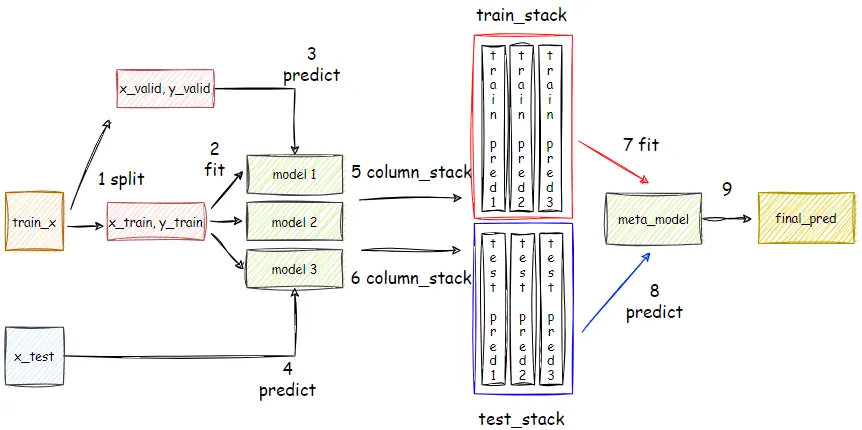
맨 앞에서 설명했지만, 스태킹은 여러 가지 다른 모델의 예측 결괏값을 다시 학습 데이터로 만들어서 다른 모델로 재학습시켜 결과를 예측하는 방법이다. 이렇게 개별 모델의 예측된 데이터 세트를 다시 기반으로 하여 학습하고 예측하는 방식을 메타 모델이라고 한다.
물론, 개별적인 여러 알고리즘을 서로 결합해 예측 결과를 도출한다는 점은 배깅과 부스팅과의 공통점이긴하다.
스태킹 모델은 두 종류의 모델이 필요하다. 첫 번째는 개별적인 기반 모델이고 두번째는 이 개별 기반 모델의 예측 데이터를 학습 데이터로 만들어서 학습하는 최종 메타 모델이다.
스태킹을 현실 모델에 적용하는 경우는 그렇게 많지 않지만, 조금이라도 성능 수치를 높여야 할 경우 자주 사용된다.
스태킹을 적용할 때는 많은 개별 모델이 필요하다. 2~3개의 개별 모델만을 결합해서는 쉽게 예측 성능을 향상시킬 수 없다. 또, 스태킹을 한다고 해서 반드시 성능이 향상되는 것도 아니다.
일반적으로 성능이 비슷한 모델을 결합해 좀 더 나은 성능 향상을 도출하기 위해 적용된다.
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier, ExtraTreesClassifier
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
submission = pd.read_csv('sample_submission.csv')
# 독립변수 / 종속변수 설정
train_x = train.drop(['index', 'type', 'quality'], axis = 1)
train_y = train['quality']
x_test = test.drop(['index', 'type'], axis = 1)
# 학습에는 x_train, y_train / 스태킹에는 x_valid, y_valid를 사용
x_train, x_valid, y_train, y_valid = train_test_split(
train_x, train_y, test_size = 0.5, random_state = 42
)
rf = RandomForestClassifier(n_estimators = 10)
gb = GradientBoostingClassifier(n_estimators = 10)
et = ExtraTreesClassifier(n_estimators = 10)
# 학습 데이터로 모델 학습
rf.fit(x_train, y_train)
gb.fit(x_train, y_train)
et.fit(x_train, y_train)
# 스태킹 학습에 사용할 데이터
pred1 = rf.predict_proba(x_valid)
pred2 = gb.predict_proba(x_valid)
pred3 = et.predict_proba(x_valid)
# 스태킹 예측에 사용할 데이터
test_pred1 = rf.predict_proba(x_test)
test_pred2 = gb.predict_proba(x_test)
test_pred3 = et.predict_proba(x_test)
# shape = (학습/ 테스트데이터의 개수, 모델의 수)
train_stack = np.column_stack((pred1,pred2,pred3))
test_stack = np.column_stack((test_pred1,test_pred2,test_pred3))
print(train_stack)
print(train_stack.shape) # (2749, 3)
# 메타 모델 정의 및 학습
meta_model = RandomForestClassifier(n_estimators = 10, random_state = 42)
meta_model.fit(train_stack, y_valid)
# 학습된 메타 모델을 사용하여 최종 예측 수행
final_pred = meta_model.predict(test_stack)
submission['quality'] = final_pred
submission.head()
Python
복사
기본 스태킹 모델
기본 스태킹 모델을 위스콘신 암 데이터 세트에 적용해보자. 데이터를 재로딩하고 학습데이터와 테스트데이터로 나눠보자.
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
cancer_data = load_breast_cancer()
X_data = cancer_data.data
y_label = cancer_data.target
X_train,X_test,y_train,y_test = train_test_split(X_data,y_label,test_size=0.2,random_state=0)
Python
복사
개별 모델은 KNN, 랜덤 포레스트, 결정 트리, 에이다부스트다. 최종 모델은 로지스틱회귀를 사용할 것이다.
# 개별 ML 모델 생성
knn_clf = KNeighborsClassifier(n_neighbors=4)
rf_clf = RandomForestClassifier(n_estimators=100,random_state=0)
dt_clf = DecisionTreeClassifier()
ada_clf = AdaBoostClassifier(n_estimators=100)
# 스태킹으로 만들어진 데이터 세트를 학습, 예측할 최종 모델
lr_final = LogisticRegression(C=10)# C는 class_weight를 의미.데이터에 가중치 설정. default=None
# 개별 모델들을 학습
knn_clf.fit(X_train,y_train)
rf_clf.fit(X_train,y_train)
dt_clf.fit(X_train,y_train)
ada_clf.fit(X_train,y_train)
# 학습된 개별 모델들이 각자 반환하는 예측 데이터 세트를 생성하고 개별 모델의 정확도 측정.
knn_pred = knn_clf.predict(X_test)
rf_pred = rf_clf.predict(X_test)
dt_pred = dt_clf.predict(X_test)
ada_pred = ada_clf.predict(X_test)
print('KNN 정확도: {0:.4f}'.format(accuracy_score(y_test,knn_pred)))
print('랜덤 포레스트 정확도 : {0:.4f}'.format(accuracy_score(y_test,rf_pred)))
print('결정 트리 정확도 : {0:.4f}'.format(accuracy_score(y_test,dt_pred)))
print('에이다부스트 정확도 : {0:.4f}'.format(accuracy_score(y_test,ada_pred)))
'''
KNN 정확도: 0.9211
랜덤 포레스트 정확도 : 0.9649
결정 트리 정확도 : 0.9123
에이다부스트 정확도 : 0.9561
'''
Python
복사
이제, 개별 알고리즘으로부터 예측된 예측값을 칼럼 레벨로 옆으로 붙여서 새로운 피처값으로 만들어, 최종 메타 모델인 로지스틱 회귀에서 학습 데이터로 재사용하겠다.
이때, 예측값들은 1차원 형태의 ndarray다. 따라서 일단 행 형태로 붙인 다음, 넘파이의 transpose()를 이용해 전치시킨 ndarray를 만들어주면 된다.
pred = np.array([knn_pred,rf_pred,dt_pred,ada_pred])
print(pred.shape)
# transpose를 이용해 행과 열의 위치 교환. 칼럼 레벨로 각 알고리즘의 예측 결과를 피처로 만듦.
pred = np.transpose(pred)
print(pred.shape)
'''
(4, 114)
(114, 4)
'''
Python
복사
이제, 위의 데이터를 가지고 최종 메타 모델인 로지스틱 회귀를 학습하고 예측 정확도를 측정해보자.
lr_final .fit(pred,y_test) # pred가 피처세트를 대신.
final = lr_final.predict(pred)
print('최종 메타 모델의 예측 정확도 : {0:.4f}'.format(accuracy_score(y_test,final)))
'''
최종 메타 모델의 예측 정확도 : 0.9737
'''
Python
복사
확실히 개별 모델의 예측 정확도보다 정확도가 향상되었다. 하지만, 항상 그런것은 아니니 유의하자!
CV 세트 기반의 스태킹
CV세트 기반의 스태킹 모델은 과적합을 개선하기 위해 최종 메타 모델을 위한 데이터 세트를 만들 때 교차 검증 기반으로 예측된 결과 데이터 세트를 이용한다.
기존의 최종 학습에서는 레이블 데이터 세트로 실제 테스트용 레이블 데이터 세트를 가지고 학습하기 때문에 과적합 문제가 발생할 수 있다.
CV세트 기반의 스태키은 개별 모델들이 각각 교차 검증으로 메타 모델을 위한 학습용 스태킹 데이터 생성과 예측을 위한 테스트용 스태킹 데이터를 생성한 뒤 이를 기반으로 메타 모델이 학습과 예측을 수행한다. —> 2단계의 스텝으로 구분한다.
1.
각 모델별로 원본 학습/테스트 데이터를 예측한 결과 값을 기반으로 메타 모델을 위한 학습용/테스트용 데이터를 생성한다.
2.
1에서 개별 모델들이 생성한 학습용 데이터를 모두 스태킹 형태로 합쳐서 메타 모델이 학습할 최종 학습용 데이터 세트를 생성한다. 마찬가지로 각 모델들이 생성한 테스트용 데이터를 모두 스태킹 형태로 합쳐서 메타 모델이 예측할 최종 테스트 데이터 세트를 생성한다. 메타 모델은 최종적으로 생성된 학습 데이터 세트와 원본 학습 데이터의 레이블 데이터를 기반으로 학습한 뒤, 최종적으로 생성된 테스트 데이터 세트를 예측하고, 원본 테스트 데이터의 레이블 데이터를 기반으로 평가한다.
먼저, 스텝1 부분을 코드로 구현해보자. get_stacking_base_datasets() 함수를 생성한다. 필요한 인자로는 개별모델의 Classifier 객체, 원본인 학습용 피처 데이터, 원본인 학습용 레이블 데이터, 원본인 테스트 피처 데이터, 그리고 k폴드의 개수다.
이 함수에서는 메타 모델을 위한 학습용 데이터와 테스트용 데이터를 새롭게 생성한다.
from sklearn.model_selection import KFold
from sklearn.metrics import mean_absolute_error # mae
# 개별 기반 모델에서 최종 메타 모델이 사용할 학습 및 테스트용 데이터를 생성하기 위한 함수.
def get_stacking_base_datasets(model,X_train_n,y_train_n,X_test_n,n_folds):
# 지정된 n_folds값으로 KFold 생성
kf = KFold(n_splits=n_folds, shuffle=False, random_state=0)
# 추후에 메타 모델이 사용할 학습 데이터 반환을 위한 넘파이 배열 초기화
train_fold_pred = np.zeros((X_train_n.shape[0],1))
test_pred = np.zeros((X_test_n.shape[0],n_folds))
print(model.__class__.__name__, 'model 시작')
for folder_counter, (train_index, valid_index) in enumerate(kf.split(X_train_n)):
# 입력된 학습 데이터에서 기반 모델이 학습/예측할 폴드 데이터 세트 추출
print('\t 폴드 세트: ', folder_counter, ' 시작 ')
X_tr = X_train_n[train_index]
y_tr = y_train_n[train_index]
X_te = X_train_n[valid_index]
# 폴드 세트 내부에서 다시 만들어진 학습 데이터로 기반 모델의 학습 수행.
model.fit(X_tr,y_tr)
# 폴드 세트 내부에서 다시 만들어진 검증 데이터로 기반 모델 예측 후 데이터 저장.
train_fold_pred[valid_index, :] = model.predict(X_te).reshape(-1,1)
# 입력된 원본 테스트 데이터를 폴드 세트내 학습된 기반 모델에서 예측 후 데이터 저장.
test_pred[:,folder_counter] = model.predict(X_test_n)
# 폴드 세트 내에서 원본 테스트 데이터를 예측한 데이터를 평균하여 테스트 데이터로 생성
test_pred_mean = np.mean(test_pred,axis=1).reshape(-1,1)
# train_fold_pred는 최종 메타 모델이 사용하는 학습 데이터, tesst_pred_mean은 테스트 데이터
return train_fold_pred, test_pred_mean
Python
복사
이제, 각 모델별로 위의 함수를 실행시켜 각각 학습용, 테스트용 데이터세트를 반환한다.
knn_train, knn_test = get_stacking_base_datasets(knn_clf,X_train,y_train,X_test,7)
rf_train, rf_test = get_stacking_base_datasets(rf_clf,X_train,y_train,X_test,7)
dt_train, dt_test = get_stacking_base_datasets(dt_clf,X_train,y_train,X_test,7)
ada_train, ada_test = get_stacking_base_datasets(ada_clf,X_train,y_train,X_test,7)
Python
복사
이제, 각 모델별 학습데이터와 테스트 데이터를 합쳐주면 된다. 넘파이의 concatenate()를 이용한다
concatenate는 여러 개의 넘파이 배열을 칼럼 혹은 로우 레벨로 합쳐주는 기능을 제공한다.
Stack_final_X_train = np.concatenate((knn_train,rf_train,dt_train,ada_train),axis=1)
Stack_final_X_test = np.concatenate((knn_test,rf_test,dt_test,ada_test),axis=1)
print('원본 학습 피처 데이터 shape:', X_train.shape, '원본 테스트 피처 shape:',X_test.shape)
print('스태킹 학습 피처 데이터 shape:', Stack_final_X_train.shape, '스태킹 테스트 피처 데이터 shape:', Stack_final_X_test.shape)
'''
원본 학습 피처 데이터 shape: (455, 30) 원본 테스트 피처 shape: (114, 30)
스태킹 학습 피처 데이터 shape: (455, 4) 스태킹 테스트 피처 데이터 shape: (114, 4)
'''
Python
복사
Stack_final_X_train 은 메타 모델이 학습할 학습용 피처 데이터 세트다. Stack_final_X_test은 메타 모델이 예측할 테스트용 피처 데이터 세트다.
이제 학습, 예측 및 평가를 진행한다.
lr_final.fit(Stack_final_X_train,y_train)
stack_final = lr_final.predict(Stack_final_X_test)
print('최종 메타 모델의 예측 정확도: {0:.4f}'.format(accuracy_score(y_test,stack_final)))
'''
최종 메타 모델의 예측 정확도: 0.9737
'''
Python
복사
여기까지는 개별 모델에 대해서 파라미터 튜닝을 하지는 않았다. 하지만, 실제로는 스태킹을 이루는 개별 모델들을 최적으로 파라미터를 튜닝한 다음 스태킹 모델을 만드는 것이 일반적이다.
따라서 스태킹 모델의 파라미터 튜닝은 개별 모델의 파라미터 튜닝을 의미하는 것이기도 하다.
스태킹 모델은 분류뿐만 아니라 회귀에도 적용 가능하다.
사이킷런 StackingClassifier
사이킷런을 사용한 스태킹 방식은 아래와 같이 간소화된다.
1.
개별 모델 정의
2.
메타 모델 정의
3.
StackingClassifier 모델 정의
4.
학습 데이터를 사용하여 StackingClassifier 모델을 학습
5.
학습된 모델을 사용하여 테스트 데이터에 대한 예측 수행
스태킹 앙상블을 사용할 때에는 KFold 교차 검증을 통해 데이터를 최대한 활용하여 특정 데이터셋에 과적합 되는 것을 방지하는 것이 일반적이다.
from sklearn.ensemble import StackingClassifier
estimators = [
('rf', RandomForestClassifier(n_estimators = 10)),
('gb', GradientBoostingClassifier(n_estimators = 10)),
('et', ExtraTreesClassifier(n_estimators = 10))
]
meta_model = RandomForestClassifier(n_estimators = 10, random_state = 42)
stacked_model = StackingClassifier(estimators = estimators,
final_estimator = meta_model, # final_estimator 의 기본값은 logistic regression
cv = 3)
# train_x, train_y는 전체 train 데이터를 의미합니다.
stacked_model.fit(train_x, train_y)
stack_pred = stacked_model.predict(x_test)
submission['quality'] = stack_pred
submission.head()
Python
복사