

Concat 과 Merge, Join 등의 방식이 있다.
1. merge : combining data on common columns or indices
두 데이터프레임의 고유값(key)를 기준으로 병합한다.
고유값은 변수 또는 인덱스가 될 수 있다.
•
같은 이름의 열이 있으면 on 파라미터를 설정하지 않아도 자동으로 그 열을 기준으로 조인된다.
•
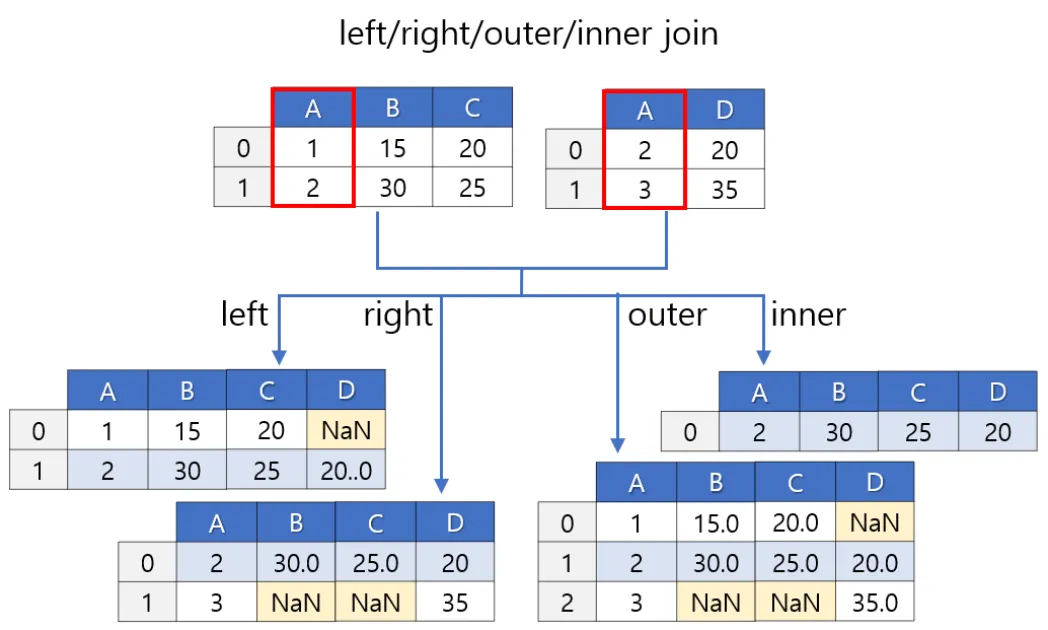
how=’inner’ 가 기본값이다.
df1 = pd.DataFrame({
'data1':range(6),
'key':list('aabbcc')
})
df2 = pd.DataFrame({
'data2':range(3),
'key':list('cad')
})
print(df1, '\n\n', df2)
data1 key
0 0 a
1 1 a
2 2 b
3 3 b
4 4 c
5 5 c
data2 key
0 0 c
1 1 a
2 2 d
Python
복사
•
how=’inner’ : default
공통열을 기준으로 이너조인 한다.
pd.merge(df1, df2)
Out[5]:
data1 key data2
0 0 a 1
1 1 a 1
2 4 c 0
3 5 c 0
Python
복사
•
how=’outer’
아우터조인한다.
# how='outer'
pd.merge(df1, df2, on='key', how='outer') # on : 조인키 지정
Out[6]:
data1 key data2
0 0.0 a 1.0
1 1.0 a 1.0
2 2.0 b NaN
3 3.0 b NaN
4 4.0 c 0.0
5 5.0 c 0.0
6 NaN d 2.0
Python
복사
•
how=’left’
레프트 아우터 조인한다.
# how='left' : 레프트 아우터 조인
pd.merge(df1,df2, on='key', how='left')
Out[7]:
data1 key data2
0 0 a 1.0
1 1 a 1.0
2 2 b NaN
3 3 b NaN
4 4 c 0.0
5 5 c 0.0
Python
복사
•
how=’right’
롸이트 아우터 조인한다.
# how='right' : 롸이트 아우터 조인
pd.merge(df1,df2, on='key', how='right')
Out[8]:
data1 key data2
0 4.0 c 0
1 5.0 c 0
2 0.0 a 1
3 1.0 a 1
4 NaN d 2
Python
복사
•
left_on & right_on : 왼쪽 df의 키값과 오른쪽 df의 키값이 같은 것들끼리 m*n 조합으로 데이터프레임 병합이 가능함
df1 = pd.DataFrame({
'data1' : range(7),
'lkey' : list('abcabca')
})
df2 = pd.DataFrame({
'data2' : range(3),
'rkey' : list('abd')
})
pd.merge(df1, df2, left_on='lkey', right_on='rkey') # how='inner'
Out[9]:
data1 lkey data2 rkey
0 0 a 0 a
1 3 a 0 a
2 6 a 0 a
3 1 b 1 b
4 4 b 1 b
Python
복사
2. concat : combining data across rows or columns
•
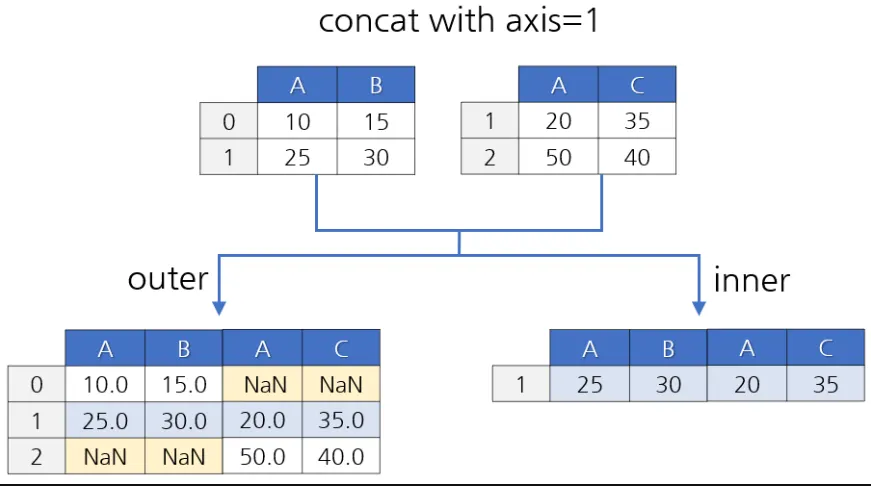
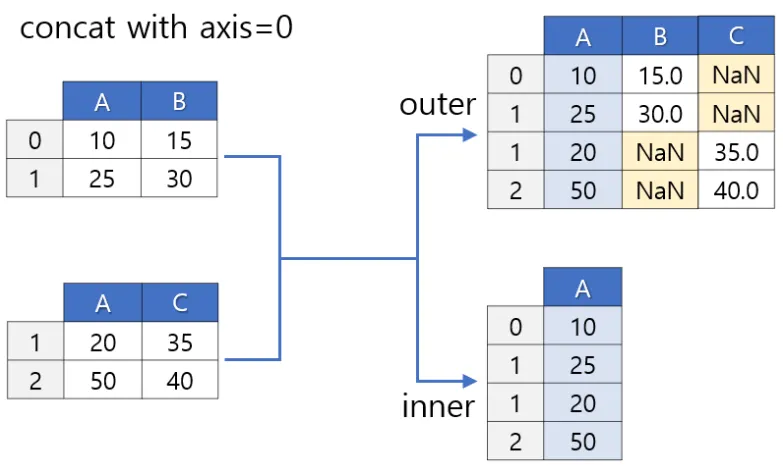
pd.concat([df1, df2], axis=1(또는 0), join=’outer’(또는 ‘inner) )
인덱스 값을 기준으로 두 데이터프레임을 행/열 방향으로 연결시킨다.
◦
axis = 1 : 열 방향으로 연결한다.
◦
axis = 0(default) : 행 방향으로 연결한다.
◦
join = ‘outer’ (default) : 모든 데이터들을 연결한다.
◦
join = ‘inner’ : 동일한 인덱스 값에 대해 연결한다.
3. join : combining data on a column or index
merge() 함수를 기반으로 만들어짐. 작동방식은 비슷하지만 행 인덱스를 기준으로 병합함.
•
how=’left’ : default
df1 = pd.DataFrame({
'data1' : range(7),
'lkey' : list('abcabca'),
}, index = range(7))
df2 = pd.DataFrame({
'data2' : range(3),
'rkey' : list('abd')
}, index = [2, 3, 4])
df1.join(df2) # how='left' : default
Out[10]:
data1 lkey data2 rkey
0 0 a NaN NaN
1 1 b NaN NaN
2 2 c 0.0 a
3 3 a 1.0 b
4 4 b 2.0 d
5 5 c NaN NaN
6 6 a NaN NaN
Python
복사