
말 그대로 이미지에 대한 데이터를 가지고 특정 사물을 분류하는 것이다.
< 퍼셉트론>
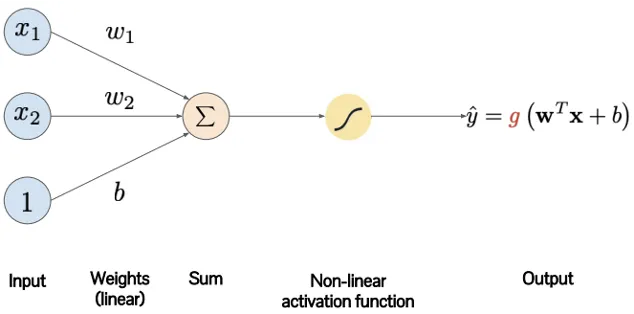
인간의 뉴런을 본뜬 모델.
1.
각 노드의 입력값과 가중치를 곱한 뒤 모두 합하여(가중합) 편향(b)를 더해준다.
2.
1의 값을 활성 함수(g)가 가지고 있는 임곗값과 비교한다.
3.
1의 값이 임곗값보다 크면 활성함수를 활성화시키고, 작으면 비활성화한다.
** 파라미터 : 가중치, 편향
but !! 위의 퍼셉트론은 어쨌든 단순 선형 분류기라는 한계때문에 복잡한 문제를 해결할 수 없다.
—> 대안으로 나온것이 퍼셉트론을 여러 층으로 쌓아올린 다층 퍼셉트론이다.
< 다층 퍼셉트론: MLP >

-구체적인 내용은 일단 생략-
MLP의 한계 : 고차원의 데이터를 입력받을 때 파라미터 수가 지나치게 많아진다는 한계 존재
ex) MNIST 이미지를 분류하는 경우, 각 데이터셋의 크기가 784개나 된다. 즉, 입력층만해도 784개의 뉴런으로 이뤄지고, 출력값은 0~9의 숫자 중 하나이므로 총 10개의 뉴런으로 이뤄진다.
예를들어, 다층 퍼셉트론에서 은닉층의 구조를 각각 2048과 1024개로 이루어진 총 3개의 층으로 정한다고 해보자. 다층 퍼셉트론은 한 층의 모든 뉴런이 다음 층의 모든 뉴런과 완전히 연결된 구조이기 때문에 필요한 파라미터 수를 계산하면 다음과 같이 된다.
( 784 * 2048 + 2048 )+ ( 2048 * 1024 + 1024 ) + ( 1024 * 10 + 10 ) = 3,716,106 개다.
—> 물론, 위의 식은 각 뉴런 층에서 하나의 편향값이 있다는 가정하에 계산한 것이다.
이렇게, 파라미터 수가 너무나도 많기 때문에 모델을 학습하는데 시간이 오래 걸릴뿐더러 과적합의 위험도 크다.
이미지 분류에서 과적합의 문제는
1.
이미지의 위치, 각도, 크기 변화에 취약하다.
2.
학습 데이터보다 파라미터 수가 많을 경우 과적합할 가능성이 크다.
결론적으로, 다층 퍼셉트론도 위와 같은 문제 때문에 대체된 모델이 바로 CNN(Convolutional Neural Network)이다.
1. CNN(Convolutional Neural Network)
인간의 시신경을 반영한 Convolution과 Pooling을 반복해 특징을 추출하고, 완전연결계층을 통해 입력된 이미지를 분류하기 위한 변별적 학습을 수행한다.
앞의 다층퍼셉트론을 보완했듯이 CNN은 학습해야할 전체 파라미터수를 감소시켜 빠른 학습 속도를 가지고 일반화에도 좋은 성능을 가지게 된다.
•
Convolutional kernel
: 시신경의 구조를 모방한 것이다. 시신경은 작은 수용영역을 가지며 수용 영역에 해당하는 시각 자극에만 반응해 단순한 특징을 추출하고, 그 정보들이 조합되어 뇌로 전달된다.
예를 들어, 육각형을 인지하는 시신경의 구조를 시각적으로 확인해보자.

앞서 말했듯이 작은 수용영역들(convolution filter) 이 존재하고 위의 그림에서는 우하향 대각선, 우상향 대각선과 수평선의 모양을 가진 수용 영역이 사용된다.
우하향 대각선 모양의 수용 영역은 육각형에서 우하향의 대각선을 추출하고(\), 우상향 대각선 모양의 수용 영역은 육각형의 우상향 대각선을(/), 그리고 수평선 모양의 수용 영역은 육각형에서 수평선을 추출한다(-). 마지막으로 이렇게 추출된 세개의 특징이 조합되어 뇌로 전달되어 뇌에서 육각형임을 인지하게 된다.
→ 위의 방식을 반영해서 convolution단계에서 다음과 같이 진행된다.
1.
우선 Convolution filter는 전체 이미지를 차례대로 움직이면서(Window sliding) 행렬 곱셈(Matrix multiplication)을 통해 특징 값을 추출한다.
2.
전체 이미지에서 특정 Filter의 모양과 일치하게 되면 그 부분에서 큰 값을 갖게 된다. → Filter가 전체 이미지를 순회하고 나면 전체 이미지에서 해당 Filter와 유사한 모양을 가진 부분에 대한 특징만 얻을 수 있다.
→ 결국, 추상적인 이미지의 특징을 여러 관점에서 추출해 위치에 무관한 특징을 추출할 수 있다.
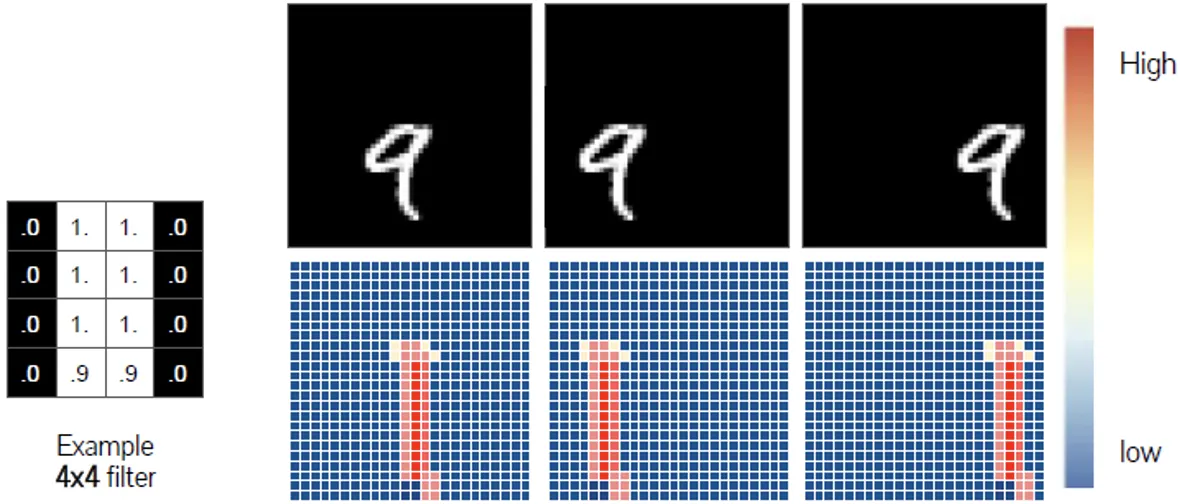
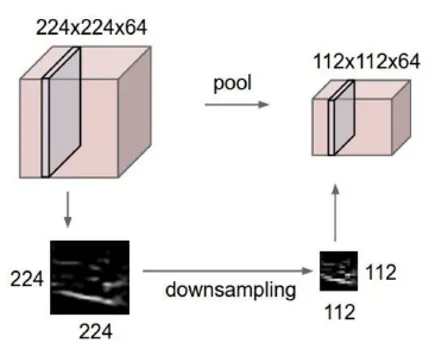
Pooling은 이미지의 특징을 유지하면서 차원을 축소한다. Max Pooling 은 convolution filter을 거친 결과로 얻은 각각의 feature map에서 특정 영역을 형성하여 해당 영역 내에서 가장 큰 값을 도출한다. Average Pooling은 같은 방법으로 평균값을 도출한다.

다음 그림을 살펴보면 Pooling 연산을 통해 기존 이미지의 크기는 축소되었지만 이미지의 특징은 그대로 유지되는 것을 확인할 수 있다.
이제, CNN구조를 활용한 다양한 이미지 분류 딥러닝 모델을 살펴보자.
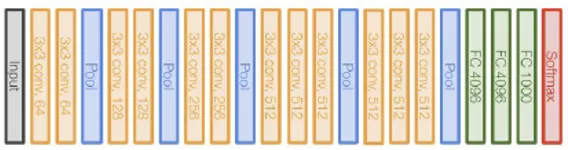
< VGG-16>
VGG-16은 옥스포드에서 개발한 모델이다. image2013 대회에서 97.2%로 우승했다.
구조는 CNN와 동일하게 convolution과 pooling을 반복한다. 마지막에는 완전연결층으로 구성된다.
<ResNet>
ResNet은 마이크로소프트에서 개발한 모델이다. ImageNet 2016 대회에서 96.4%의 정확도로 우승
했다. 마찬가지로 VGG-16과 같이 Convolution과 Pooling의 반복을 통해 특징을 추출하고, 마지막에 완전연결층을 통해 분류하는 것을 볼 수 있다.

하지만, VGG-16과 달리 이전 layer과 다음 layer을 이어주는 연결선이 존재하는 것을 확인할 수 있다.

참고! ResNet과 VGG-16의 구조를 비교하면, VGG-16 모델이 훨씬 적은 수의 층을 갖고 있어 훈련에 소요되는 시간이 훨씬 적다. 반면 정확도는 ResNet이 VGG-16보다 높다.
시간 효율 : VGG-16 > ResNet
정확도 : ResNet > VGG-16
< Residual Connection : skip connection>

이 연결선을 Residual Connection, 혹은 skip connection이라고 부른다. 왼쪽은 residual connection이 없는 일반적이 plain layers고, 오른쪽은 residual connection을 추가한 residual block이다. 두 구조의 차이점은 동일한 연산을 하고 난 다음 input x를 더하는 것과 더하지 않는 것의 차이다.
이를 통해, residual block에서는 기존에 학습한 정보를 보존하고 추가적으로 정보를 학습한다.
즉, 이전 Layer에서 학습했던 정보를 연결함으로써 해당 층에서는 추가적으로 학습해야할 정보만을 학습하면 되어 학습할 양이 감소한다.
<MobileNet>
구글에서 개발한 모델. 작은 사이즈에 최적화되어 있어 빠른 수행시간을 가져, 모바일 기기나 자원이 한정적인 기기에서 동작하기에 이상적이다. 하지만 작은 사이즈인 만큼, 정확도는 낮아 앞서 본 VGG-16과 ResNet 모델에 비해 정확도가 낮다.
< Custom CNN >
직접 CNN모델을 만들 수도 있다. 어떤 데이터셋을 사용하는지, 어떻게 이 모델을 활용하는지에 따라 자유롭게 Customize 할 수 있다는 장점이 있다.