데이콘 - 와인 품질 분류 경진대회
와인 품질별로 몇개의 데이터가 있는지 확인하고자 한다.
# 파이썬 warning 무시
import warnings
warnings.simplefilter(action='ignore', category=FutureWarning)
# 시각화를 위한 라이브러리
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
# 한글 폰트를 사용하기 위한 코드
fe = fm.FontEntry(fname = 'NotoSansKR-Regular.otf', name = 'NotoSansKR')
fm.fontManager.ttflist.insert(0, fe)
plt.rc('font', family='NotoSansKR')
Python
복사
train['quality'].value_counts().sort_index()
Python
복사
3 26
4 186
5 1788
6 2416
7 924
8 152
9 5
Name: quality, dtype: int64
< 막대 그래프 시각화 >
x = train['quality'].value_counts().sort_index().index
y = train['quality'].value_counts().sort_index().values
plt.figure(figsize=(4,3), dpi=150)
plt.title('와인 품질 분포')
plt.xlabel('와인 품질')
plt.ylabel('갯수')
plt.bar(x,y)
plt.show()
Python
복사

등급(quality)에 따른 다른 피처들의 통계량 시각화
def make_plots(text:str):
plt.title(text + ' vs quality')
x = train.groupby('quality').mean().reset_index()['quality']
y = train.groupby('quality').mean().reset_index()[text]
plt.bar(x,y)
plt.show()
for col in train.groupby('quality').mean().reset_index().columns[2:-3]: # 2번째 컬럼 ~ 마지막에서 3번째 컬럼까지의 변수와 quality변수간의 막대그래프
make_plots(col)
Python
복사
변수간의 상관관계 - 상관행렬
import seaborn as sns
features = ['fixed acidity', 'volatile acidity', 'citric acid',
'residual sugar', 'chlorides', 'free sulfur dioxide',
'total sulfur dioxide', 'density', 'pH', 'sulphates', 'alcohol',
'type']
plt.figure(figsize=(10,5))
ax = sns.heatmap(train[list(features) + ['quality']].corr(), annot=True)
plt.show()
Python
복사

와인의 품질(quality)는 포도의 품종(type)에 영향을 받을까?
white = train[train['type'] == 'white']
red = train[train['type'] == 'red']
print('화이트 와인 데이터 개수 : ', white.shape[0])
print('레드와인 와인 데이터 개수 : ', red.shape[0])
Python
복사
화이트 와인 데이터 개수 : 4159
레드와인 와인 데이터 개수 : 1338
< 포도 품종별 품질 분포 시각화 - seaborn countplot
plt.style.use("ggplot")
sns.countplot(data=train, x='type', hue='quality')
plt.title("와인 type에 따른 품질등급별 데이터 개수")
plt.show()
Python
복사

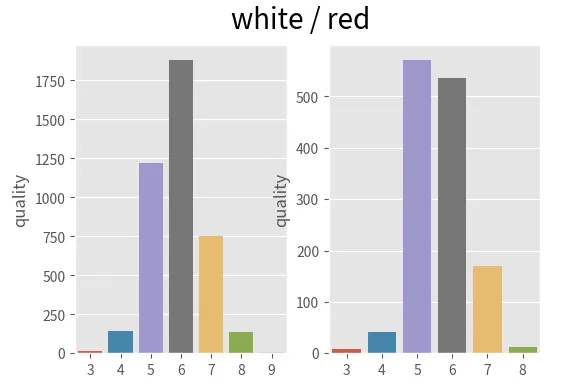
< 두 품종의 데이터 스케일 자체가 다르므로 따로 그래프를 그려보기 >
plt.style.use("ggplot")
plt.figure(figsize=(6,4))
plt.suptitle("white / red", fontsize=20)
## white
plt.subplot(1,2,1)
sns.barplot(x = white['quality'].value_counts().index, y = white['quality'].value_counts())
## red
plt.subplot(1,2,2)
sns.barplot(x = red['quality'].value_counts().index, y = red['quality'].value_counts())
plt.show()
Python
복사
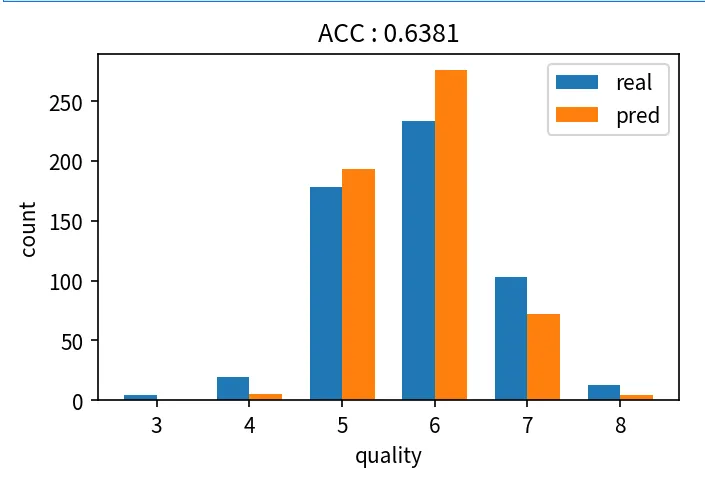
모델 검증(실제값 VS 예측값) 시각화
import numpy as np
##### 모델 검증 시각화 #####
def make_plot(y_true, pred):
acc = ACC(y_true, pred)
df_validation = pd.DataFrame({'y_true':y_true, 'y_pred':pred})
# 검증 데이터 정답지('y_true') 빈도수 (sorted)
df_validation_count = pd.DataFrame(df_validation['y_true'].value_counts().sort_index())
# 검증 데이터 예측치('y_pred') 빈도수 (sorted)
df_pred_count = pd.DataFrame(df_validation['y_pred'].value_counts().sort_index())
# pd.concat - 검증 데이타 정답지, 예측치 빈도수 합치기
df_val_pred_count = pd.concat([df_validation_count,df_pred_count], axis=1).fillna(0)
############################################################
# 그래프 그리기
############################################################
x = df_validation_count.index
y_true_count = df_val_pred_count['y_true']
y_pred_count = df_val_pred_count['y_pred']
width = 0.35
plt.figure(figsize=(5,3),dpi=150)
plt.title('ACC : ' + str(acc)[:6])
plt.xlabel('quality')
plt.ylabel('count')
p1 = plt.bar([idx-width/2 for idx in x], y_true_count, width, label='real')
p2 = plt.bar([idx+width/2 for idx in x], y_pred_count, width, label='pred')
plt.legend()
plt.show()
make_plot(y_valid, predict)
Python
복사