네이버 개발자 Document 에서는 네이버 검색 기능에 대해 Open API 서비스를 제공하고 있다.
아래는 Python 에서 활용할 수 있는 코드를 직접적으로 제공해준 것이다.
# 네이버 검색 API 예제 - '블로그 검색'
import os
import sys
import urllib.request
client_id = "4omsiCD4L2V8zrVCumOq" -- 서비스 API 를 요청하면 아이디와
client_secret = "0Toygo8jG_" -- 비밀번호를 제공해준다.
encText = urllib.parse.quote("파이썬")
url = "https://openapi.naver.com/v1/search/blog?query=" + encText # JSON 결과
# url = "https://openapi.naver.com/v1/search/blog.xml?query=" + encText # XML 결과
request = urllib.request.Request(url) # 요청하고
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
response = urllib.request.urlopen(request) # 요청받은 페이지를 받아오고
rescode = response.getcode() #정상적으로 받아왔는지 확인, (=status, code)
if(rescode==200):
response_body = response.read()
print(response_body.decode('utf-8'))
else:
print("Error Code:" + rescode)
Python
복사
 urllib.parse.quote
urllib.parse.quote 아스키코드 형식이 아닌 글자를 url 인코딩 시켜준다.
•
들어갈 수 있는 인자에는 string, bytes 형식이 들어간다.
요즘 장마철이고..비도 많이 와서 개인적으로 구매하고픈 ‘헌터 부츠’ 에 대해 쇼핑 검색 데이터를 뽑아보기로 했다.
# 네이버 검색 API 예제 - '헌터 부츠' 검색 (쇼핑)
import os
import sys
import urllib.request
client_id = "4omsiCD4L2V8zrVCumOq"
client_secret = "0Toygo8jG_"
encText = urllib.parse.quote("헌터부츠")
url = "https://openapi.naver.com/v1/search/shop?query=" + encText # JSON 결과
# url = "https://openapi.naver.com/v1/search/blog.xml?query=" + encText # XML 결과
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
response = urllib.request.urlopen(request)
rescode = response.getcode()
if(rescode==200):
response_body = response.read()
print(response_body.decode('utf-8'))
else:
print("Error Code:" + rescode)
Python
복사
물론, 위의 Open API 서비스를 사용해서 가져올 수도 있지만, 수동으로 비슷하게 구현해보기로 한다.
필요한 함수들을 만들어줘야 하는데,
1. 검색 search url 뽑아오기
2. 데이터 읽어오기
3. 필요한 데이터만 파싱해서 데이터프레임으로 만들어주기
4. 불필요한 태그 없애주기
5. 각각의 데이터프레임 합쳐주기(concat)
위의 함수들을 만들어주고 실행한 다음, 엑셀에 데이터를 저장하는 방법에 대해서도 실습한다.
6. pd.ExcelWriter 사용하기
7. 간단한 countplot 시각화
(1) 검색 url 만들어내기 : gen_search_url()
# api_node: 네이버 검색 url 중 '쇼핑','사전','책' 등의 카테고리를 담을 node
# search_text : 내가 검색할 상품 이름
# start_num : 검색 시작 위치(기본값 : 1, 최댓값 : 1000)
# disp_num : 한번에 표시할 검색 결과 개수(기본값 : 10, 최댓값 : 100)
def gen_search_url(api_node, search_text, start_num, disp_num):
base = "https://openapi.naver.com/v1/search"
node = "/" + api_node + '.json' # json 데이터 형식이므로
param_query = "?query=" + urllib.parse.quote(search_text)
param_start = "&start=" + str(start_num)
param_disp = "&display=" + str(disp_num)
return base + node + param_query + param_start + param_disp
Python
복사
gen_search_url('shop', '헌터부츠', 10, 3)
Python
복사
결과 : 'https://openapi.naver.com/v1/search/shop.json?query=%ED%97%8C%ED%84%B0%EB%B6%80%EC%B8%A0&start=10&disp=3’
(2) 검색 데이터 읽어오기 : get_result_onepage
import json
import datetime
def get_result_onepage(url):
request = urllib.request.Request(url) # 위에서 생성한 url 이 인자로 들어간다.
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
response = urllib.request.urlopen(request)
print("[%s] Url Request Success" % datetime.datetime.now())
return json.loads(response.read().decode('utf-8'))
Python
복사
url = gen_search_url('shop','헌터부츠',1,5)
one_result = get_result_onepage(url)
one_result
Python
복사
결과는 json 형식으로 잘 읽어들인 것을 확인할 수 있을 것이다.
(3) 필요한 데이터만 파싱해 데이터프레임 만들기 : get_fields()
import pandas as pd
def get_fields(json_data): # 위에서 만든 one_result 가 인자로 들어간다.
title = [each['title'] for each in json_data['items']]
link = [each['link'] for each in json_data['items']]
price = [each['lprice'] for each in json_data['items']]
mall_name = [each['mallName'] for each in json_data['items']]
result_pd = pd.DataFrame({
"title": title,
"link": link,
"price": price,
"mall": mall_name,
}, columns=['title','price','link','mall'])
return result_pd
Python
복사
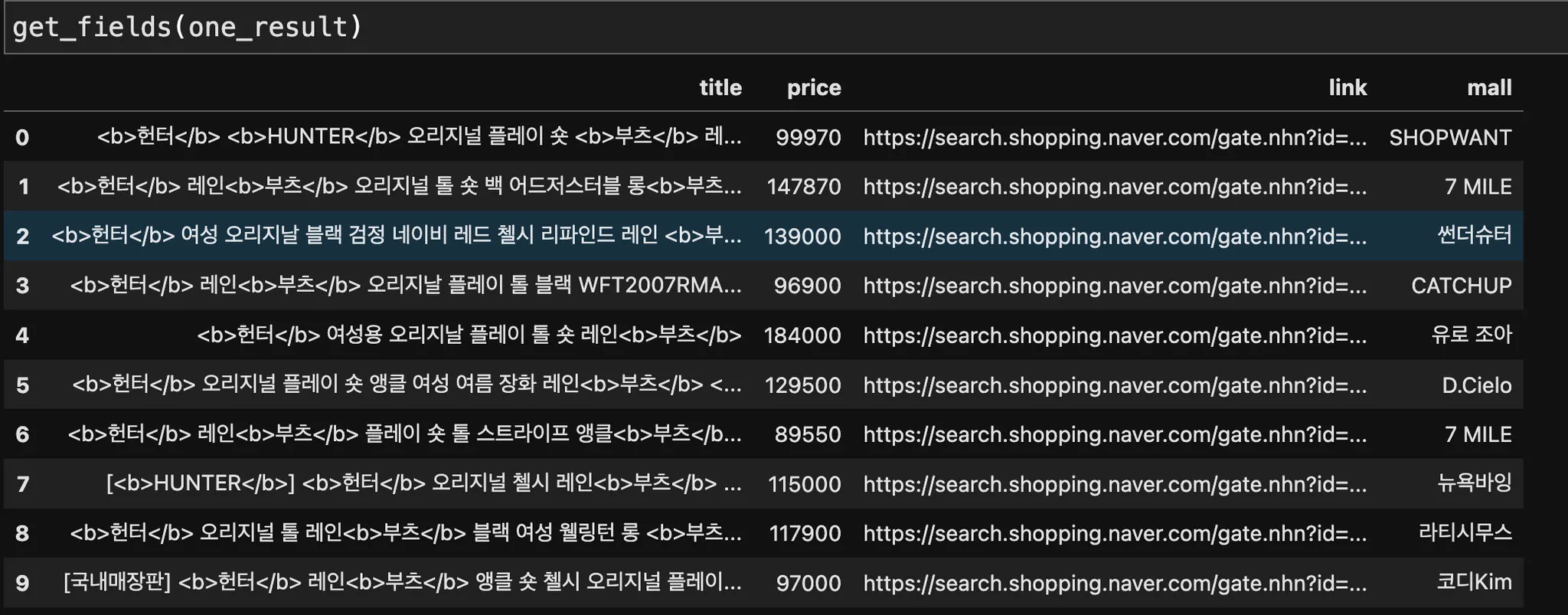
(4) title 필드의 <b></b> 태그 없애주기 : delete_tag()
def delete_tag(input_str):
input_str = input_str.replace('<b>' ,'')
input_str = input_str.replace('</b>' ,'')
return input_str
Python
복사
import pandas as pd
def get_fields(json_data):
title = [delete_tag(each['title']) for each in json_data['items']]
link = [each['link'] for each in json_data['items']]
price = [each['lprice'] for each in json_data['items']]
mall_name = [each['mallName'] for each in json_data['items']]
result_pd = pd.DataFrame({
"title": title,
"link": link,
"price": price,
"mall": mall_name,
}, columns=['title','price','link','mall'])
return result_pd
Python
복사
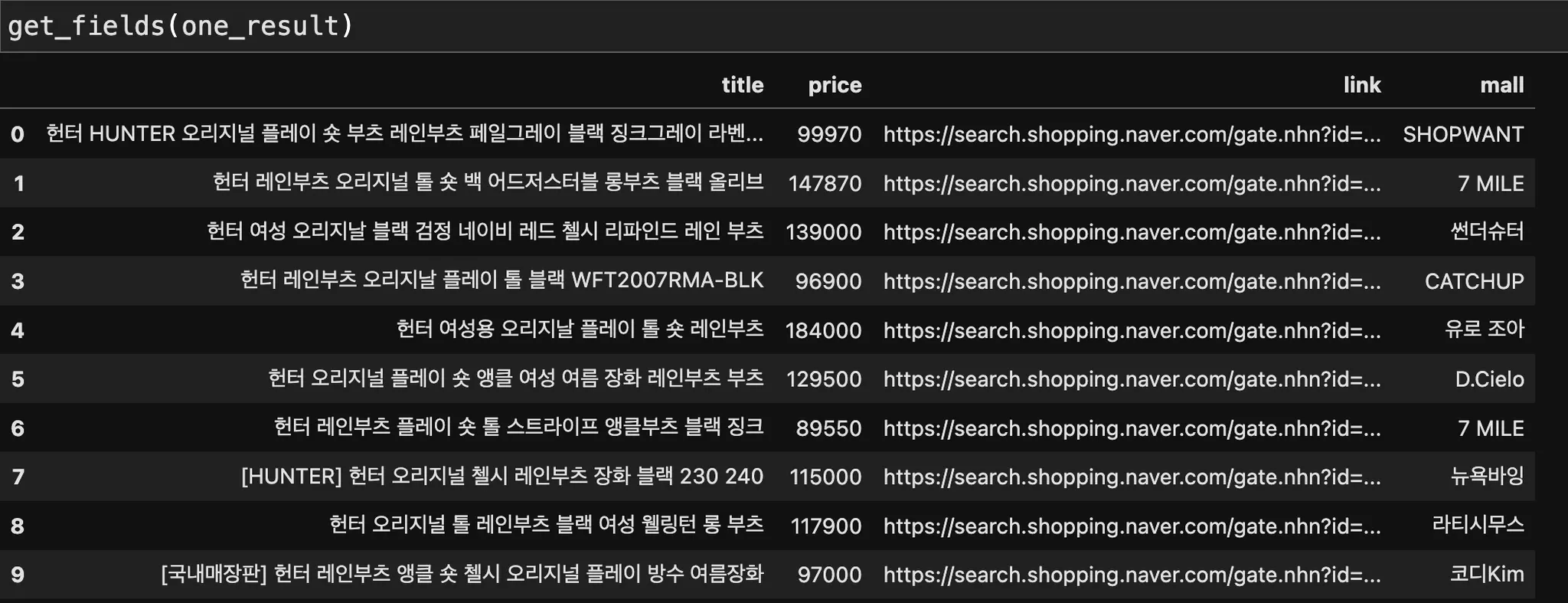
(5) 위의 함수를 사용해서 간단하게 API 사용, 데이터프레임 형성, concat 까지 수행하기
result_mol = []
for n in range(1,1000,100): # 총 1 ~ 1000까지의 검색 결과 위치를 스크래핑해오고 싶다면
url = gen_search_url('shop','헌터부츠', n, 100)
json_result = get_result_onepage(url)
pd_result = get_fields(json_result)
result_mol.append(pd_result)
result_mol = pd.concat(result_mol)
Python
복사
result_mol.reset_index(drop=True, inplace=True)
result_mol['price'] = result_mol['price'].astype('float')
Python
복사
(6) 엑셀파일에 저장해주기
•
pd.ExcelWriter
엑셀의 여러 시트에 데이터를 적용해주고자 할때 일반적으로 활용된다.
또는, 기존의 파일에 새 시트만 추가하여 저장하고자 할때 사용된다.
•
파이썬에서 엑셀의 형식, 스타일 지정해주기
writer = pd.ExcelWriter('../data/06_hunter_boots_in_naver_shop.xlsx', engine='xlsxwriter')
result_mol.to_excel(writer, sheet_name='Sheet1')
workbook = writer.book
worksheet = writer.sheets['Sheet1']
worksheet.set_column("A:A", 4) # 컬럼별 공간 크기 지정
worksheet.set_column("B:B", 60)
worksheet.set_column("C:C", 10)
worksheet.set_column("D:D", 10)
worksheet.set_column("E:E", 50)
worksheet.set_column("F:F", 10)
worksheet.conditional_format('C2:C1001', {'type': '3_color_scale'})
writer.save()
Python
복사
간단한 countplot 으로 시각화
import set_matplotlib_hangul
import matplotlib.pyplot as plt
import seaborn as sns
plt.figure(figsize=(15,6))
sns.countplot(
x = result_mol['mall'], # x = 를 꼭 넣어줘야 한다.
data=result_mol,
palette='RdYlGn',
order=result_mol['mall'].value_counts().index[:10]
)
plt.xticks(rotation=90)
plt.show()
Python
복사
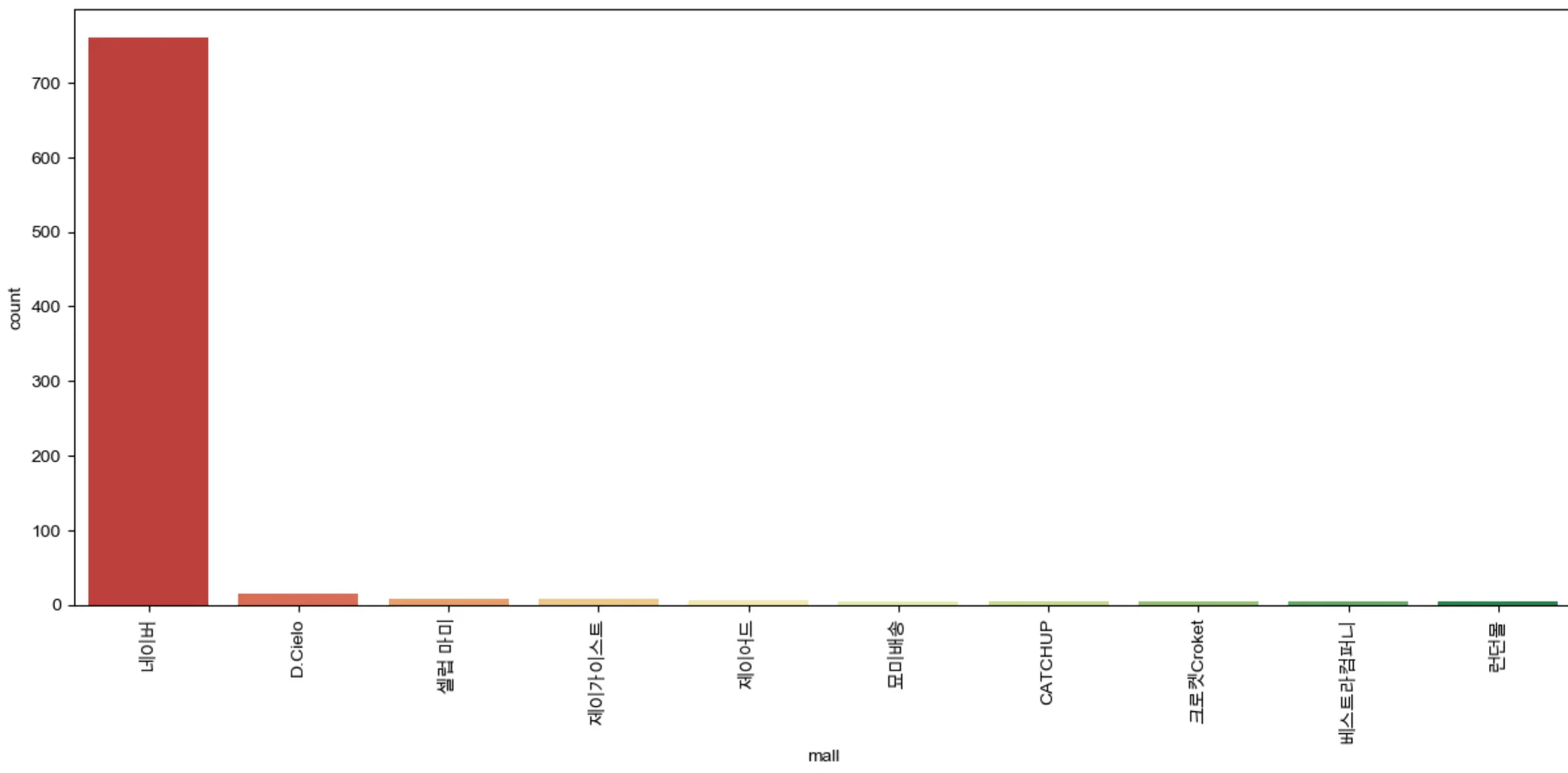
‘헌터 부츠’와 관련된 상품 마켓은 네이버 쇼핑이 압도적인 것을 확인할 수 있다.