
0. 판다스 기본 체크 사항
버전 확인
pd.__version__
Python
복사
1. 데이터프레임
1-1. 데이터프레임 생성하기
•
리스트, 딕셔너리, 넘파이 배열로부터 데이터프레임을 만들 수 있다.
•
주요 요소로는
◦
데이터
◦
열 이름
◦
인덱스 이름
•
필수 요소는 데이터
import pandas as pd
Python
복사
# 1차원 리스트에서 생성
stock = [94500, 92100, 92200, 92300]
# 데이터프레임 만들기
df = pd.DataFrame(data=stock)
# 확인
df.head()
Python
복사
0 | |
0 | 94500 |
1 | 92100 |
2 | 92200 |
3 | 92300 |
# 2차원 리스트에서 생성
stock = [[94500, 92100, 92200, 92300],
[96500, 93200, 95900, 94300],
[93400, 91900, 93400, 92100],
[94200, 92100, 94100, 92400],
[94500, 92500, 94300, 92600]]
# 데이터프레임 만들기
df = pd.DataFrame(stock)
# 확인
df.head()
Python
복사
0 | 1 | 2 | 3 | |
0 | 94500 | 92100 | 92200 | 92300 |
1 | 96500 | 93200 | 95900 | 94300 |
2 | 93400 | 91900 | 93400 | 92100 |
3 | 94200 | 92100 | 94100 | 92400 |
4 | 94500 | 92500 | 94300 | 92600 |
# 데이터프레임만들 때 컬럼, 인덱스 이름 설정하기
stock = [[94500, 92100, 92200, 92300],
[96500, 93200, 95900, 94300],
[93400, 91900, 93400, 92100],
[94200, 92100, 94100, 92400],
[94500, 92500, 94300, 92600]]
dates = ['2019-02-15', '2019-02-16', '2019-02-17', '2019-02-18', '2019-02-19']
names = ['High', 'Low', 'Open', 'Close']
# 데이터프레임 만들기
df = pd.DataFrame(stock, columns=names, index=dates)
# 확인
df.head()
Python
복사
# 딕셔너리에서 데이터프레임 만들기
# 키 -> 열 이름
cust = {'Name': ['Gildong', 'Sarang', 'Jiemae', 'Yeoin'],
'Level': ['Gold', 'Bronze', 'Silver', 'Gold'],
'Score': [56000, 23000, 44000, 52000]}
df = pd.DataFrame(cust)
# 확인
df.head()
Python
복사
Name | Level | Score | |
0 | Gildong | Gold | 56000 |
1 | Sarang | Bronze | 23000 |
2 | Jiemae | Silver | 44000 |
3 | Yeoin | Gold | 52000 |
# 인덱스 설정하기
cust = {'Name': ['Gildong', 'Sarang', 'Jiemae', 'Yeoin'],
'Level': ['Gold', 'Bronze', 'Silver', 'Gold'],
'Score': [56000, 23000, 44000, 52000]}
# 데이터프레임 만들기(인덱스 지정함)
df = pd.DataFrame(cust, index=['C1','C2','C3','C4'])
# 확인
df.head()
Python
복사
Name | Level | Score | |
C1 | Gildong | Gold | 56000 |
C2 | Sarang | Bronze | 23000 |
C3 | Jiemae | Silver | 44000 |
C4 | Yeoin | Gold | 52000 |
~ 시리즈
•
열이 하나밖에 없는 형태
•
index와 value 만 있는 형태
# 데이터프레임에서 한 열만 가져오면 시리즈가 된다.
display(tip['smoker'])
Python
복사
67 Yes
92 Yes
111 No
172 Yes
149 No
...
182 Yes
156 No
59 No
212 No
170 Yes
Name: smoker, Length: 244, dtype: object
~ 데이터프레임 기본 정보 보기
# 행 수, 열 수 확인
df.shape
# 인덱스 확인
df.index
# 데이터 값 확인
df.values
# 열 확인
df.columns
# 열 자료형 확인
df.dtypes
# 열 자료형, 값 개수, 결측치 확인하기
df.info()
# 열 기술통계
df.describe() # 수치형 변수만 통계
df.describe().T
df.describe(include='object') # 문자형 변수만 통계 -> count / unique / top / freq
df.describe(include='all') # 모든 변수 통계
# 범주형 변수 고윳값 개수 확인하기
df['smoker'].value_counts()
df['smoker'].value_counts(normalize=True) # 비율로 표현하기
# 최빈값 확인하기
df['day'].mode()[0]
Python
복사
~ 데이터프레임 정보와 메모리 줄이기
•
usecols 파라미터를 사용해서 데이터 메모리 줄이기
데이터를 불러올 때, 사용할 변수들에 대한 데이터들만 가져오는 방법
cols = ['beer_servings', 'continent']
small_drinks = pd.read_csv('http://bit.ly/drinksbycountry', usecols=cols)
Python
복사
•
카테고리인 변수들은 object → category 로 타입 변환해주기
 전체 데이터의 개수에 비해 카테고리 수가 적을 경우에만 효과적이다
전체 데이터의 개수에 비해 카테고리 수가 적을 경우에만 효과적이다 dtypes = {'continent':'category'}
smaller_drinks = pd.read_csv('http://bit.ly/drinksbycountry', usecols=cols, dtype=dtypes)
Python
복사
~행 인덱스/열 이름 설정
•
데이터 프레임을 만들 때 생성하는 방법 :
pd.DataFrame( 2차원 배열, index = 행 인덱스 배열, columns = 열 이름 배열 )
df = pd.DataFrame([[15,'남','덕영중'],[17,'여','수리중']],
index=['준서','예은'],
columns=['나이','성별','학교'])
# 인덱스만 추출하기
print(df.index)
# 열 이름 추출하기
print(df.columns)
Python
복사
•
set_index() 메소드 사용하기 :
df.set_index( ’열 이름’, inplace=True)
~ 행/열 이름 변경
•
행 인덱스 변경 : df. rename( index = { 기존 인덱스 : 새 인덱스, ...})
◦
모든 행 인덱스 이름 변경 : df.index = [새로운 행 인덱스 배열]
•
열 이름 변경 : df. rename( columns = { 기존 이름 : 새 이름, ...})
◦
모든 열 이름 변경 : df.columns = [새로운 열 이름 배열]
df = pd.DataFrame([[15,'남','덕영중'],[17,'여','수리중']],
index=['준서','예은'],
columns=['나이','성별','학교'])
# 열 이름 중, '나이'를 '연령'으로, '성별'을 '남녀'로, '학교'를 '소속'으로 바꾸기(rename 사용)
df.rename(columns={'나이':'연령','성별':'나이','학교':'소속'},inplace=True)
# df의 행 인덱스 중에서 '준서'를 '학생1'으로, '예은'을 '학생2'로 바꾸기
df.rename(index={'준서':'학생1','예은':'학생2'}, inplace=True)
Python
복사
•
replace / add_prefix / add_suffix
변수 이름 바꾸기
# 변수에서 공백 제거하기
df.columns = df.columns.str.replace(' ','')
# 모든 변수의 첫머리에 접두사 붙이기
df.add_prefix('X_')
# 모든 변수의 말머리에 접미사 붙이기
df.add_suffix('_Y')
Python
복사
~ 행/열 추가
•
열 추가
◦
기존의 열이 있으면 변경 , 없으면 추가
# final_amt 열 추가: final_amt = total_bill + tip
tip['final_amt'] = tip['total_bill'] + tip['tip']
Python
복사
◦
원하는 위치에 열을 추가 : insert()
굳이 잘 쓰지 않음
# tip 열 앞에 div_tb 열 추가: div_tb = total_bill / size
tip.insert(1, 'div_tb', tip['total_bill'] / tip['size'])
Python
복사
~ 행/열 삭제
•
drop() 메소드
◦
행 삭제 : df. drop ( 행 인덱스 또는 배열, axis = 0 , inplace=True)
◦
열 삭제 : df. drop ( 열 이름 또는 배열, axis = 1, inplace=True)
▪
df.drop(columns=열이름 또는 배열, inplace=True)
◦
axis = 0 이 default
# 먼저 행 데이터부터 삭제해보겠다.
# DataFrame() 함수로 데이터프레임 변환. 변수 df에 저장
exam_data = {'수학':[90,80,70], '영어':[98,89,95],
'음악':[85,95,100],'체육':[100,90,90]}
df = pd.DataFrame(exam_data, index=['서준','우현','인아'])
# 데이터프레임 df를 복제해서 변수 df2에 저장. df2의 1개 행 삭제
df2 = df[:]
df2.drop('우현',inplace=True)
# 데이터프레임 df를 복제해서 변수 df3에 저장. df3의 2개 행 삭제
df3 = df[:]
df3.drop(['우현','인아'],inplace=True)
# df3.drop에 inplace=True라고 입력하는 대신 df3 = df3.drop()라고 해도 결과는 같다.
# 이제 열 데이터를 삭제해보겠다.
# 데이터프레임 df를 복제해서 df4와 df5를 만들고 진행한다.
df4 = df[:]
df5 = df[:]
df4.drop('수학', axis=1, inplace=True)
df5.drop(['영어','음악'],axis=1,inplace=True)
Python
복사
~ 데이터프레임 조회
조회하는 방식에는 loc과 iloc의 두 가지 방식이 존재한다.
•
인덱스 이름, 열 이름으로 선택 : loc
•
위치형 인덱스로 선택 : iloc
# total_bill 열 조회
tip.loc[:,['total_bill']] # tip[['total_bill']]
Python
복사
total_bill | |
0 | 16.99 |
1 | 10.34 |
2 | 21.01 |
3 | 23.68 |
4 | 24.59 |
... | ... |
239 | 29.03 |
240 | 27.18 |
241 | 22.67 |
242 | 17.82 |
243 | 18.78 |
244 rows × 1 columns
# tip, total_bill 열 조회
tip[['tip','total_bill']]
Python
복사
# 인덱스 5번까지 조회
tip.loc[:5,]
Python
복사
total_bill | tip | sex | smoker | day | time | size | |
0 | 16.99 | 1.01 | Female | No | Sun | Dinner | 2 |
1 | 10.34 | 1.66 | Male | No | Sun | Dinner | 3 |
2 | 21.01 | 3.50 | Male | No | Sun | Dinner | 3 |
3 | 23.68 | 3.31 | Male | No | Sun | Dinner | 2 |
4 | 24.59 | 3.61 | Female | No | Sun | Dinner | 4 |
5 | 25.29 | 4.71 | Male | No | Sun | Dinner | 4 |
열 범위 조회
loc을 이용할 경우, 범위 마지막 열도 포함된다.
# sex ~ time 열 조회
tip.loc[:,'sex':'time']
# 행 인덱스 4번까지, 모든 열 조회
tip.loc[:4,:]
Python
복사
iloc을 이용할 경우, 마지막 위치 인덱스에 해당하는 값은 포함하지 않는다.
tip.iloc[:,2:6] # 모든 행, 3열 ~ 6열의 데이터
tip[5:15] # 위치인덱스 5 ~ 14에 해당하는 행 추출
Python
복사
~ 조건으로 조회
loc 을 이용해서 조건을 만족하는 데이터만 조회할 수 있다.
•
조건은 행 자리에 온다.
•
조건을 변수로 선언해서 사용할 수 있다.
•
여러 조건을 넣을 때 & 또는 | 을 사용한다.
•
isin() , between() 메서드
◦
isin([값1,값2,…값n]) : 값1 또는 값2 또는 …값n 인 데이터만 조회
◦
between(값1, 값2) : 값1 ~ 값2까지의 범위안의 데이터만 조회
# tip 열 값이 6.0보다 큰 행 조회
tip.loc[tip['tip'] > 6.0] # tip[tip['tip'] > 6.0]
# 변수 = 조건
con = tip['tip'] > 6.0
tip.loc[con] # 또는 tip[con]
# and 로 여러 조건
tip.loc[(tip['tip'] > 6.0) & (tip['day'] == 'Sat')] # 또는 tip[(tip['tip'] > 6.0) & (tip['day'] == 'Sat')]
# or로 여러 조건
con1 = tip['tip'] > 6.0
con2 = tip['day'] == 'Sat'
tip.loc[con1 | con2] # tip[con1 | con2]
# isin 메서드
# day가 Sat 또는 Sun
tip.loc[tip['day'].isin(['Sat','Sum'])] # tip[tip['day'].isin(['Sat','Sum'])]
# between 메서드
# 범위 지정 ( 1 <= size <= 3)
tip.loc[tip['size'].between(1,3)] # tip[tip['size'].between(1,3)]
Python
복사
~ 열 선택
열 데이터를 1개만 선택할 때는 [ ] 안에 열 이름을 따옴표와 함께 입력하거나 ‘.’ 다음에 열 이름을 입력하는 두 가지 방식을 사용한다.
•
열 1 개 선택 : df [” 열 이름 ”] 또는 df.열이름 —> 시리즈로 반환
•
열 여러개 선택 : df [ [열1, 열2, 열3, ...] ] —> 데이터프레임으로 반환
먼저, 열 1개를 선택하는 방법부터 보자.
# '수학' 점수 데이터만 선택. 변수 math1에 저장
math1 = df['수학']
print(math1)
print(type(math1))
print('\n')
서준 90
우현 80
인아 70
Name: 수학, dtype: int64
<class 'pandas.core.series.Series'>
# '영어' 점수 데이터만 선택. 변수 english에 저장
english = df.영어
print(english)
print(type(english))
서준 98
우현 89
인아 95
Name: 영어, dtype: int64
<class 'pandas.core.series.Series'>
Python
복사
이제 2개 이상의 열을 추출하는 방법을 해보자.
# 이제, 2개 이상의 열을 추출하는 방법을 해보자.
# '음악','체육' 점수 데이터를 선택. 변수 music_gym에 저장
music_gym = df[['음악','체육']]
print(music_gym)
print(type(music_gym))
print('\n')
음악 체육
서준 85 100
우현 95 90
인아 100 90
<class 'pandas.core.frame.DataFrame'>
# '수학' 점수 데이터만 선택. 변수 math2에 저장
math2 = df[['수학']]
print(math2)
print(type(math2))
수학
서준 90
우현 80
인아 70
<class 'pandas.core.frame.DataFrame'>
Python
복사
범위 슬라이싱의 고급 활용을 살펴보자. 슬라이싱은 간격을 지정할 수 있다. default는 1이다.
# df의 모든 행에 대해서 0행부터 2행 간격으로 선택하려면 다음과 같이 한다.
df.iloc[::2]
수학 영어 음악 체육
서준 90 98 85 100
인아 70 95 100 90
# 0행부터 2행까지 2행간격으로 선택하려면 다음과 같이 한다.
df.iloc[0:3:2]
수학 영어 음악 체육
서준 90 98 85 100
인아 70 95 100 90
# 역순으로 인덱싱하려면 간격에 '-' 부호를 붙인다. 모든 행을 역순으로 정렬은 다음과 같이 한다.
df.iloc[::-1]
Python
복사
~ 원소 선택
데이터프레임의 행 인덱스와 열 이름을 [행, 열] 형식의 2차원 좌표로 입력해서 원소 위치를 지정하는 방법이다. 앞의 행 선택 방법처럼 iloc 또는 loc을 사용한다.
참고로 1개의 행과 2개 이상의 열을 선택하거나 2개 이상의 행과 1개의 열을 선택하는 경우 시리즈 객체가 반환된다.
2개 이상의 행과 2개 이상의 열을 선택하면 데이터프레임 객체가 반환된다.
•
인덱스 이름 : df.loc[행 인덱스, 열 이름]
•
위치 인덱스 : df.iloc[행 번호, 열 번호]
# DataFrame() 함수로 데이터프레임 변환. 변수 df에 저장
exam_data = {'이름':['서준','우현','인아'],
'수학':[90,80,70],
'영어':[98,89,95],
'음악':[85,95,100],
'체육':[100,90,90]}
df = pd.DataFrame(exam_data)
# '이름' 열을 새로운 행 인덱스로 지정하고, df객체에 변경 사항 반영
df.set_index('이름', inplace=True)
print(df)
수학 영어 음악 체육
이름
서준 90 98 85 100
우현 80 89 95 90
인아 70 95 100 90
# df의 특정 원소 1개 선택('서준'의 '음악' 점수)
a = df.loc['서준','음악']
print(a)
b = df.iloc[0,2]
print(b)
85
85
# df의 특정 원소 2개 이상 선택('서준'의 '음악','체육' 점수)
c = df.loc['서준',['음악','체육']]
print(c)
d = df.iloc[0,2:]
print(d)
e = df.loc['서준','음악':'체육']
print(e)
f = df.iloc[0,[2,3]]
print(f)
# 모두 아래의 결과와 같다.
음악 85
체육 100
Name: 서준, dtype: int64
# 행 인덱스와 열 이름을 각각 2개 이상 선택하여 데이터프레임 얻기
# df 2개 이상의 행과 열에 속하는 원소 선택('서준','우현'의 '음악','체육' 점수)
g = df.loc[['서준','우현'],['음악','체육']]
print(g)
h = df.iloc[[0,1],[2,3]]
print(h)
i = df.loc['서준':'우현', '음악':'체육']
print(i)
j = df.iloc[0:2,2:]
print(j)
# 모두 아래의 결과와 같다.
음악 체육
이름
서준 85 100
우현 95 90
# 이외에도 열을 선택하는 다양한 방법이 있다.
df.loc[:, ['음악','체육']] # 모든 행에 대해 '음악'과 '체육' 열 추출
df.iloc[:,[2,3]] # 위와 같은 결과
df.iloc[:,2:4] # 슬라이싱으로 추출.
# 모두 아래의 결과와 같다.
음악 체육
이름
서준 85 100
우현 95 90
인아 100 90
Python
복사
~ 열 추가
열 추가 : df[ ‘ 추가하려는 열 이름 ‘] = 데이터 값
이때, 모든 행에 대해 동일한 값이 입력이 됨을 유의하자.
# 데이터프레임 df에 '국어'점수 열 추가. 데이터 값은 80으로 지정
df['국어'] = 80
print(df)
수학 영어 음악 체육 국어
이름
서준 90 98 85 100 80
우현 80 89 95 90 80
인아 70 95 100 90 80
Python
복사
~ 행 추가
추가하려는 행 이름과 데이터 값을 loc 인덱서를 사용하여 입력한다.
행 추가 : df.loc[’ 새로운 행 이름 ‘] = 데이터 값 ( 또는 배열 )
새로운 행 인덱스를 추가할 때는 기존 행 인덱스와 곂치지 않는 인덱스여야 한다. 행 추가는 항상 맨 밑에 추가된다. 따라서 인덱스의 순서에 꼭 맞출 필요는 없다.print(df)
수학 영어 음악 체육 국어
이름
서준 90 98 85 100 80
우현 80 89 95 90 80
인아 70 95 100 90 80
# 새로운 행 추가 - 같은 원소 값 입력
df.loc[3]=0
print(df)
수학 영어 음악 체육 국어
이름
서준 90 98 85 100 80
우현 80 89 95 90 80
인아 70 95 100 90 80
3 0 0 0 0 0
# 새로운 행 추가 - 원소 값 여러 개의 배열 입력
df.loc[4] = ['동규',90,80,70,60]
print(df)
수학 영어 음악 체육 국어
이름
서준 90 98 85 100 80
우현 80 89 95 90 80
인아 70 95 100 90 80
3 0 0 0 0 0
4 동규 90 80 70 60
# 새로운 행 추가 - 기존 행 복사
df.loc['행5'] = df.loc[3]
수학 영어 음악 체육 국어
이름
서준 90 98 85 100 80
우현 80 89 95 90 80
인아 70 95 100 90 80
3 0 0 0 0 0
4 동규 90 80 70 60
행5 0 0 0 0 0
Python
복사
~ 원소 값 변경
특정 원소를 선택하고 새로운 데이터 값을 지정해주면 원소 값이 변경된다. 원소 1개를 변경할 수도 여러 개를 변경할 수도 있다. 방법은 인덱싱이나 슬라이싱기법을 사용하면 된다.
•
원소 값 변경 : df객체의 일부분 또는 원소를 선택 = 새로운 값
# 원소 값 변경
# 데이터프레임의 특정 원소를 선택하고 새로운 값을 지정해주면 원소값이 변경
# 당연히 하나의 원소를 바꿀수도 여러 개의 원소를 바꿀 수도 있다.
# 원소 선택은 데이터프레임의 인덱싱과 슬라이싱 방법을 사용하면 된다.
# '서준' 학생의 '체육' 점수를 선택하는 여러 방법을 시도해 본다.
# 비교하기 위해 각기 다른 점수를 새로운 값으로 입력하여 변경한다.
# '이름' 열을 새로운 인덱스로 지정하고, df 객체에 변경사항 반영
df.set_index('이름',inplace=True)
print(df)
수학 영어 음악 체육
이름
서준 90 98 85 100
우현 80 89 95 90
인아 70 95 100 90
# '서준'의 '체육' 점수 변경
df.iloc[0,3] = 80
print(df)
수학 영어 음악 체육
이름
서준 90 98 85 80
우현 80 89 95 90
인아 70 95 100 90
# 위와 같은 방식
df.iloc[0][3]=80
df.loc['서준']['체육']=80 # 또는 df.loc['서준','체육']=80
# 데이터프레임 df의 원소 여러 개를 변경하는 방법 : '서준'의 '음악','체육' 점수
df.loc['서준',['음악','체육']] = 50
print(df)
수학 영어 음악 체육
이름
서준 90 98 50 50
우현 80 89 95 90
인아 70 95 100 90
df.loc['서준',['음악','체육']]=100,50 # 각 다른 값으로 변경
print(df)
수학 영어 음악 체육
이름
서준 90 98 100 50
우현 80 89 95 90
인아 70 95 100 90
Python
복사
~ 원소 값 변경 - map()
•
범주형 값을 다른 값으로 변경할 때 사용한다.
•
mapping 되지 않은 값들은 결측치로 바뀌게 된다.

# Male -> 1, Female -> 0
tip['sex'] = tip['sex'].map({'Female':0, 'Male':1})
Python
복사
~ 원소 값 변경 - replace()
•
map() 메서드와 동일한 코드로 사용된다.
•
mapping되지 않은 값은 기존값으로 남게 된다.

# 1 --> Male, 0 --> Female
tip['sex'] = tip['sex'].replace({1: 'Male', 0: 'Female'})
Python
복사
~ 원소 값 변경 - np.where()
•
np.where(조건문, 조건이 참일때 값, 조건이 거짓일때 값)
•
결과는 map 과 동일
titanic['Sex'] = np.where(titanic['Sex'] == 'male', 1, 0)
Python
복사
~ 범주값 만들기
•
연속값을 구간을 나누어 범주값으로 표현한다.
•
cut() , qcut() 함수를 사용한다.
•
데이터가 단순해져 모델 성능에 도움이 될 수 있다.
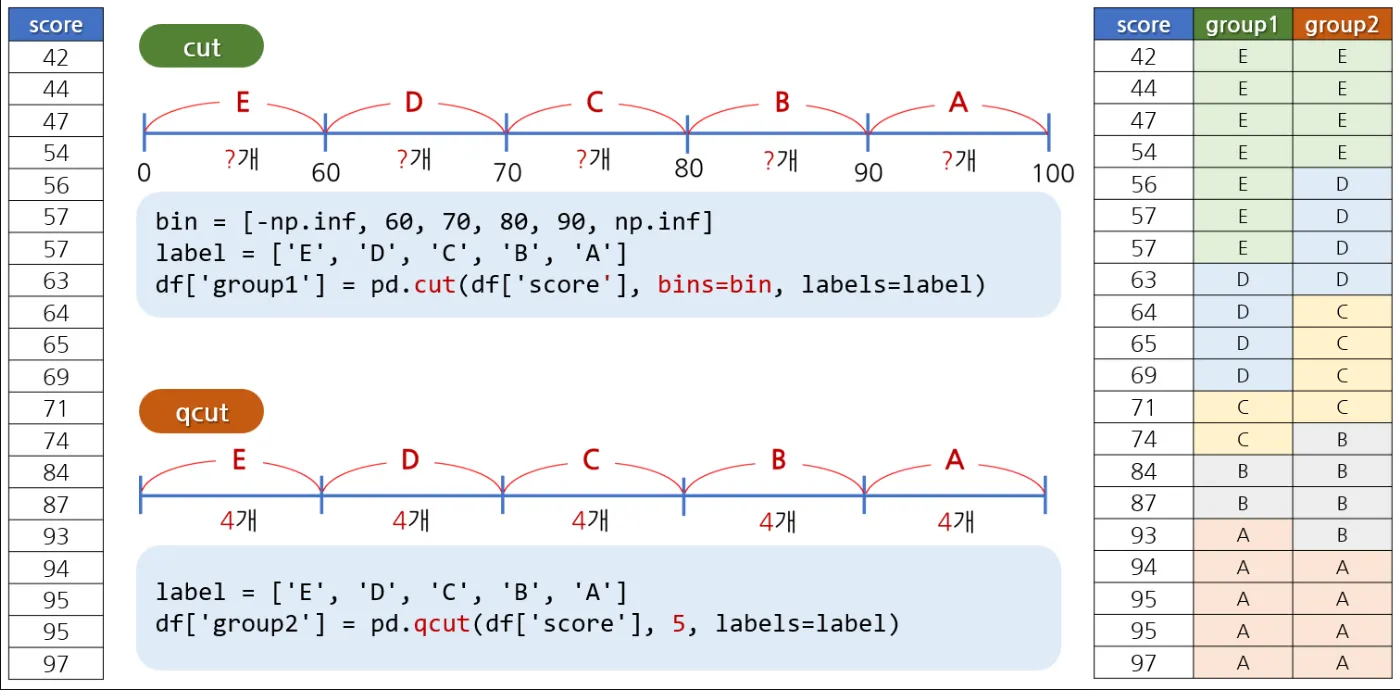
1.
cut()
a.
경계값을 기준으로 구간을 나누고 싶을 때 사용한다.
b.
구간 개수를 지정하면 자동으로 경계값을 기준으로 나누게 된다.
c.
include_lowest = True 로 지정하면, 맨 밑 구간의 가장 작은 값을 포함시킬 수 있다.
# 등급 구하기
bin = [-np.inf, q1, q2, q3, np.inf]
label = list('abcd')
tip['bill_grp'] = pd.cut(tip['total_bill'], bins=bin, labels=label)
Python
복사
2.
qcut()
a.
개수를 기준으로 구간을 나누고 싶을 때 사용한다.
b.
구간 개수를 지정하면 자동으로 동일한 개수를 갖는 구간이 만들어진다.
# 같은 개수의 total_bill을 갖는 4개 구간으로 나누기
tip['bill_grp2'] = pd.qcut(tip['total_bill'],4,labels=list('abcd'))
Python
복사
~ 행, 열의 위치 바꾸기
행과 열을 서로 맞바꾸는 방법이다. 전치행렬과 같은 개념이다. 전치시키면 새로운 객체로 반환하기 때문에 이때는 inplace 방법으로 원본을 바꾸지 못하고 df = df.transpose() 또는 df = df.T 이렇게 해줘야 한다.
행, 열 바꾸기 : df.transpose() 또는 df.T
# df를 전치하기(메소드 활용)
print(df)
df = df.transpose()
print(df)
수학 영어 음악 체육
이름
서준 90 98 100 50
우현 80 89 95 90
인아 70 95 100 90
이름 서준 우현 인아
수학 90 80 70
영어 98 89 95
음악 100 95 100
체육 50 90 90
# 다시 전치시키기(클래스 속성 활용)
df = df.T
print(df)
수학 영어 음악 체육
이름
서준 90 98 100 50
우현 80 89 95 90
인아 70 95 100 90
Python
복사
~ 변수 type 확인하기
df.dtypes
Python
복사

# 수치형 변수들만 확인 (정수 + 실수형 변수 모두 출력)
df.select_dtypes(include='number')
# 문자형 변수만 확인
df.select_dtypes(include='object')
# multiple 변수 타입 모두 포함
df.select_dtypes(include=['number','object','category','datetime'])
# 특정 데이터 타입 제외하고 출력
df.select_dtypes(exclude='number')
Python
복사
~변수 타입 변환해주기
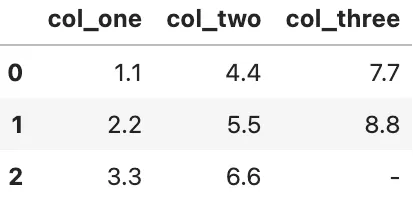
•
astype
df.astype({'col_one':'float', 'col_two':'float'})
Python
복사
•
to_numeric
결측치가 포함되어 있거나, astype 으로 변경 불가능한 기호가 포함되어 있을 경우, error 가 발생하는데, 이를 대처하기 위한 방안으로 to_numeric 을 사용한다.
# coerce 는 error 가 발생하는 곳에 NaN 값으로 대체한다
pd.to_numeric(df.col_three, errors='coerce')
# 이후에 fillna() 를 이용해서 결측치에 적절한 값을 채워넣는다.
pd.to_numeric(df.col_three, errors='coerce').fillna(0)
# apply 함수를 이용해서 모든 변수에 적용할 수 있음
df = df.apply(pd.to_numeric, errors='coerce').fillna(0)
Python
복사
~기본 통계 메서드 사용
axis = 0 : 행 방향 으로 집계
axis = 1 : 열 방향으로 집계
•
df.sum
df.sum(axis=0) # 열 기준 합
df.sum(axis=0, numeric_only=True) # 수치형 변수 기준 합
df.sum(axis=1) # 행 기준 합
df['변수1'].sum() # 변수1 합계
Python
복사
•
df.max
df['변수1'].max() # 변수1 최댓값
Python
복사
•
df.mean
df[['변수1', '변수2']].mean() # 변수1, 변수2 평균
Python
복사
•
df.median
df[['변수1','변수2']].median() # 변수1, 변수2 중앙값
Python
복사
2. 인덱스 활용
~ 특정 열을 행 인덱스로 설정
set_index() 메소드를 사용해서 특정 열을 행 인덱스로 설정한다. 원본 객체에 반영하려면 inplace=True를 지정해준다.
•
특정 열을 행 인덱스로 설정 : df.set_index( ‘열 이름’ 또는 [ ‘열 이름’ ] )
# 데이터프레임 df의 '이름'열을 행 인덱스로 설정하면 새로운 데이터프레임이 만들어진다.
ndf = df.set_index(['이름']) # df.set_index('이름')
print(ndf)
수학 영어 음악 체육
이름
서준 90 98 85 100
우현 80 89 95 90
인아 70 95 100 90
# 인덱스로 설정할 때 두개의 열을 행 인덱스로 지정할 수도 있다.이를 멀티인덱스라고 한다.
ndf3 = ndf.set_index(['수학','음악'])
print(ndf3)
영어 체육
수학 음악
90 85 98 100
80 95 89 90
70 100 95 90
Python
복사
인덱스 이름 삭제
인덱스 이름은 특별히 사용할 일이 없어서 삭제하는 것이 좋다.
df.index.name = None
Python
복사
~ 행 인덱스 재배열
reindex() 메소드를 사용하면 행 인덱스를 새로운 배열로 재지정할 수 있다. 원본 객체에 반영하려면 inplace=True 로 지정해준다.
•
새로운 배열로 행 인덱스를 재지정 : df.reindex( 새로운 인덱스 배열 )
기존 데이터프레임에 존재하지 않는 행 인덱스가 새롭게 추가되는 경우 그 행의 데이터 값은 NaN 값이 입력된다.dict_data = {'c0':[1,2,3], 'c1':[4,5,6],'c2':[7,8,9],'c3':[10,11,12],'c4':[13,14,15]}
# 딕셔너리를 데이터프레임으로 변환. 인덱스를 [r0, r1, r2]로 지정
df = pd.DataFrame(dict_data, index=['r0','r1','r2'])
print(df)
c0 c1 c2 c3 c4
r0 1 4 7 10 13
r1 2 5 8 11 14
r2 3 6 9 12 15
# 인덱스를 [r0,r1,r2,r3,r4] 로 재지정
new_index = ['r0','r1','r2','r3','r4']
ndf = df.reindex(new_index)
print(ndf)
c0 c1 c2 c3 c4
r0 1.0 4.0 7.0 10.0 13.0
r1 2.0 5.0 8.0 11.0 14.0
r2 3.0 6.0 9.0 12.0 15.0
r3 NaN NaN NaN NaN NaN
r4 NaN NaN NaN NaN NaN
# reindx로 발생한 NaN 값을 숫자 0으로 채우기 (fill_value 옵션 사용)
ndf2 = df.reindex(new_index,fill_value=0)
print(ndf2)
c0 c1 c2 c3 c4
r0 1 4 7 10 13
r1 2 5 8 11 14
r2 3 6 9 12 15
r3 0 0 0 0 0
r4 0 0 0 0 0
Python
복사
~ 행 인덱스 초기화
•
reset_index() 메소드를 활용하면 행 인덱스를 위치 인덱스로 초기화한다.
•
기존 행 인덱스는 열로 이동한다.
•
다른 경우와 마찬가지로 새로운 데이터프레임 객체를 반환한다.
◦
inplace=True 설정해주면, 원본이 변경된다.
•
drop=True 를 지정해주면, 열로 이동된 기존의 행 인덱스를 삭제할 수 있다.
◦
일반적으로 여러 전처리 후에 기존의 인덱스가 뒤죽박죽 되었을 때 초기화해준다.
print(df)
c0 c1 c2 c3 c4
r0 1 4 7 10 13
r1 2 5 8 11 14
r2 3 6 9 12 15
# 행 인덱스를 정수형으로 초기화
# 기존 인덱스가 열로 이동
ndf = df.reset_index() # drop=False(default)
print(ndf)
index c0 c1 c2 c3 c4
0 r0 1 4 7 10 13
1 r1 2 5 8 11 14
2 r2 3 6 9 12 15
# 인덱스를 초기화한 뒤, 기존 인덱스는 제거
ndf2 = df.reset_index(drop=True)
print(ndf2)
index c0 c1 c2 c3 c4
0 1 4 7 10 13
1 2 5 8 11 14
2 3 6 9 12 15
# index 라는 이름의 열을 적절하게 변경한다.
ndf2.rename(columns={'index':'변수1'}, inplace=True)
변수1 c0 c1 c2 c3 c4
0 1 4 7 10 13
1 2 5 8 11 14
2 3 6 9 12 15
Python
복사
~ 데이터프레임 정렬
•
행 인덱스 기준 정렬 : df.sort_index()
ndf = df.sort_index(ascending=False)
print(ndf)
c0 c1 c2 c3 c4
r2 3 6 9 12 15
r1 2 5 8 11 14
r0 1 4 7 10 13
Python
복사
•
특정 열을 기준으로 정렬 : df.sort_values(by = ‘열 이름’)
# c1 열을 기준으로 내림차순 정렬
ndf = df.sort_values('c1',ascending=False)
print(ndf)
c0 c1 c2 c3 c4
r2 3 6 9 12 15
r1 2 5 8 11 14
r0 1 4 7 10 13
# 복합 열 정렬
tip.sort_values(['total_bill','tip'])
# 복합 열에 대해 다르게 정렬
tip.sort_values(['total_bill','tip'], ascending=[False,True])
Python
복사
•
데이터 순서 reverse 하기
df.loc[::-1]
# reverse한 뒤, 행 인덱스 재설정해주기
df.loc[::-1].reset_index(drop=True)
Python
복사
•
열 순서 reverse 하기
df.loc[:,::-1]
Python
복사
3. CSV 파일
•
보통 분석용 데이터는 csv 파일로 읽어온다.
•
pd.read_csv 함수를 사용한다.
•
데이터프레임 형태로 읽어온다.
read_csv 주요 옵션
•
sep : 구분자 지정(default = ‘,’)
•
header : 헤더가 될 행 번호 지정(default = 0)
•
index_col : 인덱스 열 지정(default = False)
•
names : 열 이름으로 사용할 문자열 리스트
•
encoding : 인코딩 방식을 지정
인코딩 오류
한글이 포함된 파일을 읽을 때 UnicodeDecodeError: 'utf-8' codec can't decode byte 0xb1 in position 0: invalid start byte 오류가 발생하면, encoding = ‘cp949’ 로 지정하기
# 데이터를 읽어들일 때 인덱스 설정
# 기존 열 중 하나를 인덱스로 설정
temp = pd.read_csv(path, index_col='month')
Python
복사
# 데이터를 읽어들인 후, 인덱스 설정
df.set_index('year', inplace=True)
Python
복사
4. 산술연산
판다스 객체의 산술연산은 3단계 프로세스를 거친다. 행/열 인덱스를 기준으로 모든 원소를 정렬한다. 동일한 위치에 있는 원소끼리 일대일로 대응시킨다. 일대일 대응이 되는 원소끼리 연산을 처리한다. 대응되는 원소가 없으면 NaN 처리한다.
~ 시리즈 VS 숫자
시리즈 객체에 어떤 숫자를 더하면 시리즈의 개별 원소에 각각 숫자를 더하고 계산한 결과를 시리즈 객체로 반환한다.
# 딕셔너리 데이터로 판다스 시리즈 만들기
student1 = pd.Series({'국어':100,'영어':80, '수학':90})
print(student1)
국어 100
영어 80
수학 90
dtype: int64
# 학생의 과목별 점수를 200으로 나누기
percentage = student1/200
print(percentage)
국어 0.50
영어 0.40
수학 0.45
print(type(percentage))
<class 'pandas.core.series.Series'>
Python
복사
~ 시리즈 vs 시리즈
시리즈와 시리즈사이에 사칙연산을 처리하는 방법이다. 시리즈의 모든 인덱승 대하여 같은 인덱스를 가진 원소끼리 계산한다. 인덱스에 연산 결과를 매칭하여 새 시리즈를 반환한다.
•
시리즈와 시리즈 연산 : Series1 + 연산자 + Series2
# 딕셔너리 데이터로 판다스 시리즈 만들기
student1 = pd.Series({'국어':100,'영어':80,'수학':90})
student2 = pd.Series({'수학':80,'국어':90,'영어':80})
print(student1)
국어 100
영어 80
수학 90
dtype: int64
print(student2)
수학 80
국어 90
영어 80
dtype: int64
# 두 학생의 과목별 점수로 사칙연산 수행
addition = student1 + student2 # 덧셈
substraction = student1 - student2 # 뺄셈
multiplication = student1 * student2 # 곱셈
division = student1 / student2 # 나눗셈
print(type(division))
<class 'pandas.core.series.Series'>
# 사칙연산 결과를 데이터프레임으로 합치기(시리즈 -> 데이터프레임)
result = pd.DataFrame([addition,substraction,multiplication,division], index=['덧셈','뺄셈','곱셈','나눗셈'])
print(result)
국어 수학 영어
덧셈 190.000000 170.000 160.0
뺄셈 10.000000 10.000 0.0
곱셈 9000.000000 7200.000 6400.0
나눗셈 1.111111 1.125 1.0
# 물론 두 시리즈는 인덱스의 순서가 다르지만 판다스는 같은 인덱스를 알아서 찾아
# 정렬하고 같은 인덱스의 데이터값끼리 사칙연산을 수행한다.
# 문제는 두 시리즈의 원소 개수가 다를수도, 원소의 개수는 같지만 인덱스 값이 다를 수 있다.
# 이럴 경우에는 정상적으로 연산을 수행할 수 없다. NaN 으로 출력한다.
# 인덱스도 동일하고 원소의 개수가 같아도 값에 NaN이 있는 경우 연산을 수행하면 NaN이 출력된다.
# numpy 라이브러리를 불러온다. nan 값을 만들기 위해
import numpy as np
# 딕셔너리 데이터로 판다스 시리즈 만들기
student1 = pd.Series({'국어':np.nan,'영어':80,'수학':90})
student2 = pd.Series({'수학':80,'국어':90})
# 두 시리즈객체는 원소의 개수도 다르고 인덱스도 완전히 같지는 않다.
print(student1)
국어 NaN
영어 80.0
수학 90.0
dtype: float64
print(student2)
수학 80
국어 90
dtype: int64
# 두 학생의 과목별 점수로 사칙연산 수행(시리즈 vs 시리즈)
addition = student1 + student2 # 덧셈
substraction = student1 - student2 # 뺄셈
multiplication = student1 * student2 # 곱셈
division = student1 / student2 # 나눗셈
print(type(division))
<class 'pandas.core.series.Series'>
# 사칙연산의 결과를 데이터프레임으로 합치기(시리즈 -> 데이터프레임)
result = pd.DataFrame([addition,substraction,multiplication,division],
index=['덧셈','뺄셈','곱셈','나눗셈'])
print(result)
국어 수학 영어
덧셈 NaN 170.000 NaN
뺄셈 NaN 10.000 NaN
곱셈 NaN 7200.000 NaN
나눗셈 NaN 1.125 NaN
Python
복사
~ 연산 메소드
객체 사이에 공통 인덱스가 없거나 NaN이 포함된 경우 연산 결과는 NaN이 반환된다. NaN 대신 다른 값으로 채우려면 fill_value 옵션을 설정한다.
# 연산 메소드를 사용해보자.
student1 = pd.Series({'국어':np.nan,'영어':80,'수학':90})
student2 = pd.Series({'수학':80,'국어':90})
print(student1)
국어 NaN
영어 80
수학 90
dtype: int64
print(student2)
수학 80
국어 90
# 두 학생의 과목별 점수로 사칙연산 수행(fill_value 사용)
sr_add = student1.add(student2, fill_value=0) # 기준은 student1
sr_sub = student1.sub(student2, fill_value=0)
sr_mul = student1.mul(student2, fill_value=0)
sr_div = student1.div(student2, fill_value=0) # student1 / student2
# 사칙연산 결과를 데이터프레임으로 합치기(시리즈->데이터프레임)
result = pd.DataFrame([sr_add,sr_sub,sr_mul,sr_div],
index=['덧셈','뺄셈','곱셈','나눗셈'])
print(result)
국어 수학 영어
덧셈 90.0 170.000 80.0
뺄셈 -90.0 10.000 80.0
곱셈 0.0 7200.000 0.0
나눗셈 0.0 1.125 inf
Python
복사
~ 데이터프레임 vs 숫자
시리즈와 마찬가지로 데이터프레임에 어떤 숫자를 연산하면 모든 원소에 적용한다. 결과는 새로운 데이터프레임 객체로 반환한다.
seaborn 라이브러리에 있는 titanic 데이터셋을 사용하겠다. load_dataset() 함수로 불러온다.
import seaborn as sns
# titanic데이터셋에서 age, fare, 2개 열을 선택하여 데이터프레임 만들기
titanic = sns.load_dataset('titanic')
df = titanic.loc[:,['age','fare']]
print(df.head())
age fare
0 22.0 7.2500
1 38.0 71.2833
2 26.0 7.9250
3 35.0 53.1000
4 35.0 8.0500
print(type(df))
<class 'pandas.core.frame.DataFrame'>
# 데이터프레임에 숫자 10더하기
addition = df + 10
print(addition.head()) # 첫 5행만 표시
age fare
0 32.0 17.2500
1 48.0 81.2833
2 36.0 17.9250
3 45.0 63.1000
4 45.0 18.0500
print(type(addition))
<class 'pandas.core.frame.DataFrame'>
Python
복사
~ 데이터프레임 vs 데이터프레임
각 데이터프레임의 같은 행, 같은 열 위치에 있는 원소끼리 계산한다.
•
데이터프레임 연산자 활용 : Dataframe1 + 연산자 + Dataframe2
print(df)
age fare
0 22.0 7.2500
1 38.0 71.2833
2 26.0 7.9250
3 35.0 53.1000
4 35.0 8.0500
.. ... ...
886 27.0 13.0000
887 19.0 30.0000
888 NaN 23.4500
889 26.0 30.0000
890 32.0 7.7500
[891 rows x 2 columns]
# df에 숫자 10 더하기
addition = df + 10
print(addition.tail())
age fare
886 37.0 23.00
887 29.0 40.00
888 NaN 33.45
889 36.0 40.00
890 42.0 17.75
# df끼리 연산하기(addition - df)
substraction = addition - df
print(substraction.tail())
age fare
886 10.0 10.0
887 10.0 10.0
888 NaN 10.0
889 10.0 10.0
890 10.0 10.0
Python
복사
5. datetime 모듈
클래스 : date, time, datetime, timedelta
•
datetime.date : 그레고리안 달력의 년, 월, 일
•
datetime.time : 시간을 시, 분, 초, 마이크로초 시간대로 나타냄
•
datetime.datetime : date클래스와 time클래스의 조합. 년, 월, 일, 시, 분, 초, 마이크로초 시간대 정보를 나타냄
•
datetime.timedelta : 두 날짜 혹은 시간 사이의 기간을 표현
>> datetime.date 클래스 <<
생성자 : datetim
•
year : 1 ~ 9999
•
month : 1 ~ 12
•
day : 1 ~ 해당월의 마지막 날짜
datetime.date 클래스의 속성 속성 | 내용 |
year | 년 (읽기 전용) |
month | 월 (읽기 전용) |
day | 일 (읽기 전용) |
max | date객체의 최댓값 (9999,12,31) |
min | date객체의 최소값 (1,1,1) |
datetime.date 객체를 반환하는 클래스메서드 •
fromtimestamp(timestamp) : 타임스탬프값을 인자로 받아서 date객체를 반환
import datetime,time
datetime.date.fromtimestamp(time.time())
Python
복사
•
fromordinal(ordinal) : 1년 1월 1일 이후로 누적된 날짜로부터 date객체를 반환
import datetime
datetime.date.fromordinal(100)
Python
복사
•
today() : 현재 시스템의 오늘 날짜 date객체를 반환
import datetime
datetime.date.today()
Python
복사
datetime.date 객체를 이용하여 다른 값/형식으로 반환하는 메서드•
replace(year, month, day) : 입력된 인자로 변경된 date객체를 반환. 단, 원본객체는 변경되지 않음. 변경하려는 속성만 명시적으로 전달할 수 있음
import datetime
a = datetime.date.today()
b = a.replace(day=1) # a객체에서 day 만 변경
a
b
Python
복사
•
timetuple() : date객체의 값을 struct_time 시퀀스객체로 반환
import datetime
a = datetime.date.today()
a.timetuple()
Python
복사
•
toordinal() : 1년 1월 1일 이후로 date객체까지 누적된 날짜를 반환
import datetime
a = datetime.date.today()
a.toordinal()
Python
복사
•
weekday() : 요일을 정수로 변환하여 반환(월=0, 화=1, 수=2,….,일=6)
import datetime
a = datetime.date.today()
a.weekday()
Python
복사
•
isoformat() : date객체의 정보를 ‘YYYY-MM-DD’ 형태의 문자열로 반환
import datetime
D = datetime.date.today()
D.isoformat()
Python
복사
•
ctime() : date객체의 정보를 ‘Sun Mar 15 00:00:00 2009’ 형태의 문자열로 반환. 시/분/초에 대한 정보는 ‘0’으로 초기화 됨
import datetime
D = datetime.date.today()
D.ctime()
Python
복사
•
strftime(format) : 지정된 포맷에 맞춰 datetime.date객체의 정보를 문자열로 반환
◦
%b : 축약된 월이름(’Mar’)
◦
%B : 축약되지 않은 월이름(’March’)
◦
%I : 12시를 기준 시(01~12)
◦
%p : 오전(AM) / 오후(PM) 표시
◦
%a : 축약된 요일 이름(’Fri’)
◦
%A : 축약되지 않은 요일 이름(’Friday’)
◦
%w : 요일을 숫자로 표시( 일:0, 월:1, …토:6)
◦
%j : 1월 1일부터 누적된 날짜(001 ~ 366)
import datetime
D = datetime.date(2022,7,09)
D.strftime('%Y %m %d')
D.strftime('%y %m %d %H:%M:%S') # 시분초에 대한 정보가 없으면 0으로 반환
Python
복사
>> datetime.time 클래스 <<
time클래스는 시, 분, 초와 같은 시간을 표현한다. 숫자로 시, 분, 초, 마이크로초, 시간대정보를 입력받아서 time객체를 생성하고 각 인자는 생략하거나 명시적으로 지정할 수 있다.
생성자 : datetime.time([hour[, minute[, second[, microsecond[, tzinfo]]]]])
•
hour : 0 ~ 23
•
minute : 0 ~ 59
•
second : 0 ~59
•
microsecond : 0 ~ 999999
# time 객체 생성
import datetime
datetime.time(23) # 시간만 입력
datetime.time(23,15,45,2341) # 시, 분, 초 , 마이크로초 입력
datetime.time(hour=23, second=5) # 인자지정하여 입력
datetime.time(25) # 인자허용값을 벗어나면 오류 발생
Python
복사
datetime.time 클래스 속성 속성 | 내용 |
hour | 시 |
minute | 분 |
second | 초 |
microsecond | 마이크로초 |
max | time객체가 표현할 수 있는 최댓값(0,0,0,0) |
min | time객체가 표현할 수 있는 최솟값(23,59,59,999999) |
import datetime
T = datetime.time(23,30,15,2904)
T.hour # 시
T.minute # 분
T.second # 초
T.microsecond # 마이크로초
T.max # time객체의 최댓값
T.min # time객체의 최솟값
Python
복사
datetime.time 클래스가 지원하는 메서드•
replace([hour[, minute[, second[, microsecond[, tzinfo]]]]]) : 입력된 인자로 변경된 time객체를 반환. 원본객체는 변하지 않음. 변경하려는 속성만 명시적으로 전달할 수 있음
import datetime
T = datetime.time(23,30,15,3759)
T1 = T.replace(microsecond=0)
T, T1
Python
복사
•
isoformat() : time객체의 값을 ‘HH:MM:SS.mmmmmm’ 형식이나 ‘HH:MM:SS’ 형식의 문자열로 반환
import datetime
T = datetime.time(23,30,15,3759)
T.isoformat()
Python
복사
•
strftime() : 지정된 포맷에 맞춰 datetime.time객체의 정보를 문자열로 반환
import datetime
T = datetime.time(23,30,15,3759)
T.strftime('%Y %m %d %H:%M:%S')
Python
복사
>> datetime.datetime 클래스 <<
datetime클래스는 date클래스와 time클래스의 조합으로 이루어져 있다.
생성자 : datetime.datetime(year, month, day[, hour[, minute[, second[, microsecond[, tzinfo]]]]])
•
year : 1 ~ 9999
•
month : 1 ~ 12
•
day : 1 ~ 해당월의 마지막 날짜
•
hour : 0 ~23
•
minute : 0 ~ 59
•
second : 0 ~우
•
microsecond : 0 ~ 999999
import datetime
Python
복사
datetime.datetime 클래스 속성 위와 동일하다.
datetime.datetime 객체를 생성하는 클래스메서드•
today() : 현재 LST 기준의 datetime객체를 생성
import datetime
datetime.datetime.today()
Python
복사
•
now([tz]) : 현재 LST기준의 datetime객체를 생성. 시간대 정보가 입력되지 않으면 플랫폼의 시간대를 그대로 사용
import datetime
datetime.datetime.now()
Python
복사
•
utcnow() : UTC기준의 datetime객체를 생성
import datetime
datetime.datetime.utcnow()
Python
복사
•
fromtimestamp(timestamp[,tz]) : 타임스탬프를 지방 기준의 datetime객체를 생성
import datetime,time
datetime.datetime.utcfromtimestamp(time.time())
Python
복사
•
fromordinal(ordinal) : 1년 1월 1일 이후로 누적된 날짜로부터 datetime객체를 생성. 시간관련 값은 0으로 할당됨.
import datetime
datetime.datetime.fromordinal(1000)
Python
복사
•
combine(date, time) : date객체와 time객체를 입력받아 datetime객체를 생성
import datetime
D = datetime.date(2022,7,10)
T = datetime.time(23,30,15)
DT = datetime.datetime.combine(D,T)
Python
복사
•
strptime(date_string, format)
—> time모듈의 strftime메서드와 형식지시자가 같음
import datetime,time
timestring = time.ctime(1234567890) # 숫자값을 알아보기 쉬운 날짜와 시간으로 변환해줌
datetime.datetime.strptime(timestring, '%a %b %d %H:%M:%S %Y')
Python
복사
datetime.datetime 객체를 이용해서 다른 값/형식으로 반환하는 메서드•
date() : 원본객체의 년, 월, 일 정보를 가지고 있는 date객체를 반환
import datetime
DT = datetime.datetime(2022,7,10,16,08,30)
D = DT.date()
D
Python
복사
•
time() : 원본객체의 시, 분, 초, 마이크로초를 가지고 있는 time객체를 반환
import datetime
DT = datetime.datetime(2022,7,10,16,08,30,15)
T = DT.time()
T
Python
복사
•
replace() : 입력된 값으로 변경된 datetime객체를 반환. 원본객체는 변하지 않음
import datetime
DT = datetime.datetime(2022,7,10,16,08,30,15)
DT_1 = DT.replace(year=1987)
DT # 원본객체
DT_1 # 변경된 객체
Python
복사
•
timetuple() : datetime객체의 값을 time.struct_time형식의 시퀀스객체로 변환하여 반환
import datetime
DT = datetime.datetime(2022,7,10,16,08,30,15)
DT.timetuple()
Python
복사
•
weekday() : 요일을 정수로 변환하여 반환(월: 0,…일:6)
import datetime
DT = datetime.datetime.today()
DT.weekday()
Python
복사
•
isoweekday() : ISO형식에 맞도록 요일을 정수 변환하여 반환(월:1, 토:6, 일)
import datetime
DT = datetime.datetime.today()
DT.isoweekday()
Python
복사
•
isocalendar() : ISO형식에 맞는 날짜표현(ISO year, ISO week number, ISO weekday)를 튜플로 반환
import datetime
DT = datetime.datetime.today()
DT.isocalendar()
Python
복사
•
isoformat() : datetime객체를 ‘YYYY-MM-DDTHH:MM:SS.mmmmmm’ 형식으로 변환하여 문자열로 반환. 마이크로초가 0인 경우 ‘.mmmmmm’ 부분은 생략
import datetime
DT = datetime.datetime.today()
DT.isoformat()
DT.replace(microsecond=0).isoformat() # 마이크로초가 0인경우
Python
복사
•
strftime(format) : 지정된 포맷형식에 맞추어 datetime.datetime객체를 문자열로 반환
—> time 모듈의 strftime 메서드와 형식지시자가 같음
>> datetime.timedelta 클래스 <<
두 날짜 혹은 시간 사이의 기간을 표현한다. 인자는 양수인 경우 현시점으로부터 이후를 나타내고, 음수인 경우 현시점 이전을 나타낸다.
생성자 : datetime.timedelta([days[, seconds[, microseconds[, milliseconds[, minutes[, hours[, weeks]]]]]]]])
import datetime
datetime.timedelta(days=-3) # 3일 이전
datetime.timedelta(hours=7) # 7시간 이후
datetime.timedelta(weeks=2, days=3, hours=-3, minutes=30)
datetime.timedelta(minutes=3,milliseconds=-20, microseconds=400)
Python
복사
—> 입력된 값을 가지고 timedelta객체에서 정규화과정을 거쳐 유일한 표현방식으로 변경하기 때문에 동일한 기간을 표현하는 방식이 다양하게 표현된다.(1weeks = 7days)
예를들어, 정규화 결과 timedelta객체 저장되는 값은 아래와 같다.
•
days : -999999999 ~ 999999999
•
seconds : 0 ~ 86399(24시간을 초로 환산하면 86400)
•
microseconds : 0 ~ 999999
datetime.timedelta(microseconds=-1) # 현재 이전으로 가장 작은값
datetime.timedelta(microseconds=1) # 현재 이후로 가장 작은 값
Python
복사
시간, 날짜의 연산 생성된 timedelta클래스 객체를 이용해서 아래의 연산을 수행할 수 있다. 연산결과는 모두 timedelta객체가 반환된다.
•
timedelta_3 = timedelta_1 + timedelta_2
•
timedelta_3 = timedelta_1 - timedelta_2
•
timedelta_3 = timedelta_1 * int = int * timedleta_1
•
timedelta_2 = timedelta_1 // int
•
abs(timedelta)
from datetime import timedelta
td_1 = timedelta(hours=7) # 현재시간으로부터 7시간 이후
td_2 = timedelta(days=-3) # 현재로부터 3일 이전
td_1 + td_2 # 두 timedelta의 합
td_1 - td_2 # 두 timedelta의 차
td_1 * 4 # timedelta와 정수의 곱
td_1 //3 # 25200초 //3
abs(td_2) # 기간의 절댓값 --> datetime.timedelta(3)
Python
복사
비교연산도 가능 from datetime import timedelta
td_1 = timedelta(hours=7) # 7시간 이후
td_2 = timedelta(days=-3) # 3일 이전
td_1 > td_2
td_1 < td_2
td_1 = timedelta(hours=24) # 24시간 이후, (=86400초 이후)
td_2 = timedelta(seconds=86400) # 위와 동일
td_1 == td_2
Python
복사
timedelta객체 이용하여 date, datetime 객체를 변경할 수 있음 •
date_2 = date_1 + timedelta
•
date_2 = date_1 - timedelta
•
timedelta = date_2 - date_1
•
datetime_2 = datetime_1 + timedelta
•
datetime_2 = datetime_1 - timedelta
•
timedelta = datetime_1 - datetime_2
# date 객체와 관련된 연산
from datetime import timedelta, date
d = date.today()
td = timedelta(days=3)
d + td # 오늘로부터 3일 후
Python
복사
6. 데이터 만들기
•
딕셔너리로 데이터프레임 만들기 (변수 이름과 값 할당)
pd.DataFrame({'col_one':[100,200], 'col two':[300,400]})
Python
복사
•
Numpy 의 random.rand() : 행과 열 사이즈 조정으로 임의의 사이즈를 가지는 데이터프레임 생성
import numpy as np
pd.DataFrame(np.random.rand(4,8)) # 4행 8열의 데이터프레임 생성
Python
복사
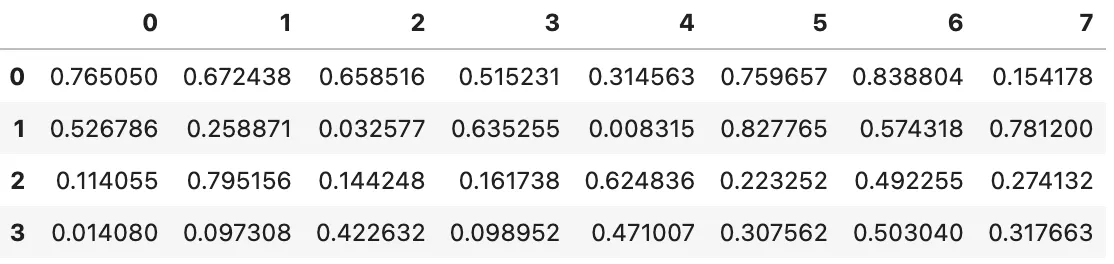
# 변수명을 숫자가 아닌 텍스트의 리스트로 설정
pd.DataFrame(np.random.rand(4,8), columns=list('abcdefgh'))
Python
복사