
DataFrame을 재형성하는 대표적인 작업은 데이터 피벗(pivoting)입니다.
데이터 피벗은 데이터를 요약하는 통계표를 만드는 일입니다. 피벗은 말 그대로 데이터를 회전시킨다는 의미입니다. 표 형식의 데이터를 회전시켜 재배치하는 일을 재형성 또는 피벗 연산이라고 하죠.
이 피벗에는 두 가지 방법이 있습니다. 하나는 길이가 긴 형식의 데이터를 옆으로 넓은 형식으로 만드는 것이고, 다른 하나는 옆으로 넓은 형식의 데이터를 긴 형식으로 만드는 것입니다. 하나씩 차례로 살펴보겠습니다.
1) 긴 형식 → 넓은 형식 : pivot, unstack
•
pivot 함수는 데이터프레임에 색인이 없고, 색인을 직접 지정하고 싶을 때 사용한다.
•
unstack 함수는 데이터프레임에 계층적 색인이 있는 경우에 사용한다.
1.
pivot ( 지정된 색인이 없을 때 )
pivot 함수는 시계열 데이터처럼 같은 날 측정한 데이터 종류가 여러 개여서 길이가 긴 데이터를 옆으로 넓게 만드는 데 유용하다.
해당 함수는 index , columns , values 등의 매개변수를 사용한다.
•
index : 행 색인으로 지정할 열 이름
•
columns : 열 색인으로 사용할 열 이름
•
values : 값에 해당하는 열 이름
2.
unstack( 계층적 색인이 있는 이미 있는 경우 )
계층적 색인이 있는 DataFrame의 데이터를 수직으로 긴 방향에서 옆으로 넓게 만들어준다.
→ 예를 들어 이미 계층적 색인이 있는 데이터프레임에서 unstack() 을 실행하면 넓게 만들어준다.
이는 반대로, stack() 사용하면 옆으로 퍼져 있던 데이터를 다시 수직으로 긴 방향으로 만든다는 말이다.
stack() 되어 있는 계층적 색인을 지닌 상태에서 원래의 데이터프레임으로 돌려놓거나, 단계에 따라 계층을 해체할 수 있다. 예를 들어,
•
result.unstack(-1) 는 원래의 데이터프레임으로 돌아가는 것
•
result.unstack(0 또는 0에 해당하는 이름) 는 두번째 단계의 계층을 해체
•
result.unstack(1 또는 1에 해당하는 이름) 는 세번째 단계의 계층을 해체
< 계층적 색인이 서로 다른 두 시리즈에서 동일한 계층적 색인을 만들고 싶다면>
concat → unstack → stack 순서로 진행한다.
s1 = pd.Series([0, 1, 2], index=['a', 'b', 'c'])
s2 = pd.Series([4, 5, 6, 7, 8], index=['c', 'd', 'e', 'f', 'g'])
data2 = pd.concat([s1, s2], keys=['GroupA', 'GroupB'])
data2.unstack().stack(dropna=False)
Python
복사
Pivot vs Melt
기본적으로 데이터 구조를 변경할 때 melt 와 pivot 함수를 사용한다.
1. melt()
가로의 데이터를 세로로 바꾸는 함수다.
컬럼을 값으로 바꿔서 아래로 데이터를 줄세우는 방식이다.
필요한 지정 값에는
•
id_vars : 기준 컬럼
•
value_vars : 기존 컬럼 (데이터로 바꾸고 싶은 컬럼)
•
var_name : 데이터가 될 컬럼의 이름
•
value_name : 기존 값들의 컬럼 이름
df.melt(id_vars=['기준년월'], value_vars=df.columns[:1], var_name='기업구분', value_name='회사개수')
Python
복사
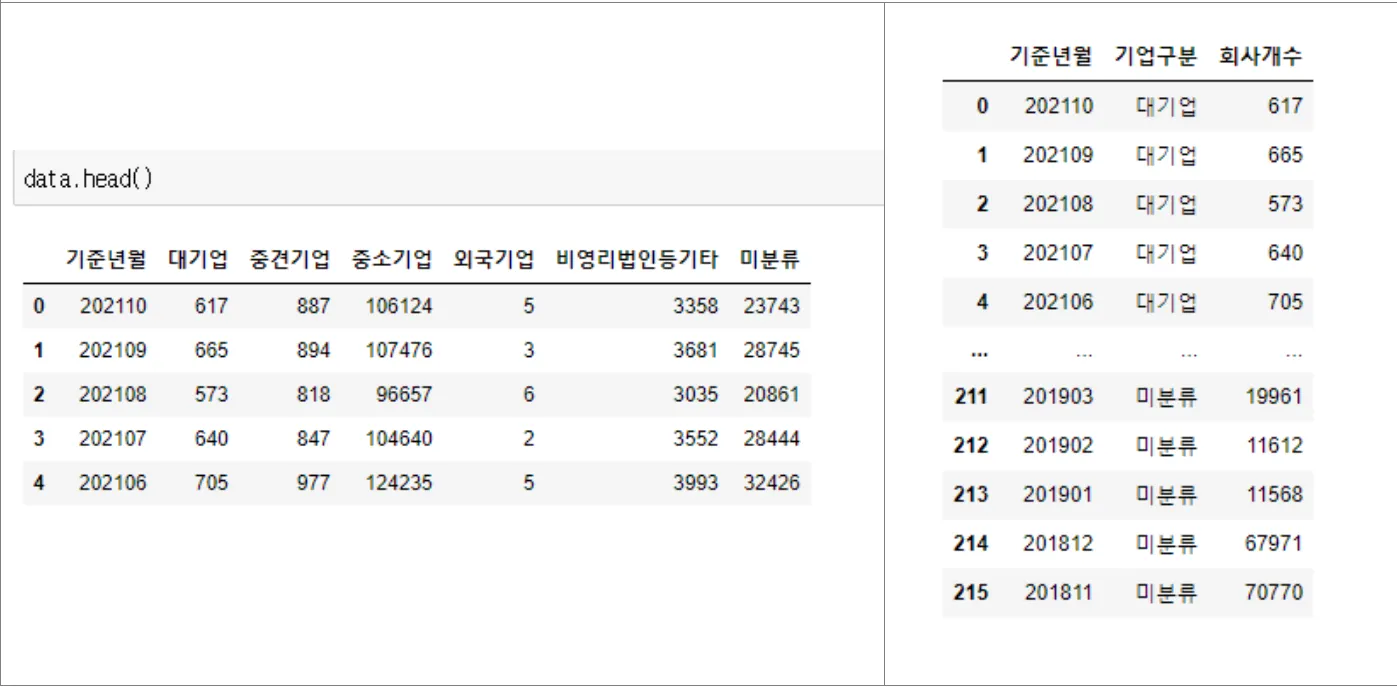
대기업, 중견기업, …미분류 등의 컬럼들을 ‘기업구분’이라는 컬럼의 데이터 종류로 만들고 싶을 경우, melt 함수를 이용하면 간단하게 데이터 구조를 변경할 수 있다.
2. pivot() - 간단한 피벗 변환
melt() 함수와 반대로 세로로 있는 데이터들을 가로로 바꿀 때 사용한다.
•
각 인덱스 - 열 조합이 고유한 값을 가질 때 사용된다.
◦
만약 동일한 인덱스 - 열 조합에 여러 값이 있을 경우(중복값이 있을 경우), 오류를 발생시킴
df.pivot(index=기준컬럼, columns=컬럼이될컬럼, values=값이될컬럼)
Python
복사
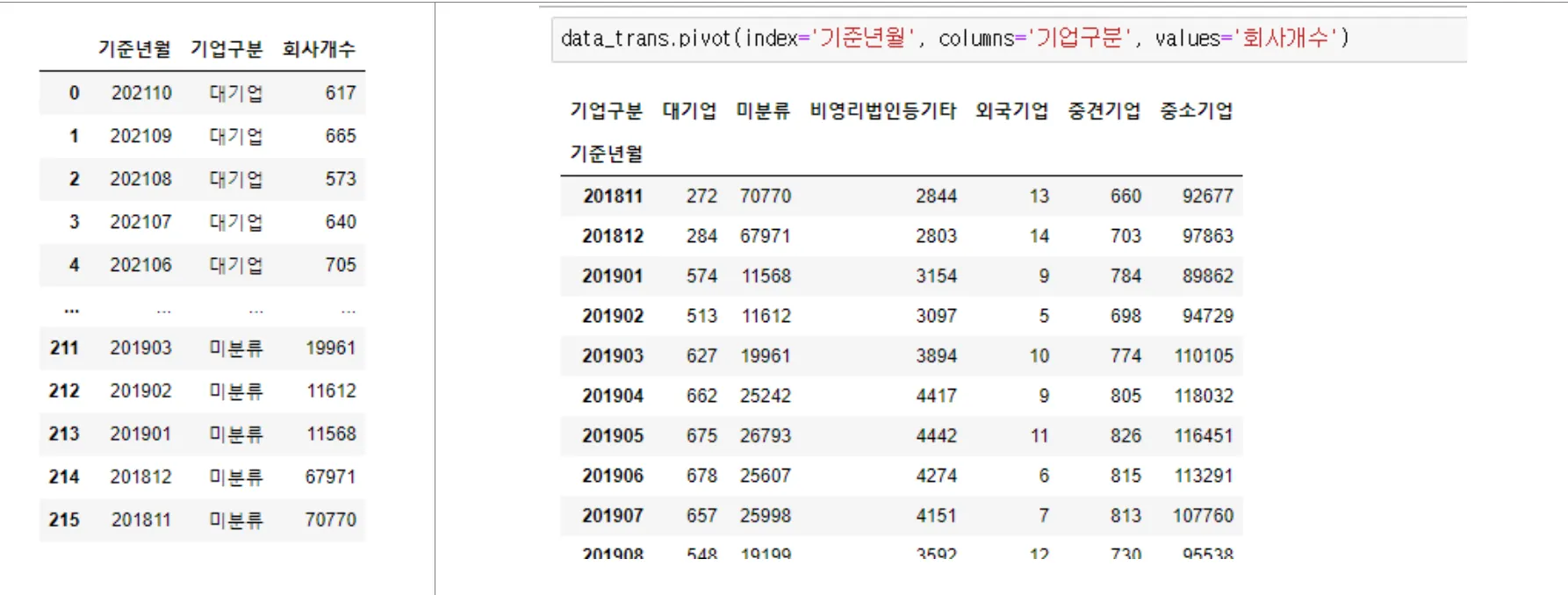
3. pivot_table() - 유연한 피벗 변환
pivot() 보다 좀 더 유연하게 집계해서 생성
•
동일한 인덱스-열 조합에 여러 값이 있을 경우, 집계 함수(aggfunc)를 이용해 여러 값을 처리할 수 있다.
기본적으로 mean() 을 사용하지만, 다른 함수도 사용할 수 있다.
•
pivot()과 달리 동일한 인덱스-열 조합에 대해 여러 값을 처리할 수 있기 때문에 오류 발생 없이 사용 가능하다.
•
결측치를 채우는 옵션도 지정할 수 있다.(fill_value )
◦
보통 0으로 채워넣는다.
df.pivot_table(index=기준컬럼, columns=컬럼이될컬럼, values=값이될컬럼, aggfunc=집계함수, fill_value=None)
Python
복사

•
pivot() 사용 시점:
◦
중복된 값이 없고, 단순한 피벗 테이블이 필요할 때.
◦
여러 값이 겹치지 않는 데이터를 쉽게 재구조화할 때.
•
pivot_table() 사용 시점:
◦
데이터에서 중복된 항목이 존재하고, 이를 처리할 집계 함수가 필요할 때.
◦
결측값 처리가 필요하거나, 다양한 통계 집계가 필요한 경우.
◦
다중 값 피벗이 필요할 때.