
먼저, Matplotlib는 파이썬 표준 시각화 도구라고 부를 수 있을 정도로 2D 평면 그래프에 관한 다양한 포맷과 기능을 지원한다. 객체지향 프로그래밍을 지원하므로 그래프 요소를 세세하게 꾸밀 수 있다.
1-1. 선 그래프
선 그래프는 연속하는 데이터 값들을 직선 또는 곡선으로 연결하여 데이터 값 사이의 관계를 나타낸다. 특히, 시계열 데이터와 같이 연속적인 값의 변화와 패턴을 파악하는데 적합하다.
통계청에서 제공하는 시도 간 인구 이동 데이터셋을 이용하여 선 그래프를 그려보자.
~ 기본 사용법
matplotlib.pyplot 모듈을 “as plt” 와 같이 약칭 plt로 임포트한다.
# 라이브러리 불러오기
import pandas as pd
import matplotlib.pyplot as plt
# excel 데이터를 데이터프레임으로 가져오기
df = pd.read_excel("시도별 전출입 인구수.xlsx", engine='openpyxl', header=0) # 첫행이 변수가 될 것
df.head()
Out[5]:
전출지별 전입지별 1970 1971 ... 2014 2015 2016 2017
0 전출지별 전입지별 이동자수 (명) 이동자수 (명) ... 이동자수 (명) 이동자수 (명) 이동자수 (명) 이동자수 (명)
1 전국 전국 4046536 4210164 ... 7629098 7755286 7378430 7154226
2 NaN 서울특별시 1742813 1671705 ... 1573594 1589431 1515602 1472937
3 NaN 부산광역시 448577 389797 ... 485710 507031 459015 439073
4 NaN 대구광역시 - - ... 350213 351424 328228 321182
[5 rows x 50 columns]
Python
복사
데이터프레임으로 가져온 데이터의 구조를 살펴보면 맨 먼저 ‘전출지별’ 열의 값들이 NaN이 확인된다. 이때 이 NaN들은 실제로 누락값이 아니라 엑셀에서 데이터프레임으로 가져올 때 구조 변환때문에 어쩔 수 없이 생긴 것들이다. fillna() 메소드의 method=’ffill’ 옵션을 사용하면 누락데이터가 들어있는 행의 바로 앞에 위치한 행의 데이터 값으로 채운다. 예를들어, 2행의 NaN 값을 앞의 ‘전국’ 으로 대체하는 방식이다.
그 다음, ‘전출지별’ 열에서 ‘서울특별시’의 값을 갖는 데이터들만 따로 뽑아서 변수 df_seoul에 저장한다. 그렇게 하면 그 데이터들은 서울에서 다른 지역으로 전출하는 데이터만 갖게 된다.
또, ‘전입지별’ 의 열의 이름을 ‘전입지’로 바꾸고, ‘전입지’열을 df_seoul의 행 인덱스로 지정한다. 그렇게 하면 전입지를 기준으로 데이터를 선택할 수 있게 된다.
# 누락값 NaN을 앞 데이터로 채운다. (fillna 메소드 사용)
df = df.fillna(method='ffill') # 앞의 행 값을 가져와서 채움
# 서울에서 다른 지역으로 이동한 데이터만 추출하여 정리
mask = (df['전출지별'] == '서울특별시') & (df['전입지별'] != '서울특별시') # 인덱스가 추출됨
df_seoul = df[mask]
df_seoul = df_seoul.drop(['전출지별'], axis=1) # 열 제거하기
df_seoul.rename({'전입지별':'전입지'}, axis=1, inplace=True) # 열 이름 바꾸기
df_seoul.set_index('전입지', inplace=True) # 행 인덱스 지정하기
df_seoul
1970 1971 1972 1973 ... 2014 2015 2016 2017
전입지 ...
전국 1448985 1419016 1210559 1647268 ... 1661425 1726687 1655859 1571423
부산광역시 11568 11130 11768 16307 ... 17320 17009 15062 14484
대구광역시 - - - - ... 10062 10191 9623 8891
인천광역시 - - - - ... 43212 44915 43745 40485
광주광역시 - - - - ... 9759 9216 8354 7932
대전광역시 - - - - ... 13403 13453 12619 11815
울산광역시 - - - - ... 6047 5950 5102 4260
세종특별자치시 - - - - ... 6481 7550 5943 5813
경기도 130149 150313 93333 143234 ... 332785 359337 370760 342433
강원도 9352 12885 13561 16481 ... 21173 22659 21590 21016
충청북도 6700 9457 10853 12617 ... 14244 14379 14087 13302
충청남도 15954 18943 23406 27139 ... 21473 22299 21741 21020
전라북도 10814 13192 16583 18642 ... 14566 14835 13835 13179
전라남도 10513 16755 20157 22160 ... 14591 14598 13065 12426
경상북도 11868 16459 22073 27531 ... 14456 15113 14236 12464
경상남도 8409 10001 11263 15193 ... 14799 15220 13717 12692
제주특별자치도 1039 1325 1617 2456 ... 9031 10434 10465 10404
[17 rows x 48 columns]
# df_seoul에서 '전입지'가 '경기도'인 행데이터를 선택하여 sr_one에 저장
sr_one = df_seoul.loc['경기도'] # 행을 선택할때는 iloc이나 loc 사용
sr_one.head()
Out[22]:
1970 130149
1971 150313
1972 93333
1973 143234
1974 149045
Name: 경기도, dtype: object
Python
복사
본격적으로 선 그래프를 그릴텐데 plot 함수에 입력할 x, y 축 데이터를먼저 선택한다. sr_one은 시리즈객체이므로 x축 데이터로 인덱스를 지정하고 y축 데이터로 데이터 값을 지정한다.
# x, y축 데이터를 plot함수에 입력
plt.plot(sr_one.index, sr_one.values)
# 물론, 시리즈 또는 데이터프레임 객체를 plot함수에 직접 입력하는 것도 가능하다.
plt.plot(sr_one) # 결과는 위와 같다.
Python
복사
~ 차트 제목, 축 이름 추가
차트 제목을 추가할 때는 title() 함수를 사용한다. x축 이름은 xlabel() 함수를 이용하고, y축 이름은 ylabel() 함수를 활용하여 추가한다.
# 한글 폰트 사용을 위해서 세팅
import matplotlib
matplotlib.rcParams['font.family']='Malgun Gothic'
matplotlib.rcParams['axes.unicode_minus']=False
# 위의 방식 아니면 아래 방식
from matplotlib import font_manager, rc
font_path = "./malgun.ttf" # 폰트 파일 위치, 파이썬 파일과 같은 폴더에 저장 또는 윈도우/폰트 경로에 저장
font_name = font_manager.FontProperties(fname=font_path).get_name()
rc('font',family=font_name)
# 차트 제목, 축 이름 추가
# 차트 제목은 title() 함수, x축 이름는 xlabel(), y축 이름은 ylabel() 로 한다.
# 서울에서 경기도로 이동한 인구 데이터 값만 선택
sr_one
# x, y축 데이터를 plot함수에 입력
plt.plot(sr_one.index, sr_one.values)
#차트 제목 추가
plt.title('서울 --> 경기 인구 이동')
#축 이름 추가
plt.xlabel('기간')
plt.ylabel('이동 인구수')
plt.show() # 변경 사항 저장하고 그래프 출력
Python
복사
~ 그래프 꾸미기
x축 눈금 라벨의 글씨가 서로 겹쳐 잘 보이지 않는 문제를 해결하는 방법을 알아보자. 이는 눈금 라벨이 들어갈 만한 충분한 여유 공간이 없어서 발생하는 문제다.
다음은 글씨가 들어갈 수 있는 공간을 확보하기 위해 두 가지 방법을 적용한다. 첫째, 공간을 만들기 위해 figure() 함수로 그림틀의 가로 사이즈를 더 크게 설정한다.
둘째, xticks()함수를 활용하여 x축 눈금 라벨을 반시계 방향으로 90도 회전하여 글씨가 서로 겹치지 않게 만든다.
•
기본 사용 : plt.plot(x,y,’bo’) —> ‘bo’ 는 파란색의 원형 마커로 표시(산점도)
•
선/ 마커 동시에 나타내기 : plt.plot(x,y,’bo-’) 또는 plt.plot(x,y,’bo--’) —> 파란색 원형 마커와 실선 또는 파란색 원형 마커와 점선
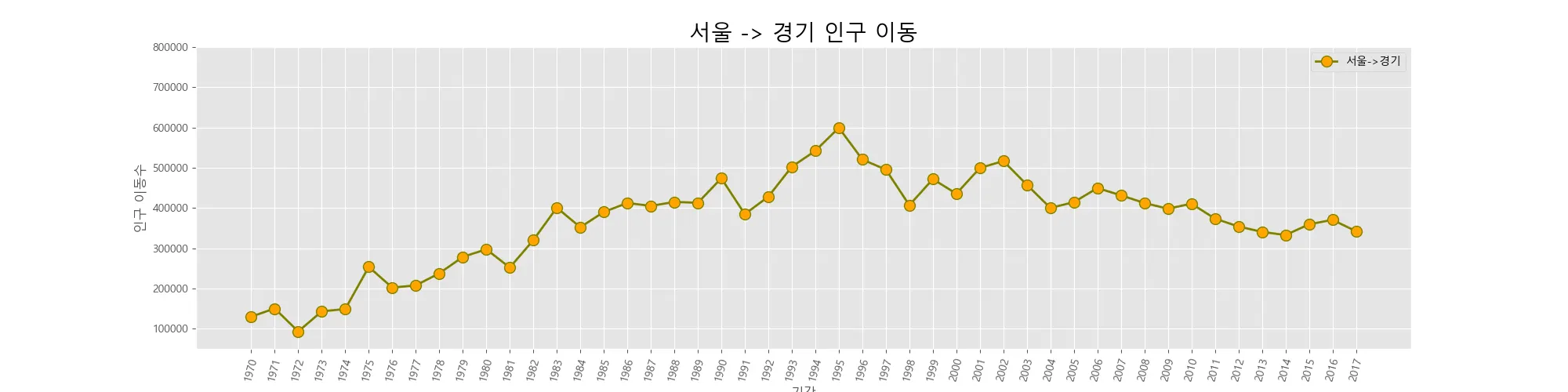
# 서울에서 경기도로 이동한 인구 데이터 값만 선택
sr_one = df_seoul.loc['경기도']
# 그림 사이즈 지정(가로 14인치, 세로 5인치)
plt.figure(figsize=(14,5))
# x축 눈금 라벨 회전하기
plt.xticks(rotation='vertical') # 반시계 방향으로 90도 회전, 90으로 입력해도 같음
# x, y축 데이터를 plot 함수에 입력
plt.plot(sr_one.index, sr_one.values)
plt.title('서울 --> 경기 인구 이동') # 차트 제목
plt.xlabel('기간') # x축 이름
plt.ylabel('이동 인구수') # y축 이름
plt.legend(labels=['서울-->경기'],loc='best') # 범례 표시
plt.show() # 변경사항 저장하고 그래프 출력
Python
복사
plt.xticks(rotation=90) # 는 plt.xticks(rotation='vertical') 와 같음
Python
복사
다음은 Matplotlib의 스타일 서식 지정에 대해 알아보겠다. 색, 폰트 등 디자인적 요소를 사전에 지정된 스타일로 빠르게 일괄 변경한다. 단, 스타일 서식을 지정하는 것은 Matplotlib 실행 환경 설정을 변경하는 것이므로 다른 파일을 실행할때도 계속 적용된다는 점에 유의해야 한다.
# 스타일 서식 지정
plt.style.use('ggplot') # ggplot이라는 스타일 서식을 지정
# 그림 사이즈 지정
plt.figure(figsize=(14,5))
# x축 눈금 라벨 회전하기
plt.xticks(size=10, rotation='vertical')
# x축, y축 데이터를 plot 함수에 입력
plt.plot(sr_one.index,sr_one.values, marker='o',markersize=10) # 마커 표시 추가
plt.title('서울 --> 경기 인구 이동', size=30) # 차트 제목
plt.xlabel('기간', size=20) # x축 이름
plt.ylabel('이동 인구수', size=20) # y축 이름
plt.legend(labels=['서울-->경기'], loc='best', fontsize=15) # 범례 표시
plt.show()
Python
복사
 선/ 마커 표시 형식
선/ 마커 표시 형식
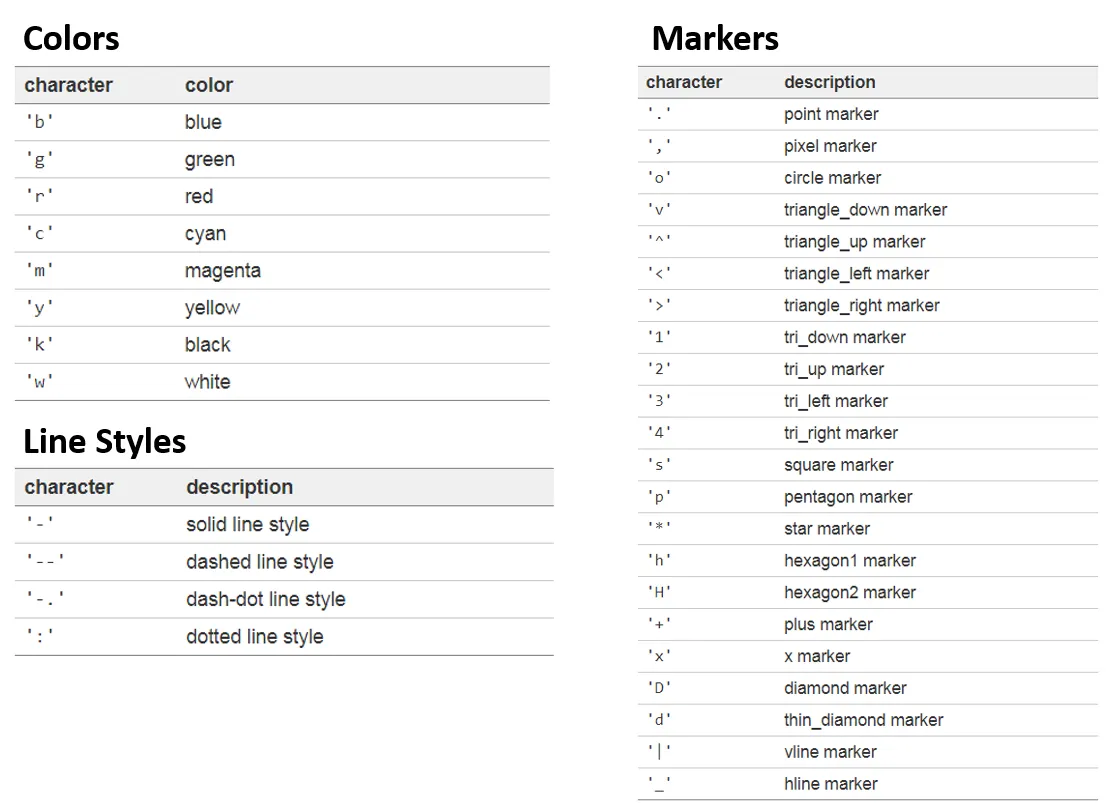 Matplotlib 내 marker 종류 (plt.plot(x,y,marker=?) )
Matplotlib 내 marker 종류 (plt.plot(x,y,marker=?) )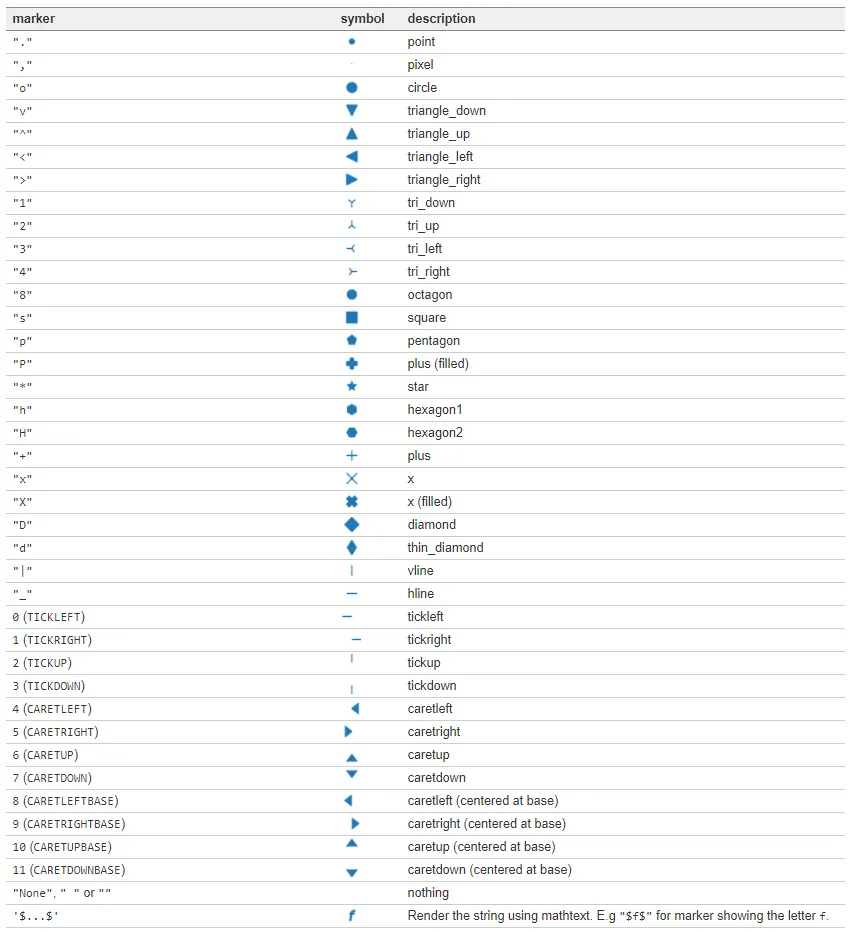 Matplotlib 스타일 서식의 종류
Matplotlib 스타일 서식의 종류‘ggplot’외에도 많은 종류의 스타일 서식이 지원된다.
•
스타일의 종류 : ‘classic’,’bmh’,’dark_background’,’fast’,’grayscale’,’seaborn’ 등
현재 실행환경에서 사용 가능한 Matplotlib의 스타일 옵션을 확인할 수 있다. 기본 디폴트 상태로 돌아가려면 스파이더(IDE)를 다시 실행한다.
# Matplotlib 스타일 리스트 출력
# 라이브러리 불러오기
import matplotlib.pyplot as plt
# 스타일 리스트 출력
print(plt.style.available)
['Solarize_Light2', '_classic_test_patch', '_mpl-gallery', '_mpl-gallery-nogrid', 'bmh', 'classic', 'dark_background', 'fast', 'fivethirtyeight', 'ggplot', 'grayscale', 'seaborn', 'seaborn-bright', 'seaborn-colorblind', 'seaborn-dark', 'seaborn-dark-palette', 'seaborn-darkgrid', 'seaborn-deep', 'seaborn-muted', 'seaborn-notebook', 'seaborn-paper', 'seaborn-pastel', 'seaborn-poster', 'seaborn-talk', 'seaborn-ticks', 'seaborn-white', 'seaborn-whitegrid', 'tableau-colorblind10']
Python
복사
~ 그래프에 주석 붙이기
그래프에 대한 설명을 덧붙이는 주석에 대해 알아보자. annotate() 함수를 사용한다. 주석 내용을 넣을 위치와 정렬 방법 등을 annotate()함수에 함께 전달한다. arrowprops 옵션을 사용하면 텍스트 대신 화살표가 표시된다. 화살표 스타일, 시작점과 끝점의 좌표를 입력한다. annotate(s, xy) 의 형식이고 s=’주석내용’ , xy = 위치좌표 는 필수로 넣어줘야 한다.
주석을 넣을 여백 공간을 충분히 확보하기 위해서 ylim() 함수를 사용하여 y축 범위를 늘려준다.
annotate함수로 화살표와 텍스트 위치를 잡아서 배치한다. (x,y) 좌표에서 x값은 인덱스 번호를 사용한다. y 좌표값에 들어갈 인구수 데이터는 숫자값이므로 그대로 사용할 수 있다.
# y축 범위 지정(최소값, 최대값)
plt.ylim(50000,800000)
# 주석 표시 - 화살표를 나타내기
plt.annotate('',
xy = (20,620000) # 화살표의 끝점
xytext = (2,290000) # 화살표의 시작점
xycoords = 'data' # 좌표체계
arrowprops = dict(arrowstyle='->',color='skyblue',lw=5), # 화살표 서식
)
plt.annotate('',
xy = (47,450000),
xytext = (30,580000),
xycoords = 'data',
arrowprops = dict(arrowstyle='->',color='olive',lw=5),
)
# 주석 표시 - 텍스트
plt.annotate('인구 이동 증가(1970-1995)', # 텍스트 입력
xy = (10,550000), # 텍스트 위치 시작점
rotation = 25, # 텍스트 회전 각도
va = 'baseline', # 텍스트 상하 정렬
ha = 'center', # 텍스트 좌우 정렬
fontsize = 15, # 텍스트 크기
)
plt.annotate('인구 이동 감소(1995-2017)',
xy = (40,560000),
rotation = -11, # 시계 방향 11도 회전
va = 'baseline',
ha = 'center',
fontsize = 15,
)
plt.show() #변경 사항 저장하고 그래프 출력
Python
복사
~ 화면 분할하여 그래프 여러 개 그리기 - axe 객체 활용
화면을 여러 개로 분할하고 분할된 각 화면에 서로 다른 그래프를 그리는 방법이다. 여러 개의 axe 객체를 만들고, 분할된 화면마다 axe 객체를 하나씩 배정한다. axe 객체는 각각 서로 다른 그래프를 표현할 수 있다.
한 화면에서 여러 개의 그래프를 비교하거나 다양한 정보를 동시에 보여줄 때 사용하면 좋다.
1.
먼저 figure() 함수를 사용해서 그래프를 그리는 그림틀(fig, 객체)를 만든다. figsize 옵션으로 크기를 설정한다.
2.
fig객체에 add_subplot() 메소드를 적용해서 그림틀을 여러 개로 분할한다. 이때 나눠진 각 부분을 axe객체라고 부른다.
add_subplot(행의 개수, 열의 개수, 서브플롯 순서)
3.
각 axe객체에 plot()메소드를 적용해서 그래프를 출력한다.
4.
객체에 y축의 최소값, 최대값 한계를 설정하기 위해 set_ylim() 메소드를 사용한다.
5.
x축 눈금 라벨이 겹치지 않도록 set_xticklabels() 메소드를 사용하여 회전시킨다.
# 그래프 객체 생성(figure에 2개의 서브 플롯 생성)
fig = plt.figure(figsize=(10,10)) # 객체에 저장
ax1 = fig.add_subplot(2,1,1) # 2행 1열의 분할에서 1번째 부분을 나타냄
ax2 = fig.add_subplot(2,1,2)
# axe 객체에 plot함수로 그래프 출력
ax1.plot(sr_one,'o', markersize=10) # 선 대신 점으로만 표시
ax2.plot(sr_one,marker='o',markerfacecolor='green',markersize=10,
color='olive',linewidth=2, label='서울->경기') # 마커와 선 모두 표시, 라벨 지정
ax2.legend(loc='best') # 범례도 추가
# y축 범위 지정(최소값,최대값)
ax1.set_ylim(50000,800000)
ax2.set_ylim(50000,800000)
# 축 눈금 라벨 지정 및 75도 회전
ax1.set_xticklabels(sr_one.index, rotation=75)
ax2.set_xticklabels(sr_one.index, rotation=75)
plt.show()
Python
복사
선 그래프 꾸미기 옵션# 그래프 객체 생성(figure에 1개의 서브 플롯 생성)
fig = plt.figure(figsize=(20,5))
ax = fig.add_subplot(1,1,1)
# axe 객체에 plot함수로 그래프 출력
ax.plot(sr_one, marker='o', markerfacecolor='orange',markersize=10,
color='olive',linewidth=2,label='서울->경기')
ax.legend(loc='best')
# y축 범위 지정(최소값, 최대값)
ax.set_ylim(50000,800000)
# 차트 제목 추가
ax.set_title('서울 -> 경기 인구 이동', size=20)
# 축 이름 추가
ax.set_xlabel('기간',size=12)
ax.set_ylabel('인구 이동수', size=12)
# 축 눈금 라벨 지정 및 75도 회전
ax.set_xticklabels(sr_one.index,rotation=75)
# 축 눈금 라벨 크기
ax.tick_params(axis="x", labelsize=10)
ax.tick_params(axis="y", labelsize=10)
plt.show()
Python
복사
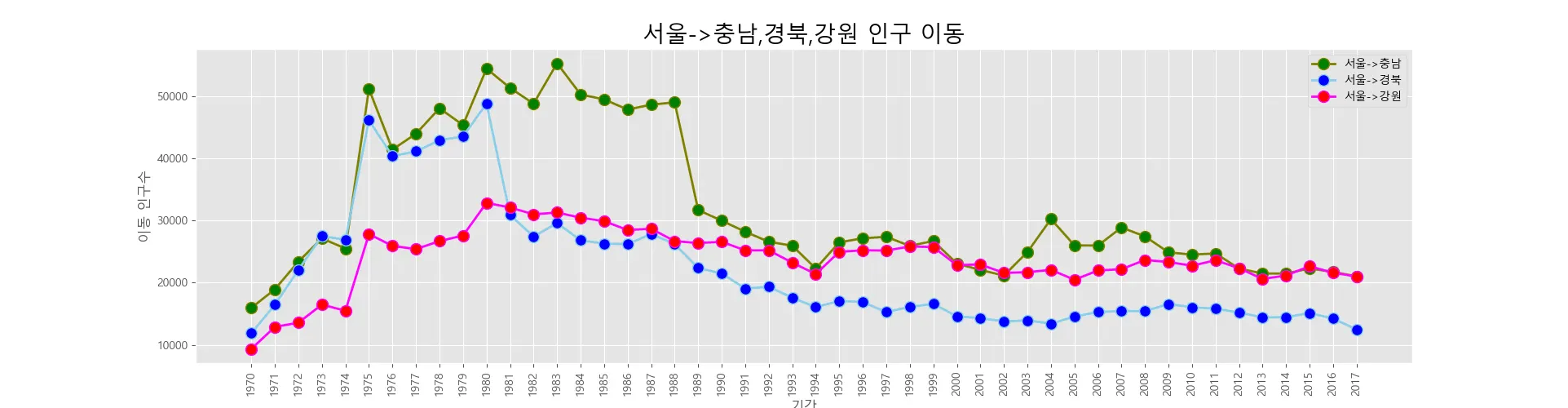
동일한 객체에 여러 개의 그래프를 추가하는 것도 가능하다. 서울특별시에서 충청남도, 경상북도, 강원도로 이동한 인구 변화 그래프 3개를 하나의 같은 화면에 그려본다.
각 지역에 해당하는 행을 선택하고, 동일한 axe객체에 선 그래프로 출력하는 plot()메소드를 3번 적용한다.
# 서울에서 '충청남도', '경상북도', '강원도'로 이동한 인구 데이터 값만 선택
col_years = list(map(str,range(1970,2018))) # 1970~2018의 숫자를 문자열로 변환하여 리스트로 반환
df_3 = df_seoul.loc[['충청남도','경상북도','강원도'],col_years]
# 스타일 서식 지정
plt.style.use('ggplot')
# 그래프 객체 생성(figure에 1개의 서브 플롯 생성)
fig = plt.figure(figsize=(20,5))
ax = fig.add_subplot(1,1,1)
# axe 객체에 plot함수로 그래프 출력
ax.plot(col_years, df_3.loc['충청남도',:],marker='o', markerfacecolor='green',markersize=10,color='olive',linewidth=2,label='서울->충남')
ax.plot(col_years, df_3.loc['경상북도',:],marker='o', markerfacecolor='blue', markersize=10,color='skyblue',linewidth=2,label='서울->경북')
ax.plot(col_years, df_3.loc['강원도',:],marker='o', markerfacecolor='red',markersize=10,color='magenta',linewidth=2, label='서울->강원')
# 범례 표시
ax.legend(loc='best')
# 차트 제목 추가
ax.set_title('서울->충남,경북,강원 인구 이동',size=20)
# 축 이름 추가
ax.set_xlabel('기간',size=12)
ax.set_ylabel('이동 인구수',size=12)
# 축 눈금 라벨 지정 및 90도 회전
ax.set_xticklabels(col_years,rotation=90)
# 축 눈금 라벨 크기
ax.tick_params(axis='x', labelsize=10)
ax.tick_params(axis='y', labelsize=10)
plt.show()
Python
복사
map(function, interable) : 첫 번째 매개변수로는 함수가 오고, 두 번째 매개변수로는 반복 가능한 자료형(리스트, 튜플 등)이 온다.
map함수의 반환 값은 map객체이기 때문에 해당 자료형을 list나 tuple로 형변환을 해줘야 한다.
동작은 두 번째 매개변수로 들어온 반복 가능한 자료형을 첫 번째 매개변수로 들어온 함수에 하나씩 집어넣어 함수를 수행하는 함수다.
즉, map(적용시킬 함수, 적용할 값들) 이라고 보면 된다.
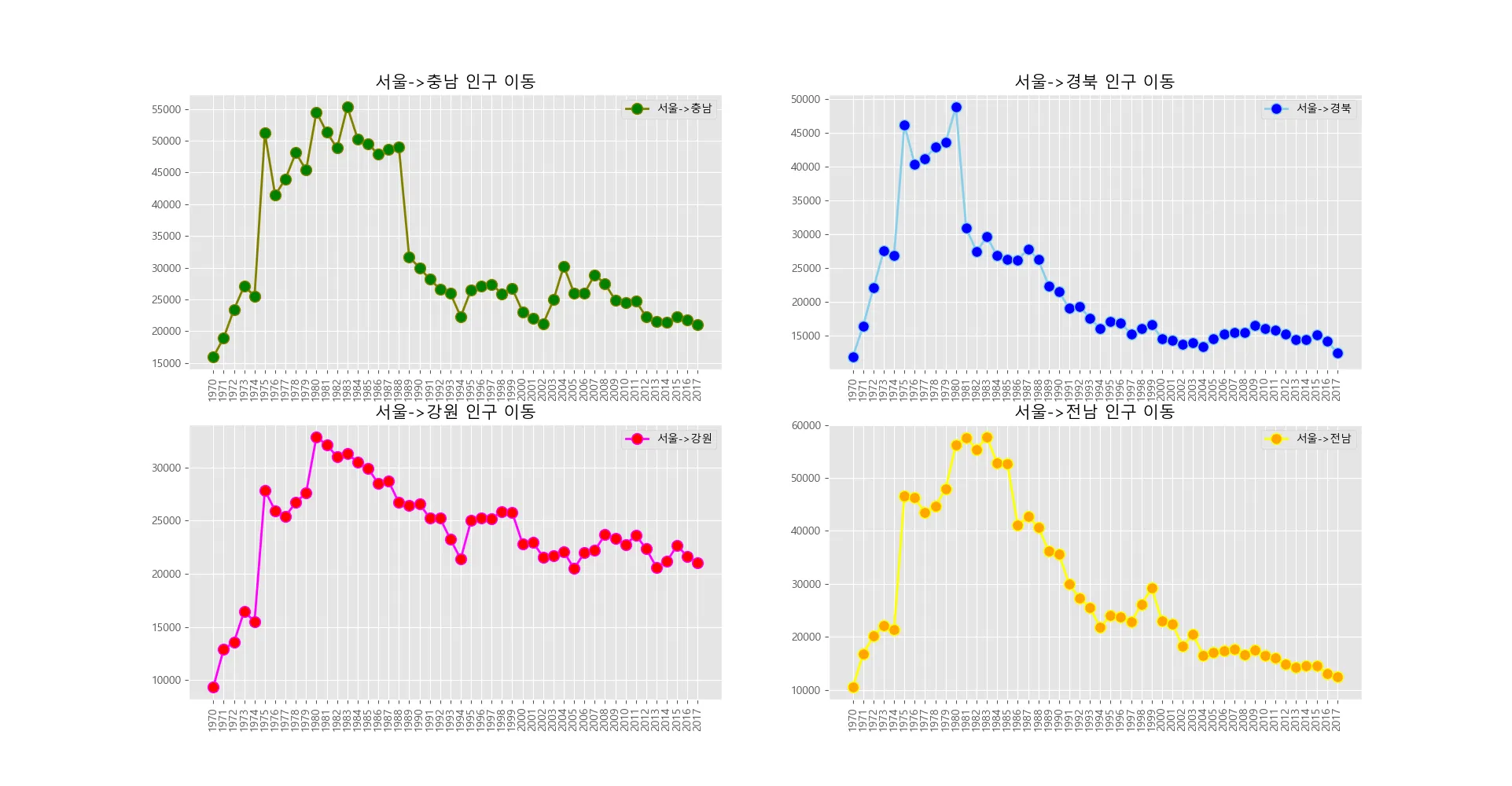
이번에는 서울특별시에서 충청남도, 경상북도, 강원도, 전라남도 4개 지역으로 이동한 인구 변화 그래프를 그려보겠다. ax1 ~ ax4까지 4개의 axe 객체를 생성한다.
각 지역에 해당하는 4개의 행을 선택하고, axe객체에 하나씩 plot() 메소드를 적용한다.
# 서울에서 '충청남도','경상북도','강원도','전라남도'로 이동한 인구 데이터 값만 선택
col_years = list(map(str,range(1970,2018)))
df_4 = df_seoul.loc[['충청남도','경상북도','강원도','전라남도'],col_years]
# 스타일 서식 지정
plt.style.use('ggplot')
# 그래프 객체 생성(figure에 4개의 서브 플롯 생성)
fig = plt.figure(figsize=(20,10)) # figure 사이즈 지정
ax1 = fig.add_subplot(2,2,1)
ax2 = fig.add_subplot(2,2,2)
ax3 = fig.add_subplot(2,2,3)
ax4 = fig.add_subplot(2,2,4)
# axe 객체에 plot함수로 그래프 출력
ax1.plot(col_years, df_4.loc['충청남도',:],marker='o',markerfacecolor='green',markersize=10,color='olive',linewidth=2,label='서울->충남')
ax2.plot(col_years, df_4.loc['경상북도',:],marker='o',markerfacecolor='blue',markersize=10,color='skyblue',linewidth=2,label='서울->경북')
ax3.plot(col_years, df_4.loc['강원도',:], marker='o', markerfacecolor='red',markersize=10, color='magenta',linewidth=2,label='서울->강원')
ax4.plot(col_years, df_4.loc['전라남도',:],marke='o', markerfacecolor='orange',markersize=10,color='yellow',linewidth=2,label='서울->전남')
# 범례 표시
ax1.legend(loc='best')
ax2.legend(loc='best')
ax3.legend(loc='best')
ax4.legend(loc='best')
# 차트 제목 추가
ax1.set_title('서울->충남 인구 이동',size=15)
ax2.set_title('서울->경북 인구 이동',size=15)
ax3.set_title('서울->강원 인구 이동',size=15)
ax4.set_title('서울->전남 인구 이동',size=15)
# 축 눈금 라벨 지정 및 90도 회전
ax1.set_xticklabels(col_years,rotation=90)
ax2.set_xticklabels(col_years,rotation=90)
ax3.set_xticklabels(col_years,rotation=90)
ax4.set_xticklabels(col_years,rotation=90)
plt.show()
Python
복사
 Matplotlib 라이브러리 내 사용할 수 있는 색상의 종류를 확인할 수 있다.
Matplotlib 라이브러리 내 사용할 수 있는 색상의 종류를 확인할 수 있다.import matplotlib
# 컬러 정보를 담을 빈 딕셔너리 생성
colors={}
# 컬러 이름과 헥사코드 확인하여 딕셔너리에 입력
for name, hex in matplotlib.colors.cnames.items():
colors[name] = hex
# 딕셔너리 출력
print(colors)
Python
복사
1-2. 면적 그래프
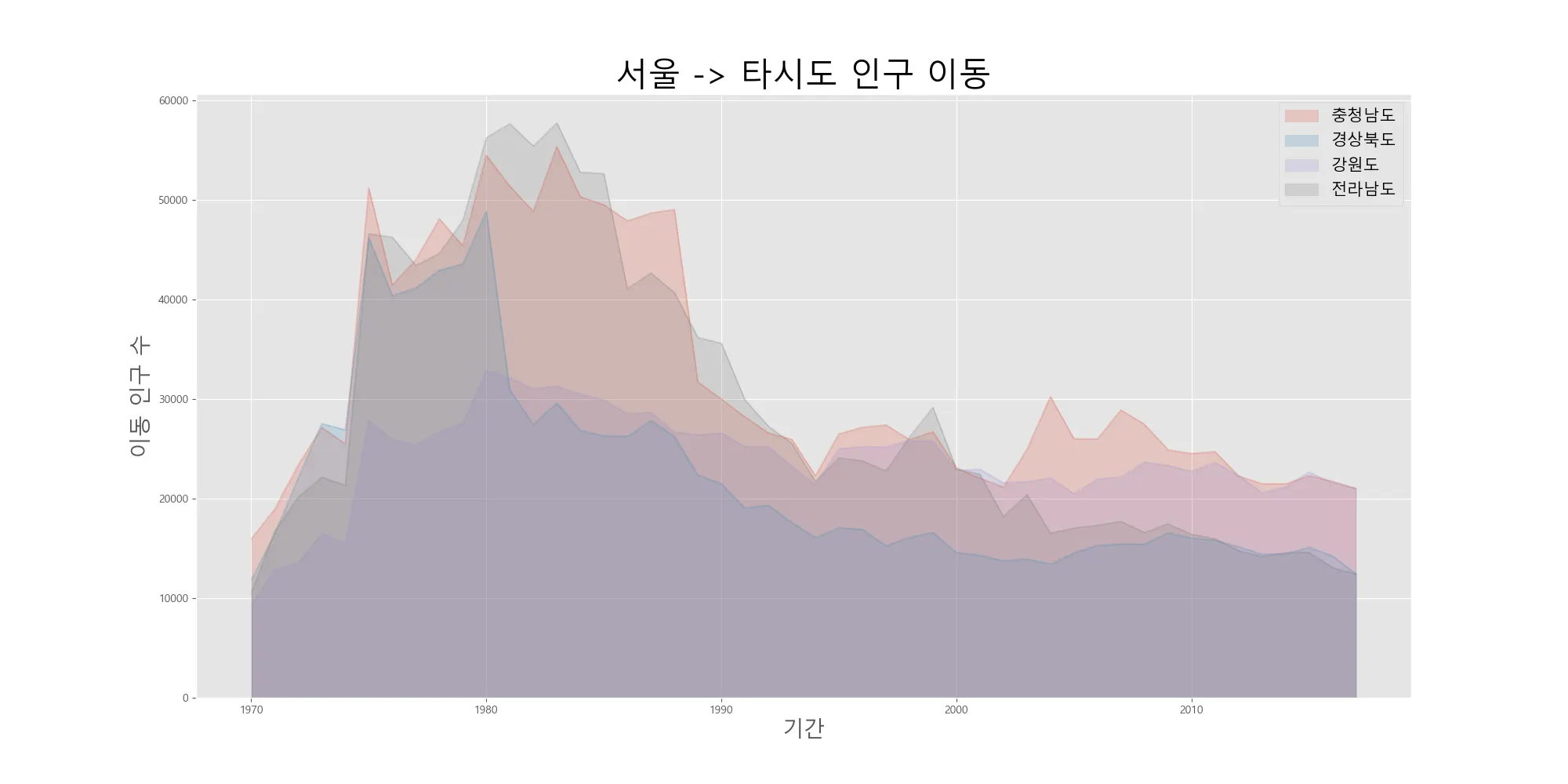
면적 그래프는 각 열의 데이터를 선 그래프로 구현하는데, x축과의 공간을 포함하여 그려진다. 투명도(alpha)는 기본값인 0.5로 주어지고 0~1사이의 값을 갖는다. 면적 그래프는 plot함수에 kind=’area’로 지정해주면 그릴 수 있다. 그래프를 누적할지의 여부를 설정할 수 있는데, stacked=True가 기본값이며 즉 각 열의 선 그래프를 다른 열의 선 그래프 위로 쌓아 올리는 방식이다. 이 방식으로 그래프를 그리면 각 열의 패턴과 함께 열 전체의 합계가 어떻게 변하는지 파악할 수 있다. 만약, stacked=False로 지정하면 각 열의 선 그래프들이 누적되지 않고 서로 겹치도록 표시된다.
먼저, stacked=False인 데이터를 누적하지 않은 그래프부터 살펴본다. 겹쳐지는 부분이 잘 투과되어 보이도록 투명도 alpha를 0.2 로 더욱 투명하게 지정한다.
# 서울에서 다른 지역으로 이동한 데이터만 추출하여 정리
mask = (df['전출지별']=='서울특별시')&(df['전입지별']!='서울특별시')
df_seoul = df[mask]
df_seoul = df_seoul.drop(['전출지별'],axis=1)
df_seoul.rename({'전입지별':'전입지'},axis=1,inplace=True)
df_seoul.set_index('전입지',inplace=True)
# 서울에서 '충청남도','경상북도','강원도','전라남도'로 이동한 인구 데이터 값만 선택
col_years = list(map(str,range(1970,2018))) # 먼저 1970~2018까지 문자열 데이터로 구성된 리스트 생성
df_4 = df_seoul.loc[['충청남도','경상북도','강원도','전라남도'],col_years]
df_4 = df_4.transpose() # 년도가 행으로 오게끔 전치시킴
# 스타일 서식 지정
plt.style.use('ggplot')
# 데이터프레임의 인덱스를 정수형으로 변경(x축 눈금 라벨 표시)
df_4.index.map(int) # 현재 인덱스는 문자형인 년도임
# 면적 그래프 그리기
df_4.plot(kind='area',stacked=False, alpha=0.2, figsize=(20,10))
plt.title('서울 -> 타시도 인구 이동',size=30)
plt.ylabel('이동 인구 수',size=20)
plt.xlabel('기간', size=20)
plt.legend(loc='best',fontsize=15)
plt.show()
Python
복사
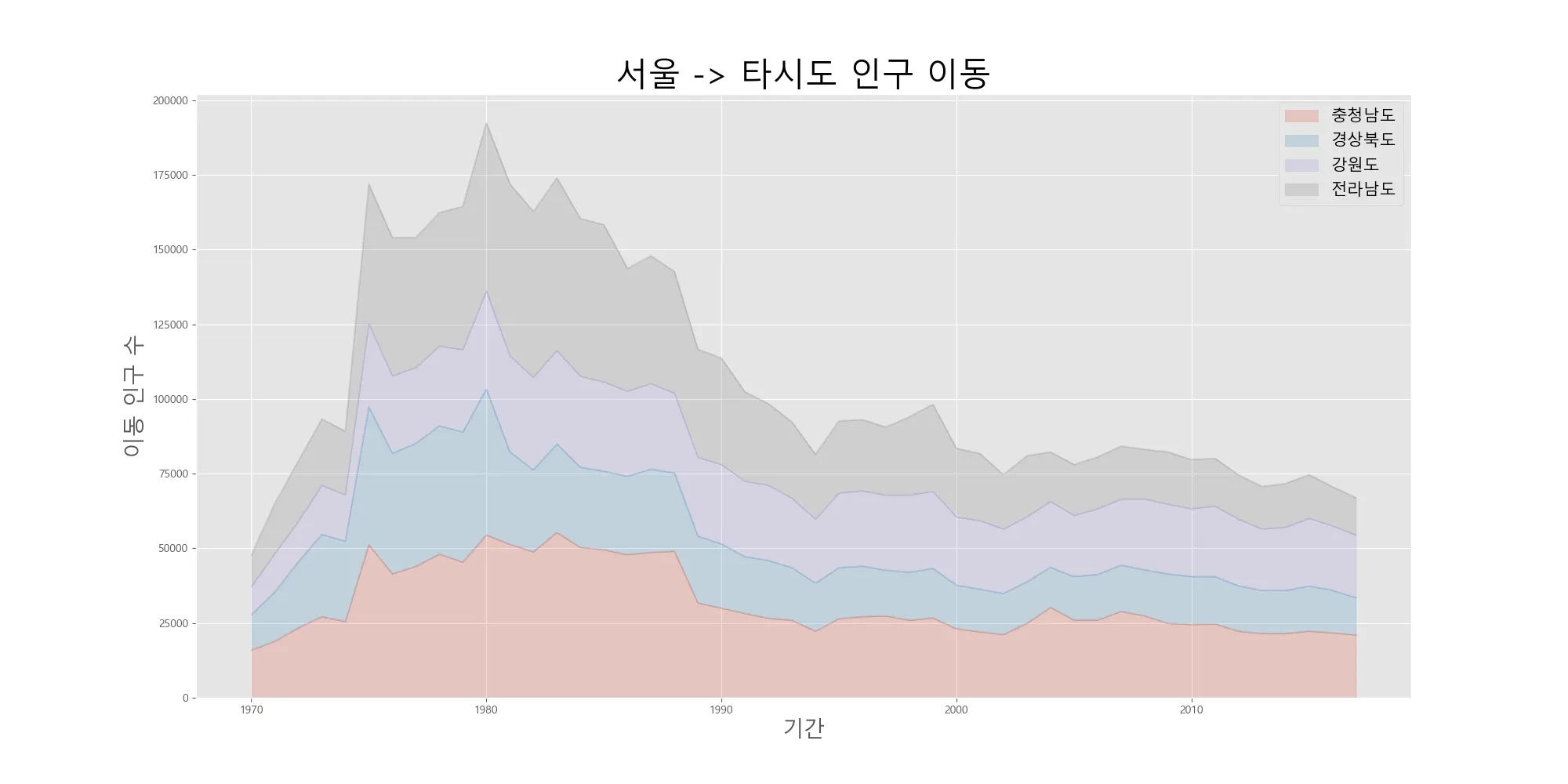
이번에는 stacked=True로 지정하여 선 그래프들이 서로 겹치지 않고 위 아래로 데이터가 누적되는 면적 그래프를 그려보자.
# 데이터프레임의 인덱스를 정수형으로 변경(앞의 내용과 같음)
df_4.index = df_4.index.map(int)
# 면적 그래프 그리기
df_4.plot(kind='area',stacked=True,alpha=0.2,figsize=(20,10))
plt.title('서울 -> 타시도 인구 이동',size=30)
plt.ylabel('이동 인구 수',size=20)
plt.xlabel('기간', size=20)
plt.legend(loc='best',fontsize=15)
plt.show()
Python
복사
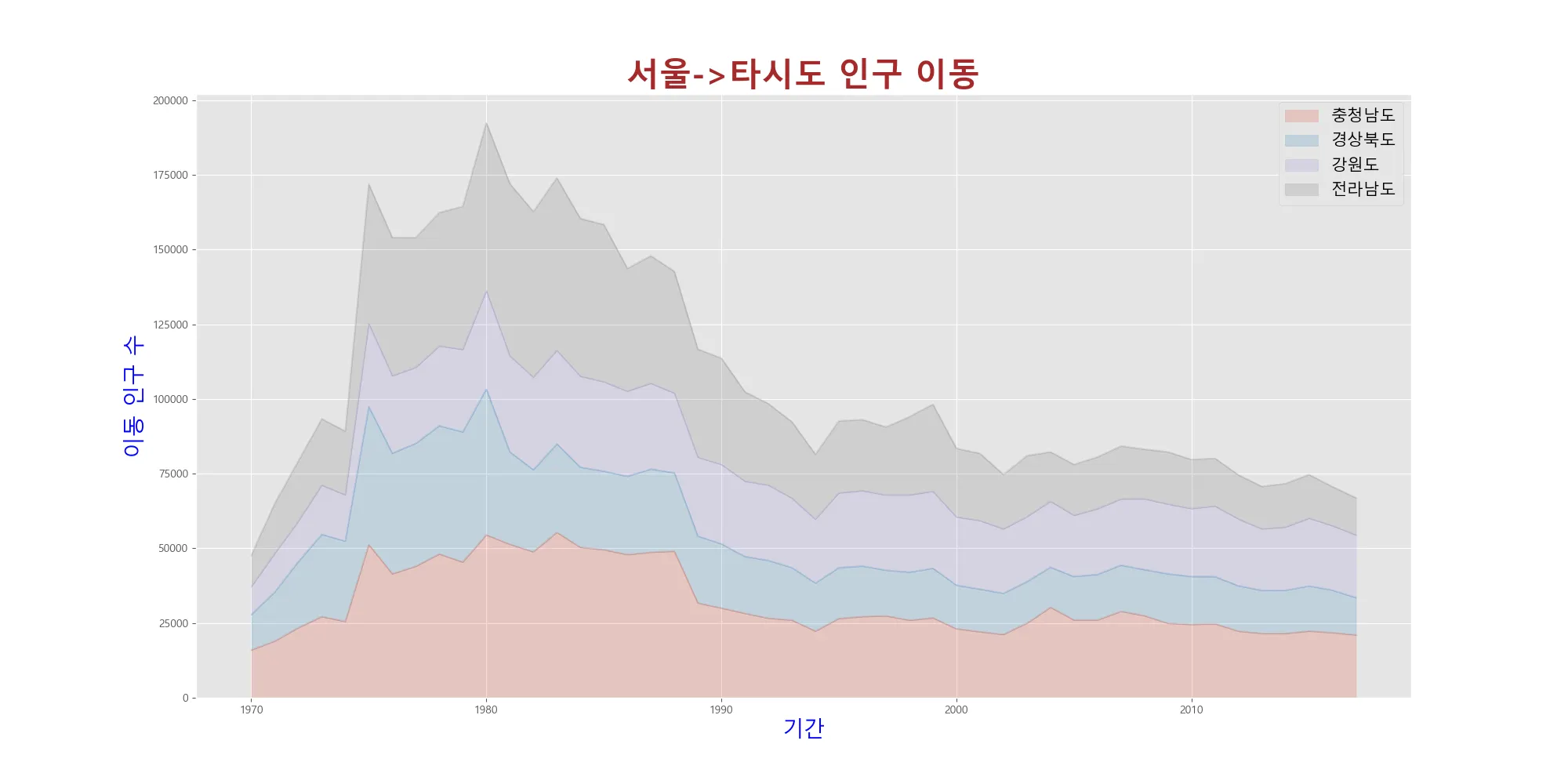
axe객체의 세부적인 요소를 설정할 수 있다. axe객체의 속성을 이용해서 제목, 축 이름 등을 설정해보자.
# 면적 그래프 axe 객체 생성
ax = df_4.plot(kind='area',stacked=True,alpha=0.2,figsize=(20,10))
print(type(ax))
# axe객체 설정 변경
ax.set_title('서울->타시도 인구 이동',size=30,color='brown',weight='bold') # 크기, 색깔, 진하기를 설정할 수 있다.
ax.set_ylabel('이동 인구 수',size=20,color='blue')
ax.set_xlabel('기간',size=20,color='blue')
ax.legend(loc='best',fontsize=15)
plt.show()
Python
복사
1-3. 막대 그래프
막대 그래프는 데이터 값의 크기에 비례하여 높이를 갖는 직사각형 막대로 표현한다. 세로형과 가로형의 두가지 종류가 있다. 다만, 세로형의 경우 정보 제공 측면은 선 그래프와 큰 차이가 없다.
특히 세로형 막대의 경우 시간적으로 차이가 나는 두 점에서의 데이터 값의 차이를 잘 설명한다. 따라서 시계열 데이터를 표현하는데 적합하다. plot메소드에 kind=’bar’ 옵션으로 막대그래프를 그린다.
다음은 2010~2017년에 해당하는 데이터를 추출하기 위해, col_years의 범위를 조정한다. plot메소드의 color옵션을 추가해서 막대 색상을 다르게 설정할 수도 있다.
col_years = list(map(str,range(2010,2018)))
df_4 = df_seoul.loc[['충청남도','경상북도','강원도','전라남도'],col_years]
df_4 = df_4.transpose()
# 스타일 서식 지정
plt.style.use('ggplot')
df_4.index = df_4.index.map(int) # 인덱스를 정수형으로 전환
# 막대 그래프 그리기
df_4.plot(kind='bar',figsize=(20,10), width=0.7, color=['orange','green','skyblue','blue'])
plt.title('서울->타시도 인구 이동',size=30)
plt.ylabel('이동 인구 수',size=20)
plt.xlabel('기간',size=20)
plt.ylim(5000,30000)
plt.legend(loc='best',fontsize=15)
plt.show()
Python
복사
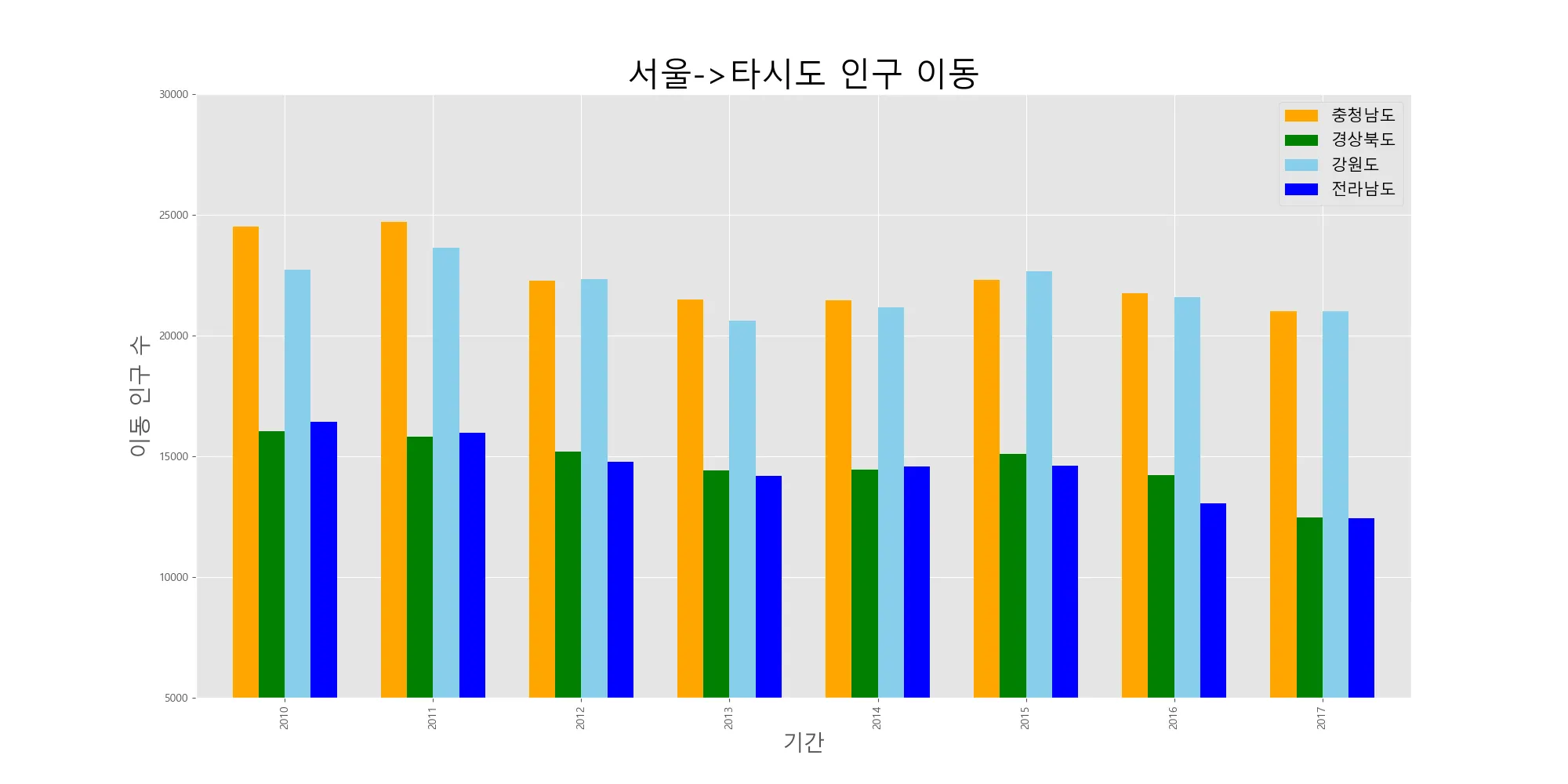
가로형 막대 그래프는 각 변수 또는 열사이의 값의 크기 차이를 설명하는데 적합하다. kind=’barh’로 나타낼 수 있다.
다음은 2010~2017년의 기간 동안 서울에서 각 시도로 이동한 인구의 합계를 구하여 시도별로 비교하는 그래프를 그린 것이다.
col_years = list(map(str,range(2010,2018)))
df_4 = df_seoul.loc[['충청남도','경상북도','강원도','전라남도'],col_years]
# 2010~2017년 이동 인구 수를 합계하여 새로운 열로 추가
df_4['합계'] = df_4.sum(axis=1) # 연도인 열을 합치기
# 가장 큰 값부터 정렬
df_total = df_4[['합계']].sort_values(by='합계',ascending=True) # 합계 데이터를 오름차순으로 정렬
# 스타일 서식 지정
plt.style.use('ggplot')
# 수평 막대 그래프 그리기
df_total.plot(kind='barh',color='cornflowerblue',width=0.5,figsize=(10,5))
plt.title('서울->타시도 인구 이동')
plt.ylabel('전입지')
plt.xlabel('이동 인구 수')
plt.show()
Python
복사
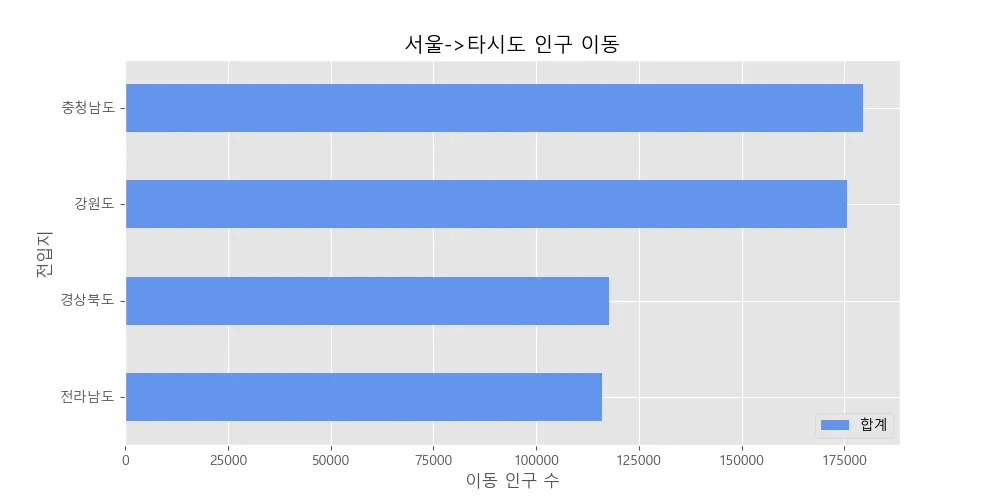
2010~2017년 까지 이동 인구 합계를 기준으로는 서울에서 충청남도로 이동한 사람이 제일 많다는 결과를 얻을 수 있다.
보조 축 활용하기보조 축을 추가하여 2개의 y축을 갖는 그래프를 그릴수도 있다. 남북한 발전량 데이터셋을 사용해서 보조 축을 설정하는 방법을 알아보자. 기존 축에는 막대 그래프의 값을 표시하고 보조 축에는 선 그래프의 값을 표시한다. 막대 그래프는 연도별 북한의 발전량을 나타내고 선 그래프는 북한 발전량의 전년 대비 증감률을 백분률로 나타낸다.
먼저, 증감률을 계산하기 위해 rename()메소드로 ‘합계’열의 이름을 ‘총발전량’으로 바꾸고, shift()메소드를 이용하여 ‘총발전량’열의 데이터를 1행씩 뒤로 이동시켜서 ‘총발전량-1년’열을 새로 생성한다. 그리고 두 열의 데이터를 이용해서 전년도 대비 변동율을 계산한 결과를 ‘증감률’ 열에 저장한다.
# 라이브러리 불러오기
import pandas as pd
import matplotlib.pyplot as plt
# 한글 폰트 사용을 위해서 세팅
import matplotlib
matplotlib.rcParams['font.family']='Malgun Gothic'
matplotlib.rcParams['axes.unicode_minus']=False
plt.style.use('ggplot') # 스타일 서식 지정
# excel 데이터를 데이터프레임으로 변환
df = pd.read_excel('./남북한발전량.xlsx', engine='openpyxl',convert_float=True)
df = df.loc[5:9] # 북한 데이터만 뽑기
df.drop('전력량 (억㎾h)',axis=1,inplace=True) # 전력량 열 삭제
df.set_index('발전 전력별',inplace=True) # 행 인덱스를 발전 전력별 열로 지정
df = df.T # 전치시켜 행 인덱스가 열이 되고, 년도 열이 행이 됨
df.head()
발전 전력별 합계 수력 화력 원자력
1990 277 156 121 -
1991 263 150 113 -
1992 247 142 105 -
1993 221 133 88 -
1994 231 138 93 -
# 증감률(변동률) 계산
df = df.rename(columns={'합계':'총발전량'})
df['총발전량 - 1년'] = df['총발전량'].shift(1) # 총발전량 열의 데이터를 1행씩 뒤로 이동한 열을 새로 만듦.
df.head()
Out[22]:
발전 전력별 총발전량 수력 화력 원자력 총발전량 - 1년
1990 277 156 121 - NaN
1991 263 150 113 - 277
1992 247 142 105 - 263
1993 221 133 88 - 247
1994 231 138 93 - 221
df['증감률'] = ((df['총발전량']/df['총발전량 - 1년']) - 1)*100
Out[24]:
발전 전력별 총발전량 수력 화력 원자력 총발전량 - 1년 증감률
1990 277 156 121 - NaN NaN
1991 263 150 113 - 277 -5.054152
1992 247 142 105 - 263 -6.08365
1993 221 133 88 - 247 -10.526316
1994 231 138 93 - 221 4.524887
# 2축 그래프 그리기
ax1 = df[['수력','화력']].plot(kind='bar',figsize=(20,10),width=0.7,stacked=True) #막대그래프의 stacked=True는 각 열의 값을 아래위로 쌓은형태의 그래프다.
ax2 = ax1.twinx() # ax1의 쌍둥이 객체를 twinx() 메소드로 만들기
ax2.plot(df.index,df.증감률,ls='--',marker='o',markersize=20,color='red',label='전년대비 증감률(%)')
ax1.set_ylim(0,500)
ax2.set_ylim(-50,50)
ax1.set_xlabel('연도',size=20)
ax1.set_ylabel('발전량(억 ㎾h)')
ax2.set_ylabel('전년 대비 증감률(%)')
plt.title('북한 전력 발전량(1990 ~ 2016)',size=30)
ax1.legend(loc='upper left') # 범례 위치는 왼쪽 위
plt.show()
Python
복사
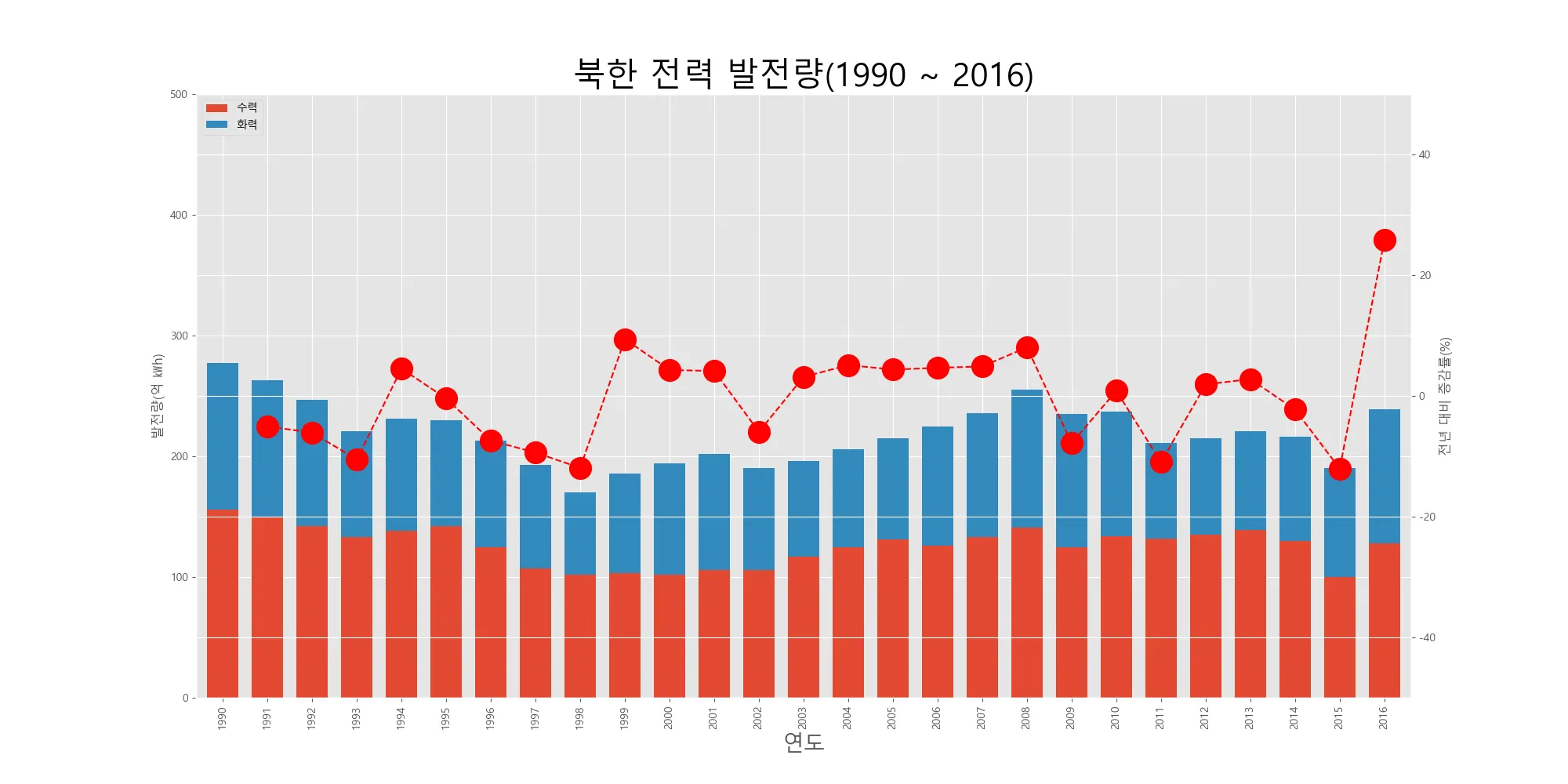
1-4 히스토그램
판다스 내장 그래프 도구 활용
판다스는 Matplotlib 라이브러리의 기능을 일부 내장하고 있어서, 별도로 임포트하지 않고도 간단한 그래프를 손쉽게 그릴 수 있다.
시리즈 또는 데이터프레임 객체에 plot() 메소드를 적용하여 그래프를 그린다. kind 옵션으로 그래프의 종류를 선택한다.
kind옵션 | 설명 | kind옵션 | 설명 |
‘line’ | 선 그래프 | ‘kde’ | 커널 밀도 그래프 |
‘bar’ | 수직 막대 그래프 | ‘area’ | 면적 그래프 |
‘barh’ | 수평 막대 그래프 | ‘pie’ | 파이 그래프 |
'his’ | 히스토그램 | ‘scatter’ | 산점도 그래프 |
‘box’ | 박스 플롯 | ‘hexbin’ | 고밀도 산점도 그래프 |
~ 선 그래프
데이터프레임 또는 시리즈 객체에 plot()메소드를 적용할 때, 다른 옵션을 추가하지 않으면 가장 기본적인 선 그래프를 그린다.
•
선 그래프 : df. plot()
남북한의 발전량 데이터셋을 이용해서 선 그래프를 그려보겠다.
import pandas as pd
df = pd.read_excel('./남북한발전전력량.xlsx', engine='openpyxl') # 데이터프레임으로 반환
df.head()
전력량 (억㎾h) 발전 전력별 1990 1991 1992 1993 ... 2011 2012 2013 2014 2015 2016
0 남한 합계 1077 1186 1310 1444 ... 4969 5096 5171 5220 5281 5404
1 NaN 수력 64 51 49 60 ... 78 77 84 78 58 66
2 NaN 화력 484 573 696 803 ... 3343 3430 3581 3427 3402 3523
3 NaN 원자력 529 563 565 581 ... 1547 1503 1388 1564 1648 1620
4 NaN 신재생 - - - - ... - 86 118 151 173 195
[5 rows x 29 columns]
df_ns = df.iloc[[0,5],3:] # 남한, 북한 발전량 합계 데이터만 추출
df_ns.head()
1991 1992 1993 1994 1995 1996 ... 2011 2012 2013 2014 2015 2016
0 1186 1310 1444 1650 1847 2055 ... 4969 5096 5171 5220 5281 5404
5 263 247 221 231 230 213 ... 211 215 221 216 190 239
[2 rows x 26 columns]
# 행 인덱스 변경
df_ns.index = ['South','North']
df_ns.info()
<class 'pandas.core.frame.DataFrame'>
Index: 2 entries, South to North
Data columns (total 26 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 1991 2 non-null object
1 1992 2 non-null object
2 1993 2 non-null object
3 1994 2 non-null object
4 1995 2 non-null object
5 1996 2 non-null object
6 1997 2 non-null object
7 1998 2 non-null object
8 1999 2 non-null object
9 2000 2 non-null object
10 2001 2 non-null object
11 2002 2 non-null object
12 2003 2 non-null object
13 2004 2 non-null object
14 2005 2 non-null object
15 2006 2 non-null object
16 2007 2 non-null object
17 2008 2 non-null object
18 2009 2 non-null object
19 2010 2 non-null object
20 2011 2 non-null object
21 2012 2 non-null object
22 2013 2 non-null object
23 2014 2 non-null object
24 2015 2 non-null object
25 2016 2 non-null object
dtypes: object(26)
memory usage: 432.0+ bytes
# 숫자형이어야 할 값들이 모두 문자열로 되어있는 것을 확인
# 열 이름의 자료형을 정수형으로 변경
df_ns.columns = df_ns.columns.map(int)
print(df_ns.head())
1991 1992 1993 1994 1995 1996 ... 2011 2012 2013 2014 2015 2016
South 1186 1310 1444 1650 1847 2055 ... 4969 5096 5171 5220 5281 5404
North 263 247 221 231 230 213 ... 211 215 221 216 190 239
[2 rows x 26 columns]
Python
복사
데이터프레임에 plot() 메소드를 사용하면 행 인덱스를 x축 데이터로 적용한다. 위의 예시에 적용시켜보면 ‘South’와 ‘North’ 가 x축으로 전달된다.# 선 그래프 그리기
df_ns.plot()
Python
복사
결과를 살펴보면 시간의 흐름에 따른 연도별 발전량 변화 추이를 보기 힘들다. 연도 값이 열로 되어있기 때문인데 따라서 x축에 연도가 오게끔 열 이름을 구성하는 연도 값이 행 인덱스에 위치하도록 전치시켜서 tdf_ns 데이터프레임으로 만든다.
# 행, 열 전치하여 다시 그리기
tdf_ns = df_ns.T
print(tdf_ns.head())
South North
1991 1186 263
1992 1310 247
1993 1444 221
1994 1650 231
1995 1847 230
tdf_ns.plot()
Python
복사
~ 막대 그래프
plot() 메소드를 사용해서 선 그래프가 아닌 다른 그래프를 그리려면 kind 옵션에 그래프 종류를 지정해준다. 막대그래프를 그리려면 kind=’bar’ 을 해준다.
•
막대 그래프 : df.plot(kind=”bar”)
전치시킨 tdf_ns 데이터프레임을 가지고 막대그래프를 그려보겠다.
# 막대 그래프 그리기
tdf_ns.plot(kind="bar")
Python
복사
~ 히스토그램
plot() 메소드에 kind=”hist” 옵션을 지정해준다.
•
히스토그램 : df.plot(kind=”hist”)
# 히스토그램 그리기
tdf_ns.plot(kind="hist")
Python
복사
이때, 열의 타입을 먼저 확인해 주고 문자열 타입이면 숫자형으로 변경해줘야 한다.
tdf_ns = tdf_ns.astype('int64')
Python
복사
~ 산점도
UCI 자동차 연비 데이터셋을 이용하여 두 변수의 관계를 나타내는 산점도를 그린다. plot함수에 kind=”scatter” 옵션을 넣어준다.
데이터프레임의 열 중에서 서로 비교할 두 변수를 선택한다.
x축에 차량의 무게 데이터인 ‘weight’ 열을 지정하고, y축에는 연비를 나타내는 ‘mpg’열을 지정한다.
# read_csv()함수로 df 생성
df = pd.read_csv('./auto-mpg.csv', header=None) # 첫 행부터 데이터 시작이다.
# 열 이름 지정
df.columns = ['mpg','cylinders','displacement','horsepower','weight','acceleration',
'model year','origin','name']
# 2개의 열을 선택하여 산점도 그리기
df.plot(x='weight',y='mpg', kind='scatter')
Python
복사
~박스 플롯
특정 변수의 데이터 분포와 분산 정도에 대한 정보를 제공한다. kind=’box’ 옵션으로 지정한다.
자동차 연비 데이터셋의 ‘mpg’ 열의 통계적 요약 정보를 먼저 확인해보자.
df['mpg'].describe()
Out[21]:
count 398.000000
mean 23.514573
std 7.815984
min 9.000000
25% 17.500000
50% 23.000000
75% 29.000000
max 46.600000
Name: mpg, dtype: float64
Python
복사
9 ~ 46 의 범위에 넓게 분포되어 있고, ‘o’ 표시의 이상값도 확인된다.
한편 ‘cylinders’ 열의 통계적 요약 정보도 확인해보자.
df['cylinders'].describe()
Out[22]:
count 398.000000
mean 5.454774
std 1.701004
min 3.000000
25% 4.000000
50% 4.000000
75% 8.000000
max 8.000000
Name: cylinders, dtype: float64
Python
복사
mpg에 비해 상대적으로 3~ 8의 범위로 좁은 범위에 분포되어 있다.
이제, boxplot을 그려보자.
df[['mpg','cylinders']].plot(kind="box")
Python
복사