

이진 분류의 예측 성능 측정에서 중요하게 사용되는 지표다. False Positive Rate이 변할 때 True Positive Rate(재현율=민감도)가 어떻게 변하는지 나타내는 곡선이다.
민감도 또는 재현율과 대응되는 지표는 특이도다.
민감도 : 실제값 양성이 정확히 예측돼야 하는 수준을 나타낸다.
특이도 : 실제값 음성이 정확히 예측돼야 하는 수준을 나타낸다.
x축인 False Positive Rate는 ‘1-특이도’ (양성으로 잘못 분류된 음성 샘플의 비율)다.
ROC 곡선은 가운데 사선에 가까울수록 성능이 떨어지는 것이고 멀어질수록 성능이 좋은 것이다.
사이킷런은 roc_curve() API를 제공한다. 사용법은 precision_recall_curve()와 유사하다. 반환값은 FPR(1-특이도,즉 X축 값), TPR(민감도), 임계값으로 구성되어 있다.
•
입력 파라미터
◦
y_true : 실제 클래스 값
◦
y_score : predict_proba()의 반환값 배열에서 양의 칼럼의 예측 확률이 보통 사용된다. 또는 decision_function (예측 결정점수값) 의 값이 사용된다.
•
반환 값
◦
fpr : fpr값을 배열로 반환
◦
tpr : tpr값을 배열로 반환
◦
thresholds: threshold 값 배열
from sklearn.metrics import roc_curve
fpr, tpr , thresholds = roc_curve(y_train, y_scores)
Python
복사
타이타닉 생존자 예측 모델의 FPR, TPR, 임곗값을 roc_curve() 를 이용해서 구해보자.
from sklearn.metrics import roc_curve
pred_proba_class1 = lr_clf.predict_proba(X_test)[:,1]
fprs, tprs, thresholds = roc_curve(y_test,pred_proba_class1)
# 반환된 임곗값 배열에서 샘플로 데이터를 추출하되, 임곗값을 5 steps로 추출
# thresholds[0]는 max(예측확률)+1로 임의 설정됨. 이를 제외하기 위해 np.arange는 1부터 시작
thr_index = np.arange(1,thresholds.shape[0],5)
print('샘플 추출을 위한 임곗값 배열의 index:', thr_index)
print('샘플 index로 추출한 임곗값:', np.round(thresholds[thr_index],2))
# 5 step 단위로 추출된 임계값에 따른 fpr, tpr 값
print('샘플 임곗값별 fpr : ', np.round(fprs[thr_index],3))
print('샘플 임곗값별 tpr : ', np.round(tprs[thr_index],3))
Python
복사
이제 위의 결과를 roc 곡선으로 시각화하여 확인하자.
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
%matplotlib inline
def roc_curve_plot(y_test,pred_proba_c1):
# 임계값에 따른 fpr, tpr 값을 반환받음
fprs, tprs, thresholds = roc_curve(y_test,pred_proba_c1)
# ROC 곡선을 그래프 곡선으로 그림
plt.plot(fprs,tprs,label='ROC')
# 가운데 대각선 직선을 그림
plt.plot([0,1],[0,1], 'k--', label='Random')
# FPR x축의 Scale을 0.1 단위로 변경, x, y축 명 설정 등
start, end = plt.xlim()
plt.xticks(np.round(np.arange(start,end,0.1),2))
plt.xlim(0,1);plt.ylim(0,1)
plt.xlabel('FPR(1-Sensitivity)');plt.ylabel('TPR(Recall)')
plt.legend()
roc_curve_plot(y_test,pred_proba[:,1])
Python
복사
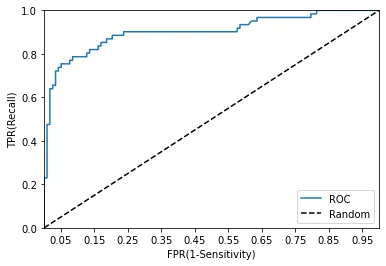
일반적으로 ROC는 FPR과 TPR의 변화를 살펴보는 데 사용하고, 분류의 성능 지표는 ROC 곡선의 밑 면적 AUC를 통해 평가한다.
AUC는 1에 가까울수록 좋은 성능을 나타낸다. 일반적으로 FPR의 작은 값에서 얼마나 큰 TPR을 얻을 수 있냐가 그를 대표한다.
보통 분류는 0.5 이상의 AUC값을 가진다.
from sklearn.metrics import roc_auc_score
pred_proba = lr_clf.predict_proba(X_test)[:,1]
roc_score = roc_auc_score(y_test, pred_proba)
print('ROC AUC 값: {0:.4f}'.format(roc_score))
'''
ROC AUC 값: 0.9024
'''
Python
복사
타이타닉 생존자 예측 로지스틱 회귀 모델의 점수는 약 0.90으로 측정됐다.
이제, 예측 성능 평가 지표 함수인 get_clf_eval() 함수에 이 지표를 추가하자. 참고로 다른 지표들과 다르게 roc_auc_score() 지표는 인자로 예측 확률값이 들어가기 때문에 get_clf_eval()함수의 인자를 조금 수정하였다.
def get_clf_eval(y_test, pred=None, pred_proba=None):
confusion = confusion_matrix(y_test,pred)
accuracy = accuracy_score(y_test,pred)
precision = precision_score(y_test,pred)
recall = recall_score(y_test,pred)
f1 = f1_score(y_test,pred)
# roc - auc 추가
roc_auc = roc_auc_score(y_test,pred_proba)
print('오차 행렬')
print(confusion)
# roc - auc print 추가
print('정확도:{0:.4f}, 정밀도:{1:.4f}, 재현율:{2:.4f}, f1 스코어:{3:.4f}, AUC : {4:.4f}'.format(accuracy,precision,recall,f1,roc_auc))
Python
복사