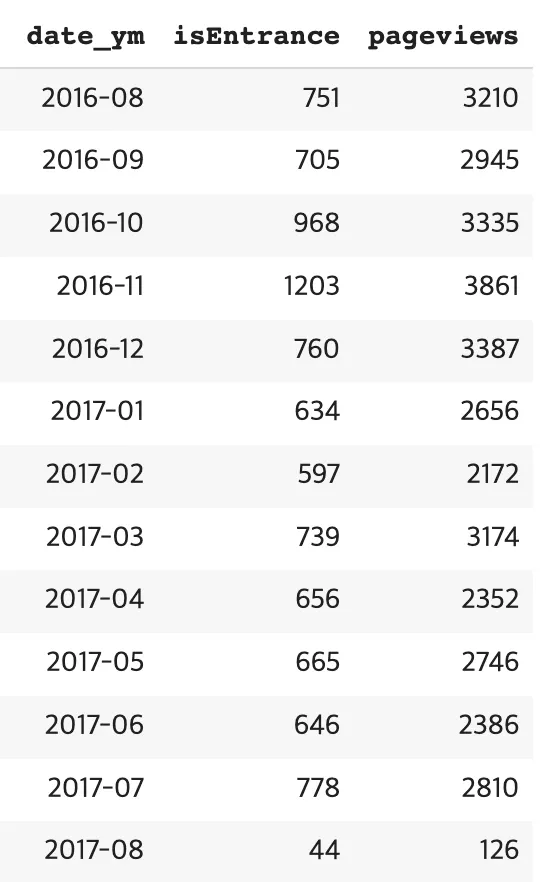
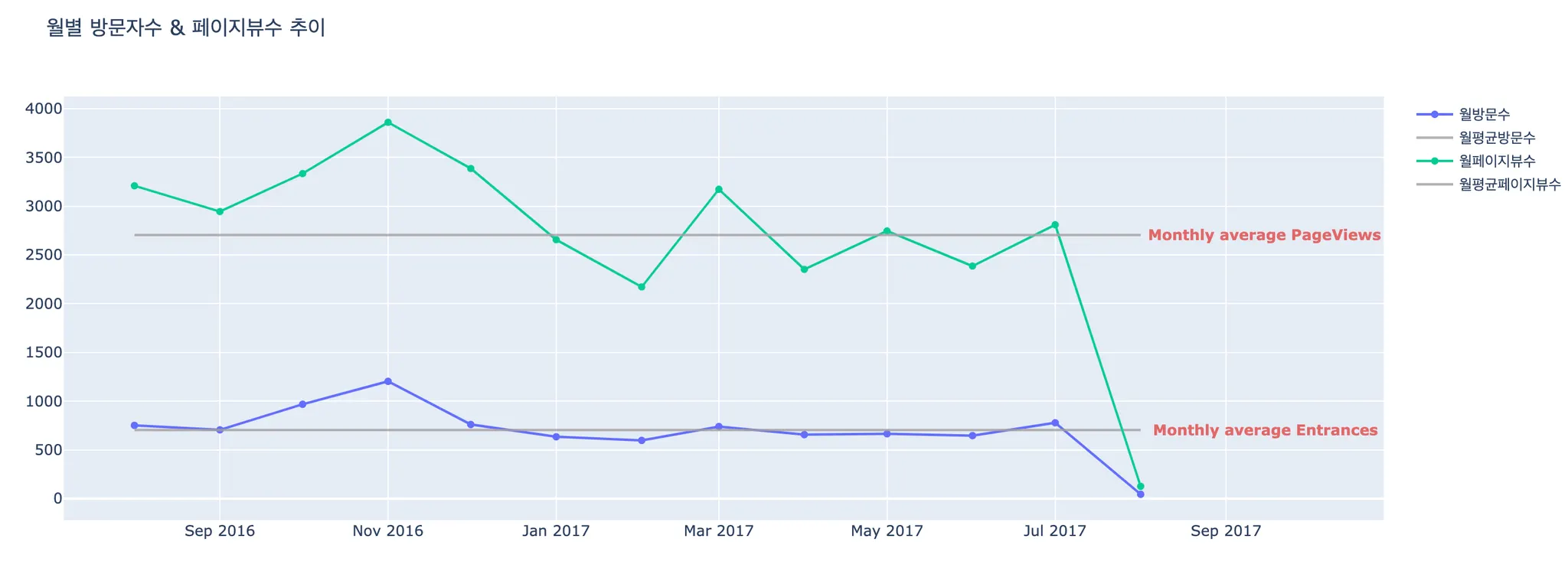
2.
MAU
월간 기준으로 웹사이트를 방문한 사용자 중 적어도 한 번 이상 상호작용한 사용자수를 나타낸다.
→ 상호작용이란?
Hit와 관련된 값들인데, 페이지뷰, 이벤트, 전자상거래 등을 모두 포함한다.
이때, 중요한 점은 Active User 에서 ‘Active’(상호작용) 를 어떤 기준으로 세울 것인가 하는 부분이다.
GA 의 경우, hits 관련한 필드에는 대표적으로 아래 정보가 있는데,
- hits.eCommerceAction : 이커머스 활동과 관련된 모든 hit 정보
- hits.isInteraction : 해당 hit이 interaction일 경우, True.
hits.isInteraction 을 계산 편의상 사용하기로 했다.
순서
•
브라우저별 transaction 비율
%%bigquery --project majestic-gizmo-390314
SELECT
device.browser,
SUM ( totals.transactions ) / (SELECT SUM(totals.transactions) FROM GA_for_eda.ga_sample10) AS total_trans_rate
FROM GA_for_eda.ga_sample10
GROUP BY
device.browser
ORDER BY
total_trans_rate DESC
Python
복사
•
사용자 유형
신규유저, 재방문자의 비율을 확인해볼 수 있습니다.
◦
월별 새 사용자 비율
%%bigquery --project majestic-gizmo-390314
SELECT
FROM GA_for_eda.ga_sample10
GROUP BY
Python
복사
4-3. 페이지뷰 수
총페이지뷰수
웹사이트의 매력도를 파악할 수 있고, 추가적인 세부 분석을 진행하기에 앞서 흐름을 파악할 수 있음.
페이지별 유입량에 따른 매력도를 확인할 수 있으며, 어떤 시간대에 페이지로 자주 유입되는지도 파악해볼 수 있다.
페이지뷰수
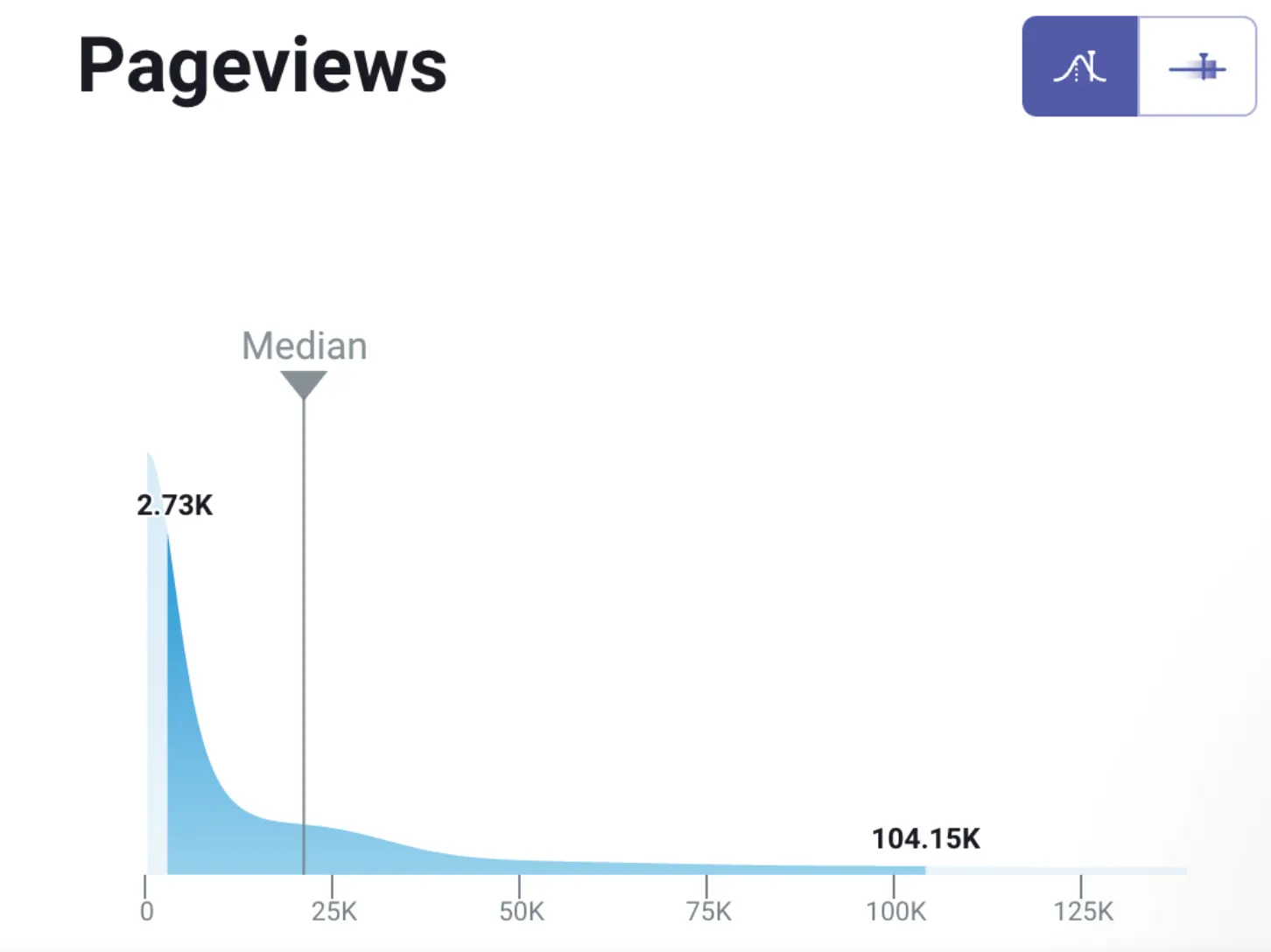
페이지뷰수를 계산하는 일반적인 방법 및 BenchMark
세션당 고객의 평균 구매수
%%bigquery --project majestic-gizmo-390314
SELECT
( SUM(total_transactionrevenue_per_user) / SUM(total_visits_per_user) ) AS
avg_revenue_by_user_per_visit
FROM (
SELECT
fullVisitorId,
SUM( totals.visits ) AS total_visits_per_user,
SUM( totals.transactionRevenue ) AS total_transactionrevenue_per_user
FROM GA_for_eda.ga_sample10
WHERE totals.visits > 0
AND totals.transactions >= 1
AND totals.transactionRevenue IS NOT NULL
GROUP BY
fullVisitorId)
Python
복사
이탈률 & 종료율
이탈률 해당 페이지로 유입되어 다른 페이지를 방문하지 않고 바로 나가는 비율
종료율 앞서 어떤 페이지를 보고 이동했는지에 상관 없이, 해당 페이지에서 사이트 방문 자체가 종료된 비율
•
이탈률
◦
유입 소스별 이탈률
%%bigquery --project majestic-gizmo-390314
SELECT
source,
total_visits,
total_no_of_bounces,
( ( total_no_of_bounces / total_visits ) * 100 ) AS bounce_rate
FROM (
SELECT
trafficSource.source AS source,
COUNT ( trafficSource.source ) AS total_visits,
SUM ( totals.bounces ) AS total_no_of_bounces
FROM GA_for_eda.ga_sample10
GROUP BY
source )
ORDER BY
total_visits DESC
Python
복사
•
전환율 / 재방문자 전환율
•
유입 키워드
유입에 기여한 키워드를 확인해볼 수 있습니다.
•
가장 애용되는 페이지, 각 페이지별 이탈률
SELECT
hits.page.pagePath AS landing_page, -- 페이지의 url path
COUNT(*) AS views,
SUM(totals.bounces)/COUNT(*) AS bounce_rate -- 페이지별 이탈률
FROM GA_for_eda.ga_sample10,
UNNEST(hits) AS hits
WHERE hits.type='PAGE' -- 이벤트 타입 : page
AND
hits.hitNumber=1 -- 세션의 첫 hit
GROUP BY landing_page
ORDER BY views DESC
LIMIT 10
Python
복사

→ ‘이탈률’이 특정 사이트에 방문한 사용자가 다른 페이지로 이동하지 않고 떠난 비율을 가리킨다면, ‘종료율’은 특정 사이트에서 고객이 여러 개의 페이지를 이동한 뒤 사이트를 떠난 비율을 말한다.