

직관적으로 이해하기 쉬운 알고리즘. 데이터의 어떤 기준을 바탕으로 규칙을 만들어야 가장 효율적인 분류가 될 것인가가 알고리즘의 성능을 크게 좌우한다.
많은 규칙이 있다는 것은 곧 분류를 결정하는 방식이 복잡해진다는 의미고 과적합으로 이어지기 쉽다. 즉, 트리의 깊이가 깊어질수록 테스트 데이터에 대한 예측 성능이 저하될 가능성이 높다.
가능한 적은 결정 노드로 높은 예측 정확도를 가져야 한다. 그러기 위해서는
1.
최대한 균일한 데이터 세트를 구성할 수 있도록 분할하는 것이 필요하다. 균일도는 데이터를 구분하는 데 필요한 정보의 양에 영향을 미친다. —> 결정 노드는 정보 균일도가 높은 데이터 세트를 먼저 선택할 수 있도록 규칙 조건을 만든다.
—> 정보의 균일도를 측정하는 대표적인 방법 : 엔트로피지수, 지니 계수
•
엔트로피 : 데이터 집합의 혼잡도 ( 클수록 균일도가 낮다 )
•
정보 이득 지수 : 1-엔트로피 지수 —> 결정트리는 이 지수로 분할 기준을 정한다. (클수록 균일도가 높은 것)
•
지니 계수 : 불평등 지수. 낮을수록 데이터 균일도가 높다. (즉, 클수록 균일도가 낮다 ) (0~1)
사이킷런의 DecisionTreeClassifier는 기본으로 지니 계수를 이용해서 데이터 세트를 분할한다. 이 과정을 데이터가 모두 특정 분류에 속하게 될때까지 한다.
결정 트리 모델의 특징
결정 트리의 장점은 알고리즘이 쉽고 직관적이며 시각화로 표현까지 할 수 있다는 점이다. 또한, 특별한 경우를 제외하고는 피처의 스케일링이나 정규화 같은 전처리 작업이 필요하지 않다.
반면, 단점은 과적합으로 예측 정확도가 떨어진다는 점이다.
결정 트리의 단점을 보완하는 방법으로 트리의 크기를 사전에 제한하는 방법이 있다.
결정 트리 파라미터
사이킷런에서 결정 트리 알고리즘은 DecisionTreeClassifier 과 DecisionTreeRegressor 클래스가 있다. 첫번째는 분류를 위한 것이고 후자는 회귀를 위한 것이다.
이 결정 트리 구현은 CART 알고리즘 기반이다. CART는 분류뿐만 아니라 회귀에서도 사용될 수 있는 트리 알고리즘이다.
둘의 파라미터는 모두 동일하다. 이 장에서는 분류만 사용할 것이다.
파라미터 명 | 설명 |
min_samples_split | 노드를 분할하기 위한 최소한의 샘플 데이터 수 —> 과적합 제어하는데 사용, default=2, 작게 설정할수록 과적합 가능성 증가, 크게 설정할수록 규제 강화 |
min_samples_leaf | 말단 노드가 되기 위한 최소한의 샘플 데이터 수, 마찬가지로 과적합 제어하는데 사용, 데이터 분포가 비대칭적이면 작게 설정할 필요도 있음 |
max_features | 최적의 분할을 위해 고려할 최대 피처 개수. default는 None —> 모든 피처 사용. (int, float, sqrt, auto, log) |
max_depth | 트리의 최대 깊이를 규정. default=None, 적절한 값으로 제어할 필요가 있다. (과적합 방지하기위해) |
max_leaf_nodes | 말단 노드의 최대 개수 |
결정 트리 모델의 시각화
결정 트리 알고리즘이 어떤 규칙으로 생성되는지 시각적으로 확인할 수 있는 방법은 Graphviz패키지를 사용하는 것이다. 사이킷런은 export_graphviz() API를 제공한다.
일단 먼저 Graphviz패키지를 사용하기 위해서 이를 다운로드 받고 파이썬과 인터페이스할 수 있는 파이썬 래퍼 모듈을 별도로 설치한다. 그 다음 연결시키기 위해 윈도우의 사용자 변수 경로와 시스템 변수 경로에 프로그램의 경로를 추가한다.
이제, 실제로 데이터를 가지고 결정트리를 시각화 해볼 것이다.
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import warnings
warnings.filterwarnings('ignore')
# DecisionTree Classifier 생성
dt_clf = DecisionTreeClassifier(random_state=156)
# 붓꽃 데이터를 로딩하고, 학습과 테스트 데이터 세트 분리
iris_data = load_iris()
X_train,X_test,y_train,y_test = train_test_split(iris_data.data,iris_data.target,test_size=0.2,random_state=11)
# DecisionTreeClassifier 학습 -> 과적합 규제 x
dt_clf.fit(X_train,y_train)
Python
복사
export_graphviz() 인자에 학습이 완료된 추정기, output 파일 명, 결정 클래스의 명칭, 피처의 명칭이 들어간다.
from sklearn.tree import export_graphviz
# export_graphviz()의 호출 결과로 out_file로 지정된 tree.dot 파일을 생성함
export_graphviz(dt_clf,out_file="tree.dot", class_names=iris_data.target_names,\
feature_names = iris_data.feature_names, impurity=True, filled=True)
Python
복사
import graphviz
#위에서 생성된 tree.dot 파일을 Graphviz가 읽어서 주피터 노트북상에서 시각화
with open("tree.dot") as f:
dot_graph = f.read()
graphviz.Source(dot_graph)
Python
복사
자식노드가 없는 노드를 리프노드라고 한다. 즉, 최종 클래스값이 결정된 노드이다. 지니계수는 클수록 불순도가 큰 것이기 때문에 작을수록 좋다.
또는, dot파일을 만들지 않고 바로 트리를 그릴 수 있는 plot_tree() 함수도 있다.
sklearn.tree.plot_tree(decision_tree, max_depth=None, feature_names=None, class_names=None, label='all', filled=False, impurity=True, node_ids=False, proportion=False, rounded=False, precision=3, ax=None, fontsize=None)
•
filled = True 이면 paint nodes to indicate majority class for classification, extremity of values for regression ( default = False )
•
impurity = True 이면 When set to True, show the impurity at each node. ( default = True )
•
rounded = True 이면 draw node boxes with rounded corners and use Helvetica fonts instead of Times-Roman. ( default = False )
from sklearn.tree import plot_tree
plot_tree(dt_clf,class_names=iris_data.target_names,feature_names=iris_data.feature_names,filled=True,rounded=True)
Python
복사
리프 노드가 되기 위한 조건은 :
1.
오직 하나의 클래스 값으로 모든 데이터가 구성되어있거나
2.
리프 노드가 될 수 있는 하이퍼 파라미터 조건을 충족해야 한다.
자식노드가 있는 노드는 브랜치 노드(=뿌리노드)라고 부른다.
결정 트리 알고리즘의 과적합을 방지하기 위해서 max_depth, min_samples_split, min_samples_leaf 를 제한하는 것 말고도 피처 중요도를 통해 아예 트리모델에 반영하는 변수를 줄일 수도 있다. 피처 중요도는 학습된 추정기에서 feature_importances_ 속성으로 얻을 수 있다.
feature_importances_는 ndarray 형태로 값을 반환하고 피처 순서대로 값이 나온다고 보면 된다.
다음은 dt_clf의 feature_importances_속성을 가져와 중요도값을 매핑하고 막대그래프를 표현해보겠다.
import seaborn as sns
import numpy as np
%matplotlib inline
# feature importance 추출
print("Feature importances:\n{0}".format(np.round(dt_clf.feature_importances_, 3)))
# feature별 importance 매핑
for name, value in zip(iris_data.feature_names,dt_clf.feature_importances_):
print('{0} : {1:.3f}'.format(name,value))
'''
Feature importances:
[0.025 0. 0.555 0.42 ]
sepal length (cm) : 0.025
sepal width (cm) : 0.000
petal length (cm) : 0.555
petal width (cm) : 0.420
'''
# feature importance를 column별로 시각화하기
sns.barplot(x=dt_clf.feature_importances_,y=iris_data.feature_names)
Python
복사

여러 피처들 중 petal length가 가장 중요한 것을 확인했다.
결정 트리 과적합(overfitting)
이제 과적합 문제를 좀 더 자세히 알아보겠다. 사이킷런의 분류를 위한 테스트용 데이터를 쉽게 만드는 make_classification() 함수를 이용해 2개의 피처가 3가지 유형의 클래스 값을 가지는 데이터 세트를 만들고 그래프 형태로 시각화하겠다. make_classification()의 반환 개체는 피처 데이터 세트와 클래스 레이블 데이터 세트다.
make_classification(n_samples,n_features,n_informative,n_redundant,n_repeated,n_classes,n_clusters_per_class, weights, flip_y)
•
n_samples (default=100) : 표본 데이터 수
•
n_features (default=20) : 독립 변수의 수 (피처 수)
•
n_informative (default=2) : 독립 변수 중 종속 변수와 상관 관계가 있는 성분의 수
•
n_redundant (default=2) : 독립 변수 중 다른 독립 변수의 선형 조합으로 나타나는 성분의 수
•
n_repeated (default=0) : 독립 변수 중 단순 중복된 성분의 수
•
n_classes (default=2) : 종속 변수의 클래스 수
•
n_clusters_per_class : 클래스 당 클러스터의 수 (default=2)
•
weights (default=None) : 각 클래스에 할당된 표본 수
•
flip_y : 클래스가 임의로 교환되는 샘플의 일부, 라벨에 노이즈를 생성하여 분류를 어렵게 만든다.(default=0.01)
from sklearn.datasets import make_classification
import matplotlib.pyplot as plt
%matplotlib inline
plt.title("3 Class values with 2 Features Sample data creation")
# 2차원 시각화를 위해서 피처는 2개, 클래스는 3가지 유형의 분류 샘플 데이터 생성
X_features, y_labels = make_classification(n_features=2,n_redundant=0,n_informative=2,/
n_classes=3,n_clusters_per_class=1,random_state=0)
# 그래프 형태로 2개의 피처로 2차원 좌표 시각화, 각 클래스 값은 다른 색깔로 표시됨.
plt.scatter(X_features[:,0],X_features[:,1],marker='o',c=y_labels, s=25, edgecolor='k')
Python
복사
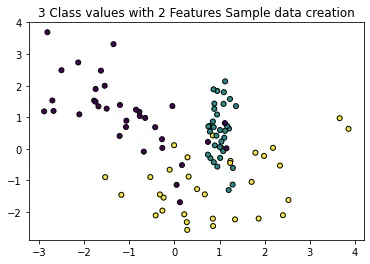
생성된 분류 데이터를 가지고 결정 트리로 학습해보자.
맨 처음에는 파라미터의 제한을 두지 않으면서 어떤 기준을 가지고 데이터를 분류하는지 시각화하면서 확인할 것이다. 이를 위해 visualize_boundary() 함수를 생성할 것이다. 이 함수는 유틸리티 함수다.
ax.scatter 에서
•
zorder 은 도면 순서를 지정한다. 1보다 2가 2보다 3이 나중에 그려진다고 생각하면 된다.
axis() 함수는 축에 관한 다양한 옵션을 제공한다. (on, off, equal, scaled, tight , auto, normal, image, square) : ‘scaled’는 x, y축이 같은 스케일로 나오게 된다. ‘tight’는 모든 데이터를 볼 수 있을 정도로 축의 범위를 충분히 크게 설정한다. ‘off’ 는 축과 라벨을 끈다.
•
np.linspace() 함수는 1차원의 배열 만들기, 그래프 그리기에서 수평축의 간격 만들기 등에 사용하는 함수다. np.linspace(start,stop,num) 과 같이 생겼고, num은 몇 개의 간격을 지정하는 인자다. num의 default는 50이다.
•
np.meshgrid(xi, copy=True, sparse=False, indexing=’xy’) 함수는 격자 그리드를 그려주는 함수다.
◦
xi : 그리드에 나태낼 1차원 배열 벡터
◦
copy =True 가 default , False가 되면 메모리 절약을 위해 오리지널 배열로 반환
◦
sparse = False가 default, True 로 하면 메모리 절약을 위해 희소 그리드를 반환
◦
indexing =’xy’ 가 default, ‘ij’로 하면 행렬 인덱스 방식으로 반환. ‘xy’는 x는 가로, y는 세로로 보고
•
.ravel() 함수는 Numpy 다차원 배열을 1차원으로 바꾸는 함수다.
•
np.c_[] 또는 np.r_[] 함수는 두 배열을 합치는 함수다. r는 행방향으로 합친다는 의미다. 즉 행과 행끼리 합친다고 보면 된다. 하지만 이때 np.r_[[a],[b]] 와 np.r_[a,b] 의 차이가 생긴다. 반면, c 는 열끼리 합친다. np.c_[[a],[b]] 와 np.c_[a,b]의 차이가 np.r_와 정반대다. np.c_[[a],[b]] 의 결과는 a 배열과 b 배열을 하나로 합치면서 또 하나의 리스트의 리스트를 반환한다.
•
np.unique() 함수는 리스트에서 유니크한 요소들만 찾고 싶을 때 사용한다. 배열로 반환된다.
◦
ax.contourf() 함수는 등고선 그래프를 그려주는 함수다. levels 인자는 지정한 수에 맞게 선을 표시하며, alpha 인자는 투명과 불투명을 지정해주는 값이다. (0~1)
from sklearn.tree import DecisionTreeClassifier
import numpy as np
# Classifier의 Decision Boundary를 시각화하는 함수
def visualize_boundary(model,X,y):
fig, ax = plt.subplots()
# 학습 데이터 scatter plot으로 나타내기
ax.scatter(X[:,0],X[:,1],c=y,s=25,cmap="rainbow",edgecolor="k",clim=(y.min(),y.max()),zorder=3)
ax.axis('tight')
ax.axis('off')
xlim_start, xlim_end = ax.get_xlim()
ylim_start, ylim_end = ax.get_ylim()
# 호출 파라미터로 들어온 training 데이터로 model 학습
model.fit(X,y)
# meshgrid 형태인 모든 좌표값으로 예측 수행
xx, yy = np.meshgrid(np.linspace(xlim_start,xlim_end,num=200),np.linspace(ylim_start,ylim_end,num=200))
Z = model.predict(np.c_[xx.ravel(),yy.ravel()]).reshape(xx.shape)
# contourf()를 이용하여 class boundary 를 visualization 수행
n_classes = len(np.unique(y)) # y클래스개수
contours = ax.contourf(xx,yy,Z,alpha=0.3,levels=np.arange(n_classes + 1) - 0.5, cmap="rainbow", clim=(y.min(),y.max()),zorder=1)
# 특정한 트리 생성 제약 없는 결정 트리의 학습과 결정 경계 시각화
dt_clf = DecisionTreeClassifier().fit(X_features,y_labels) # 학습한 모델
visualize_boundary(dt_clf,X_features,y_labels)
Python
복사
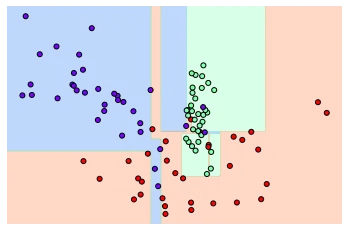
그림에서 알 수 있듯이 굉장히 복잡한 분류 경계가 생성된 것을 확인할 수 있다.
먼저, min_samples_leaf = 6 으로 설정해서 리프 노드가 6개 이하의 데이터만 가져도 될 수 있도록 해보자. (과적합 방지 가능)
# min_samples_leaf=6으로 트리 생성 조건을 제약한 결정 경계 시각화
dt_clf = DecisionTreeClassifier(min_samples_leaf=6).fit(X_features,y_labels)
visualize_boundary(dt_clf,X_features,y_labels)
Python
복사
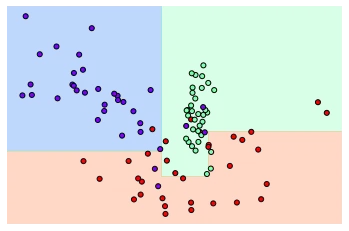
앞의 경우보다 좀 더 일반화된 분류 규칙에 따라 분류된 것을 확인할 수 있다. 예측 성능측면에서는 이 알고리즘이 더욱 뛰어날 가능성이 높다.
결정 트리 실습 - 사용자 행동 인식 데이터 세트
결정 트리 알고리즘을 사용해 사용자 행동 인식 데이터 세트에 대한 예측 분류를 수행해 보겠다.
해당 데이터는 30명의 데이터에서 사람의 동작과 관련된 피처들과 어떤 동작인지 예측할 수 있는 데이터다.
feature.txt 을 로딩해 피처의 명칭만 간략하게 확인해보자.
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
# feature.txt 파일에는 피처 이름 index와 피처명이 공백으로 분리되어 있음. 이를 데이터프레임으로 로드.
feature_name_df = pd.read_csv('human_activity/UCI HAR Dataset/features.txt',sep='\s+',header=None, names=['column_index','column_name'])
# 피처명 index를 제거하고, 피처명만 리스트 객체로 생성한 뒤 샘플로 10개만 추출
feature_name = feature_name_df.iloc[:,1].values.tolist()
print('전체 피처명에서 10개만 추출:',feature_name[:10])
'''
전체 피처명에서 10개만 추출: ['tBodyAcc-mean()-X', 'tBodyAcc-mean()-Y', 'tBodyAcc-mean()-Z', 'tBodyAcc-std()-X', 'tBodyAcc-std()-Y', 'tBodyAcc-std()-Z', 'tBodyAcc-mad()-X', 'tBodyAcc-mad()-Y', 'tBodyAcc-mad()-Z', 'tBodyAcc-max()-X']
'''
Python
복사
문제는 feature.txt 파일이 중복된 피처명을 가지고 있다는 것이다. 이 파일을 데이터프레임으로 로드하면 오류가 발생한다. 따라서 미리 중복되는 피처명에는 _1, _2 를 추가로 부여해서 변경해야 한다.
feature_dup_df = feature_name_df.groupby('column_name').count()
print(feature_dup_df[feature_dup_df['column_index']
'''
column_index 42
dtype: int64
'''
Python
복사
총 중복된 피처들은 42개다.
feature_dup_df[feature_dup_df['column_index']>1].head()
'''
column_index
column_name
fBodyAcc-bandsEnergy()-1,16 3
fBodyAcc-bandsEnergy()-1,24 3
fBodyAcc-bandsEnergy()-1,8 3
fBodyAcc-bandsEnergy()-17,24 3
fBodyAcc-bandsEnergy()-17,32 3
'''
Python
복사
이제, 중복되는 피처들을 알았으니 이들에 _1, _2 를 추가로 부여하는 함수인 get_new_feature_name_df()를 생성하겠다.
DataFrame.reset_index(drop=False,inplace=False): 인덱스를 리셋 하는데 사용한다.
•
drop=False는 기존 인덱스열을 삭제할지 여부를 지정하는 인자다.
•
inplace=False는 원본 데이터를 변경할 것인지의 여부를 지정하는 인자다.
pd.merge(left,right,how,on,left_on,right_on,left_index,right_index,sort,suffixes,copy,indicator) 는 sql을 사용해서 데이터테이블들을 join/merge 하는 것과 유사하게 데이터프레임을 key 기준으로 inner, outer, left, outer join 하여 합치는 방법이다.
•
left, right 는 합칠 데이터프레임 객체 이름이고
•
how =’inner’(default) , # left, right, outer 까지 있다.
◦
left : key값을 기준으로 left 데이터 중심으로 합치는 것
◦
right : key값을 기준으로 right 데이터 중심으로 합치는 것
◦
inner : 교집합되는 key값만의 데이터를 합치는 것
◦
outer : 합집합의 개념.
•
on =None (default) # 병합의 기준이 되는 key 변수 지정
def get_new_feature_name_df(old_feature_name_df):
feature_dup_df = pd.DataFrame(data=old_feature_name_df.groupby('column_name').count(),columns=['dup_cnt'])
feature_dup_df = feature_dup_df.reset_index()
new_feature_name_df = pd.merge(old_feature_name_df.reset_index(),feature_dup_df,how='outer')
new_feature_name_df['column_name'] = new_feature_name_df[['column_name','dup_cnt']].apply(lambda x : x[0]+'_'+str(x[1]) if x[1]>0 else x[0], axis=1)
new_feature_name_df = new_feature_name_df.drop(['index'],axis=1)
return new_feature_name_df
Python
복사
이제, 각각 학습과 테스트 데이터를 로드하겠다. 두 텍스트 데이터 모두 공백으로 분리되어 있다. 해당 데이터세트는 이후 다른 예제에서도 자주 사용하므로 아예 get_human_ dataset() 함수로 만들겠다.
import pandas as pd
def get_human_dataset():
# 각 데이터 파일은 공백으로 분리되어 있음.
feature_name_df = pd.read_csv('human_activity/UCI HAR Dataset/features.txt',sep='\s+',header=None, names=['column_index','column_name'])
# 중복된 피처명을 수정하는 get_new_feature_name_df()를 이용. 신규 피처명 데이터프레임 생성
new_feature_name_df = get_new_feature_name_df(feature_name_df)
# dataframe에 피처명을 칼럼으로 부여하기 위해 리스트 객체로 다시 변환
feature_name = new_feature_name_df.iloc[:,1].values.tolist()
# 학습 피처 데이터세트와 테스트 피처 데이터를 데이터프레임으로 로딩. 칼럼명은 feature_name 적용
X_train = pd.read_csv('human_activity/UCI HAR Dataset/train/X_train.txt',sep='\s+',names=feature_name)
X_test = pd.read_csv('human_activity/UCI HAR Dataset/test/X_test.txt',sep='\s+',names=feature_name)
# 학습 레이블과 테스트 레이블 데이터를 데이터프레임으로 로딩하고 칼럼명은 action 부여
y_train = pd.read_csv('human_activity/UCI HAR Dataset/train/y_train.txt',sep='\s+',header=None,names=['action'])
y_test = pd.read_csv('human_activity/UCI HAR Dataset/test/y_test.txt',sep='\s+',header=None, names=['action'])
# 로드된 학습/테스트용 데이터프레임을 모두 반환
return X_train,X_test,y_train,y_test
X_train,X_test,y_train,y_test = get_human_dataset()
Python
복사
로드한 학습용 피처 데이터 세트를 간략하게 info()로 살펴본다.
print('## 학습 피처 데이터셋 info()')
print(X_train.info())
'''
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 7352 entries, 0 to 7351
Columns: 561 entries, tBodyAcc-mean()-X to angle(Z,gravityMean)
dtypes: float64(561)
memory usage: 31.5 MB
None
'''
Python
복사
학습 데이터셋은 총 7352개이고, 피처개수는 561개다. 피처의 타입은 모두 실수형이다. 따라서 별도로 인코딩은 필요하지 않다.
print(X_train.head(3))
Python
복사
레이블의 종류와 분포를 살펴보겠다.
print(y_train['action'].value_counts())
'''
6 1407
5 1374
4 1286
1 1226
2 1073
3 986
Name: action, dtype: int64
'''
Python
복사
총 6개의 종류가 있고 분포는 대략적으로 고루 분포해보인다.
이제, 결정 트리로 학습 /예측을 해보고 일단 하이퍼 파라미터는 디폴트 값으로 한다.
학습한 모델의 기본 하이퍼 파라미터를 알고 싶다면 추정기.get_params() 를 이용하면 얻을 수 있다.
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
#예제 반복 시마다 동일한 예측 결과 도출을 위해 random_state 설정
dt_clf = DecisionTreeClassifier(random_state=156)
dt_clf.fit(X_train,y_train)
pred = dt_clf.predict(X_test)
accuracy = accuracy_score(y_test,pred)
print('결정 트리 예측 정확도: {0:.4f}'.format(accuracy))
# DecisionTreeClassifier 의 하이퍼파라미터 추출
print('DecisionTreeClassifier 기본 하이퍼 파라미터:\n', dt_clf.get_params())
Python
복사
이제부터 하이퍼파라미터의 변화를 주겠다. 먼저, 트리 깊이가 주는 영향을 살펴보겠다. 물론, GridSearchCV()를 사용한다.
1.
max_depth 를 6,8,10,12,16,20,24 로 늘려가면서 예측 성능을 측정할 것이다.
2.
교차검증은 5세트이다.
from sklearn.model_selection import GridSearchCV
params = {'max_depth':[6,8,10,12,14,16,20,24]}
grid_cv = GridSearchCV(dt_clf,param_grid=params, scoring='accuracy',cv=5, verbose=1)
grid_cv.fit(X_train,y_train)
print('GridSearchCV 최고 평균 정확도 수치 : {0:.4f}'.format(grid_cv.best_score_))
print('GirdSearchCV 최적 하이퍼 파라미터 :', grid_cv.best_params_)
'''
Fitting 5 folds for each of 8 candidates, totalling 40 fits
GridSearchCV 최고 평균 정확도 수치 : 0.8513
GirdSearchCV 최적 하이퍼 파라미터 : {'max_depth': 16}
'''
Python
복사
여기서 중요한 것은 트리 깊이를 증가함에 따라 예측 성능이 어떻게 변해가는지 확인하는 것이 우선이다. 이는 GridSearchCV 객체의 cv_results_ 속성을 통해 알 수 있다.
트리 깊이에 따른 평균 정확도 수치를 확인해보자.
# GridSearchCV 객체의 cv_results_ 속성을 데이터프레임으로 생성
cv_results_df = pd.DataFrame(grid_cv.cv_results_)
# max_depth 파라미터 값과 그때의 테스트 세트, 학습 데이터 세트의 정확도 수치 추출
cv_results_df[['param_max_depth','mean_test_score']]
'''
param_max_depth mean_test_score
0 6 0.850791
1 8 0.851069
2 10 0.851209
3 12 0.844135
4 14 0.847808
5 16 0.851344
6 20 0.850800
7 24 0.849440
'''
Python
복사
결과적으로는 깊이 16에서 예측 정확도가 정점으로 나온다.
이번에는 실제 test 데이터 세트에서 정확도를 측정해보겠다. 이번에도 트리 깊이의 변화에 따른 예측 정확도를 측정해볼 것이다.
max_depth=[6,8,10,12,14,16,20,24]
#max_depth 값을 변화시키면서 그때마다 학습과 테스트 세트에서의 예측 성능 측정
for depth in max_depth:
dt_clf = DecisionTreeClassifier(max_depth=depth,random_state=156)
dt_clf.fit(X_train,y_train)
pred = dt_clf.predict(X_test)
accuracy = accuracy_score(y_test,pred)
print('max_depth = {0} 정확도 : {1:.4f}'.format(depth,accuracy))
Python
복사
결과는 교차 검증에서의 최적 하이퍼 파라미터와 같다.
이제 max_depth 와 min_samples_split 를 같이 변화시켜보면서 튜닝을 해보자.
param = {
'max_depth':[8,12,16,20],
'min_samples_split':[16,24]}
grid_cv = GridSearchCV(dt_clf,param_grid=param,scoring='accuracy',cv=5,verbose=1) # 교차검증은 5
grid_cv.fit(X_train,y_train)
print('GridSearchCV 최고 평균 정확도 수치: {0:.4f}'.format(grid_cv.best_score_))
print('GridSearchCV 최적 하이퍼 파라미터:', grid_cv.best_params_)
'''
Fitting 5 folds for each of 8 candidates, totalling 40 fits
GridSearchCV 최고 평균 정확도 수치: 0.8549
GridSearchCV 최적 하이퍼 파라미터: {'max_depth': 8, 'min_samples_split': 16}
'''
Python
복사
이제, 다시 이번에는 테스트 데이터세트에 적용해보겠다.
best_df_clf = grid_cv.best_estimator_
pred1 = best_df_clf.predict(X_test)
accuracy = accuracy_score(y_test,pred1)
print('결정 트리 예측 정확도 : {0:.4f}'.format(accuracy))
'''
결정 트리 예측 정확도 : 0.8717
'''
Python
복사
마지막으로 각 피처의 중요도를 feature_importances_ 속성을 이용해 알아보자. 막대그래프로 표현하겠다.
import seaborn as sns
ftr_importances_values = best_df_clf.feature_importances_
#Top 중요도로 정렬을 쉽게 하고, 시본의 막대그래프로 쉽게 표현하기 위해 Series로 변환
ftr_importances = pd.Series(ftr_importances_values,index=X_train.columns)
# 중요도값 순으로 Series 정렬
ftr_top20 = ftr_importances.sort_values(ascending=False)[:20]
plt.figure(figsize=(8,6))
plt.title('Feature importances Top 20')
sns.barplot(x=ftr_top20, y=ftr_top20.index)
plt.show()
Python
복사
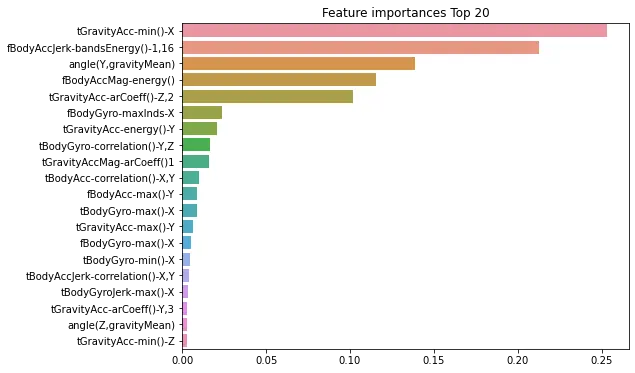
가장 높은 중요도를 가진 top 5의 피처들이 매우 중요하게 결정 트리 생성에 영향을 미치고 있는 것을 알 수 있다.