
<목차>
1. 사전 작업
버전 확인
# 현재 버전 확인
import sys
sys.version
Python
복사
변수 완전 제거
del 변수이름
Python
복사
데이터 형식 확인
type(변수이름)
Python
복사
변수 생성 규칙
•
문법 키워드 사용 불가
•
‘_’ 를 제외한 특수 문자 사용 불가
•
공백 사용 불가
•
숫자로 시작 불가
2. Print 함수
2- 1. sep 과 end
•
sep
값을 구분하는 구분자 : default = ‘ ‘
print('Hello', 'World.')
print('Hello', 'World.', sep='')
Python
복사
Hello world.
Helloworld.
Plain Text
복사
3. 연산자
기타연산자 - 멤버 연산자 (in, not in)
기타연산자 - 식별 연산자(is, is not)
: 두 객체가 동일한 객체인지 확인하는 연산자

값의 같음을 비교하는 ==, != 연산자와는 조금 다른 의미를 지님
x = [1, 2, 3, 4, 5]
y = [1, 2, 3, 4, 5]
z = x # z는 x와 동일한 객체가 된다.
# 값이 같은지?
print(x == y)
print(x == z)
# 객체가 같은지?
print(x is y)
print(x is z)
x[0] = 100
print(x, z)
Python
복사
True
True
False
True
[100, 2, 3, 4, 5] [100, 2, 3, 4, 5]
4. 자료형 사이의 변환
•
float() : 실수로 변환
•
int() : 정수로 변환
•
str() : 문자로 변환
•
bool() : 부울형으로 변환
5. 문자열 자료형
•
문자열 나열
◦
문자열을 콤마 없이 나란히 나열했을 때 합쳐진 결과를 얻을 수 있다.
s = 'Hello' 'Python'
print(s)
Python
복사
HelloPython
•
여러 줄 문자열 표시
◦
\n
s1 = '여러 줄의 문자열을 표시할 때는 \n을 사용하세요'
print(s1)
Python
복사
여러 줄의 문자열을 표시할 때는
을 사용하세요
◦
“”” “””
s2 = """또 다른 방법은
큰 따옴표나 작은 따옴표를 세 개 사용하는 것입니다."""
print(s2)
Python
복사
또 다른 방법은
큰 따옴표나 작은 따옴표를 세 개 사용하는 것입니다.
Format 메서드 사용
•
문자열.format()
대부분 print() 함수 안에서 사용한다.
# format
'이름 :{}, 과목 :{}, 점수 :{}'.format('홍길동','국어',90)
Python
복사
'이름:홍길동, 과목:국어, 점수:90'
name = '홍길동'
year = 2019
perf = 2345.6789
# 출력
print('이름:{}, 연도:{}, 실적:{}'.format(name, year, perf))
Python
복사
{} 안에 표시 위치를 지정할 수 있다. 순서대로 사용할 경우에는 위처럼 생략하면 된다.
실수를 입력한다면 자리 수, 출력 모양 등을 제어할 수 있다.
# 변수 선언
name = '홍길동'
year = 2019
perf = 2345.6789
print('이름:{}, 연도:{}, 실적:{}'.format(name, year, perf)) # 순서대로 입력
print('연도:{1}, 이름:{0}, 실적:{2}'.format(name, year, perf)) # 표시 위치 지정
print('이름:{}, 연도:{}, 실적:{:.2f}'.format(name, year, perf)) # perf 는 소수점 아래 2자리까지 표시
print('이름:{}, 연도:{}, 실적:{:,.2f}'.format(name,year,perf)) # 소수점 아래 2자리 표시, 천의 자리에 , 표시
Python
복사
정렬, 공간을 설정할 수 있다.
# 기본 정렬
print('[{:10}] [{:6}]'.format('홍길동', 1200))
# 오른쪽, 왼쪽 정렬
print('[{:>10}] [{:<6}]'.format('홍길동',1200))
# 가운데 정렬
print('[{:^10}] [{:^6}]'.format('홍길동',1200))
# 공백을 다른 문자로 채우기
print('[{:-^10}] [{:_^6}]'.format('홍길동',1200))
Python
복사
[홍길동 ] [ 1200]
[ 홍길동] [1200 ]
[ 홍길동 ] [ 1200 ]
[---홍길동----] [_1200_]
•
f-string
최근에는 이 방식을 더 많이 사용한다.
name = '홍길동'
age = 25
score = 2345.6789
print(f'이름 : {name}')
print(f'나이 : {age}')
print(f'점수 : {score}')
print(f'{age}살의 {name}의 점수는 {score}입니다.')
Python
복사
출력되는 형태도 앞의 format처럼 사용할 수 있다.
print(f'{age}살의 {name}의 점수는 {score:,.2f}입니다.')
Python
복사
25살의 홍길동의 점수는 2,345.68입니다.
인덱싱, 슬라이싱
•
인덱싱으로 문자열 변경 불가하다.
문자열 주요 메서드
메서드는 그 결과가 원본에 반영되지 않음을 주의하자!
•
upper() : 모든 문자를 대문자로 변경
s = 'I Have a Dream'
print(s.upper())
print(s)
Python
복사
I HAVE A DREAM
I Have a Dream
원본을 변형시킬려면 반환되는 값을 변수에 다시 대입해야 한다.
이때 기존의 변수와 이후의 변수는 각각 id 가 다름을 주의하자!
s = s.upper()
Python
복사
•
lower() : 모든 문자를 소문자로 변경
s = 'I Have a Dream'
print(s.lower())
Python
복사
i have a dream
•
capitalize() : 문장의 제일 첫번째 문자만 대문자로 변환 + 나머지는 모두 소문자로 변환
s = 'I Have a Dream'
print(s.capitalize())
Python
복사
I have dream
•
title() : 단어의 첫글자만 대문자로 변환 + 나머지는 모두 소문자로 변환
s = 'I Have a Dream'
print(s.title())
Python
복사
I Have A Dream
•
rjust(x) : x만큼의 자릿수 확보 후, 오른쪽 정렬
•
ljust(x) : x만큼의 자릿수 확보 후, 왼쪽 정렬
•
center(x) : x만큼의 자릿수 확보 후, 가운데 정렬
s = 'Dream'
print('[' + s.rjust(7) + ']')
print('[' + s.ljust(7) + ']')
print('[' + s.center(7) + ']')
Python
복사
[ Dream]
[Dream ]
[ Dream ]
Plain Text
복사
•
replace(x, y) : 일부 문자열 x를 문자열 y로 변경
s = 'nowhere'
s.replace('now','now ')
Python
복사
now here
•
strip(x) : 문자열에서 모든 공백 또는 특수 문자 제거
print(' world '.strip())
print('#world#$$#'.strip())
print('#world#$$#'.strip('$#'))
Python
복사
world
#world#$$#
world
Plain Text
복사
•
split(x) : x문자를 구분자로 하여 문자열을 분리 → 리스트로 반환
s = 'I have a Dream!'
s.split() # 공백을 기준으로 문자열 분리 후 리스트로 반환
Python
복사
[’I’, ‘have’, ‘a’, ‘Dream!’]
•
x.join() : x를 구분자로 하여 요소들을 연결한 문자열을 반환
s = 'PYTHON'
s1 = '/'.join(s)
print(s1)
Python
복사
P/Y/T/H/O/N
# 보통 리스트에서 구분자로 연결해 문자열로 바꿀 때 사용된다.
a = ['홍길동', '한사랑', '강우동', '박여인']
s = '/'.join(a)
print(s)
Python
복사
‘홍길동/한사랑/강우동/박여인’
6. 리스트
리스트 원소에 들어갈 수 있는 데이터 타입은 다음과 같다.
혼합해서 담을 수 있는 것이 특징이다. •
숫자, 문자, 논리형
•
리스트
리스트의 대표적인 함수
•
sum() : 원소들의 합을 계산
•
max() : 원소들의 최댓값 계산
•
min() : 원소들의 최솟값 계산
빈 리스트 생성하기
score1 = [] # 방법1
score2 = list() # 방법2
Python
복사
range와 list
range 함수를 이용해서 패턴을 가진 숫자 리스트를 만들 수 있다.
nums = list(range(10)) # [0, 1,....,9]
nums = list(range(-5,6)) # [-5, -4,....,-5]
nums = list(range(0,10,2)) # [0,2,4,...,8]
nums = list(range(9,-1,-1)) # [9,8,...,1,0]
Python
복사
문자열로 리스트 만들기
# 문자열 하나를 요소로 갖는 리스트
list_str = ['PYTHON']
# 개별 문자를 요소로 갖는 리스트
list_str = list('PYTHON')
Python
복사
[’PYTHON”]
[’P’, ‘Y’, ‘T’, ‘H’, ‘O’, ‘N’]
리스트 원소 조회하기
for 문을 이용한 두가지의 방식이 있다.
•
len() 사용하기
foods = ['bread','kimbap','kimchi','cereal']
for i in range(len(foods)):
print(foods[i])
Python
복사
•
그냥 사용하기 → iterable 한 자료구조라서 쓸 수 있는 방법이다.
foods = ['bread','kimbap','kimchi','cereal']
for food in foods:
print(food)
Python
복사
리스트 내부에 또 다른 리스트의 아이템을 조회할 수 있는 방법 studentCnts = [[1,19],[2,20],[3,22],[4,18],[5,21]]
for classNo, cnt in studnetCnts: # -> 리스트 원소의 리스트 아이템 0,1번째 인덱스에 바로 접근 가능
print('{}학급 학생수: {}'.format(classNo, cnt))
#1학급 학생수: 19
#2학급 학생수: 20
#3학급 학생수: 22
#4학급 학생수: 18
#5학급 학생수: 21
Python
복사
ex 1.
# 과락 과목 확인하기
minScore = 60
scores = [
['국어', 58],
['영어', 77],
['수학', 89],
['과학', 99],
['국사', 50]]
for item in scores:
if item[1] < minScore:
print('과락 과목: {}, 점수: {}'.format(item[0], item[1]))
Python
복사
# 또는
for subj, score in scores:
if score < minScore:
print('과락 과목: {}, 점수: {}'.format(subj, score))
Python
복사
# 또는 continue 이용
for subj, score in scores:
if score >= minScore: continue
print('과락 과목: {}, 점수: {}'.format(subj, score))
Python
복사
ex 2.
# 국어, 영어, 수학, 과학, 국사 점수를 입력하면 과락 과목과 점수를 출력하는 프로그램
minScore = 60
kor = int(input('국어 점수 입력: '))
eng = int(input('영어 점수 입력: '))
mat = int(input('수학 점수 입력: '))
sci = int(input('과학 점수 입력: '))
his = int(input('국사 점수 입력: '))
scores = [
['국어',kor],
['영어',eng],
['수학',mat],
['과학',sci],
['국사',his]
]
for subj, score in scores:
if score < minScore:
print('과락 과목 : {}, 점수 : {}'.format(subj, score))
Python
복사
ex 3. 다시 !
# 학급 학생 수가 가장 작은 학급과 가장 많은 학급을 출력하자
studentCnts = [
[1,18],
[2,19],
[3,23],
[4,21],
[5,20],
[6,22],
[7,17]
]
minCnt = 0; minClassNo = 0
maxCnt = 0; maxClassNo = 0
for classno, Cnt in studentCnts:
if minCnt == 0 or Cnt < minCnt: # 초기에는 minCnt = 0이라는 점을 고려해서
minCnt = Cnt
minClassNo = classno
if maxCnt == 0 or Cnt > maxCnt:
maxCnt = Cnt
maxClassNo = classno
print('학생 수가 가장 적은 학급(학생수): {}학급({}명)'.format(minClassNo,minCnt))
print('학생 수가 가장 많은 학급(학생수): {}학급({}명)'.format(maxClassNo,maxCnt))
Python
복사
•
while() 문 사용해서 조회하기
cars = ['그랜저','소나타','말리부','카니발','쏘렌토']
n = 0
while n < len(cars):
print(cars[n])
n += 1
Python
복사
n = 0
flag = True
while flag:
print(cars[n])
n += 1
if n == len(cars):
flag = False
Python
복사
n = 0
while True:
print(cars[n])
n += 1
if n == len(cars):
break
Python
복사
ex 1.
studentCnts = [
[1,19],
[2,20],
[3,22],
[4,18],
[5,21]
]
sum = 0
avg = 0
n = 0
while n < len(studentCnts):
classNo = studentCnts[n][0]
cnt = studentCnts[n][1]
print('{}학급 학생수: {}'.format(classNo, cnt))
sum += cnt
n += 1
print('전체 학생 수 : {}명'.format(sum))
print('평균 학생 수 : {}명'.format(sum / len(studnetCnts)))
Python
복사
ex 2.
# while 과 if문을 활용해 과락 과목과 점수를 출력하자
minScore = 60
scores = [
['국어', 58],
['영어', 77],
['수학', 89],
['과학', 99],
['국사', 50]]
n = 0
while n < len(scores):
if scores[n][1] < minScore:
print('과락 과목 : {}, 점수 : {}'.format(scores[n][0], scores[n][1]))
n += 1
Python
복사
# 또는
n = 0
while n < len(scores):
if scores[n][1] >= minScore:
n += 1
continue
print('과락 과목 : {}, 점수 : {}'.format(scores[n][0], scores[n][1]))
n += 1
Python
복사
ex 3.
# 학급 학생 수가 가장 작은 학급과 가장 많은 학급을 출력하자
studentCnts = [
[1,17],
[2,19],
[3,23],
[4,21],
[5,20],
[6,22],
[7,17]
]
minCnt = 0; minClassNo = 0
maxCnt = 0; maxClassNo = 0
n = 0
while n < len(studentCnts):
if minCnt == 0 or studentCnts[n][1] < minCnt:
minClassNo = studnetCnts[n][0]
minCnt = studentCnts[n][1]
if studentCnts[n][1] > maxCnt:
maxClassNo = studnetCnts[n][0]
maxCnt = studentCnts[n][1]
n += 1
print('학생 수가 가장 적은 학급(학생수): {}학급({}명)'.format(minClassNo,minCnt))
print('학생 수가 가장 많은 학급(학생수): {}학급({}명)'.format(maxClassNo,maxCnt))
Python
복사
•
enumerate 함수
인덱스와 아이템을 동시에 for 문으로 돌릴 수 있다.
문자열에도 사용할 수 있다ex 1.
# 가장 좋아하는 스포츠가 몇 번째에 있는지 출력하자.
sports = ['농구','수구','축구','마라톤','테니스']
favoriteSport = input('가장 좋아하는 스포츠 입력: ')
bestSportIdx = 0
for idx, item in enumerate(sports):
if item == favoriteSport:
bestSportIdx = idx + 1
print('{}은 {}번째에 있습니다.'.format(favoriteSport,bestSportIdx))
Python
복사
ex 2.
# 사용자가 입력한 문자열에서 공백의 개수를 출력하자.
message = input('메세지 입력:')
cnt = 0 # 개수를 셀 변수 초기화
for i in message:
if i == ' ':
cnt += 1
print('사용자가 입력한 메세지: {}, 공백 개수 : {}'.format(message, cnt))
Python
복사
리스트 요소 변경
•
범위를 벗어나는 요소 값을 변경하면 요소가 추가된다.
•
범위가 꼭 연결되지 않아도 알아서 변경된다.
nums = list(range(10)) #[0,1,2, ...,9]
nums[6:] = [70,80,90,100]
print(nums)
nums[600:] = [110,120]
print(nums)
Python
복사
[0,1, 2, 3, 4, 5, 70, 80, 90, 100]
[0,1, 2, 3, 4, 5, 70, 80, 90, 100, 110, 120]
리스트 아이템 추가하기 - append() / insert()
•
append(값) : 마지막 인덱스에 요소 하나 추가
•
insert(인덱스, 값) : 특정 인덱스(위치)에 요소 추가
ex 1.
# 오름차순으로 정렬되어 있는 숫자 리스트에 어떤 숫자를 추가하려고 한다.
# 이때, 정렬 순서에 맞게 추가해보자.
numbers = [1,3,6,11,45,54,62,74,85]
inputNum = int(input('숫자 입력: '))
inputIdx = 0
print(f'넣기 전의 numbers : {numbers}')
for idx, num in enumerate(numbers):
# 들어있는 num보다 작은지만 확인해주면 된다.
if inputNum < num:
inputIdx = idx
break
numbers.insert(inputIdx,inputNum)
print(numbers)
Python
복사
강사님 풀이numbers = [1,3,6,11,45,54,62,74,85]
inputNum = int(input('숫자 입력: '))
inputIdx = 0
for idx, num in enumerate(numbers):
print(idx, num)
if inputIdx == 0 and inputNum < num:
inputIdx = idx
numbers.insert(inputIdx,inputNum)
print(numbers)
Python
복사
inputIdx == 0 을 조건식에 넣는 이유 → 위의 나의 식에서 break 과 같은 기능을 수행하는 것이다.
•
내 코드의 break 경우, num 보다 처음으로 작게 되는 순간 해당 인덱스를 부여해주고 빠져나와야 그 뒤의 큰 num 들까지 확인하지 않는다.
•
강사님의 inputIdx == 0의 경우도 and 절로 조건을 연결해 맨 처음으로 작게 되는 경우에만수행할 수 있도록 한정하고 있다. 그래야 다음 뒤의 큰 num들에서 inputIdx == 0의 조건을 만족하지 않기 때문에 수행하지 않게 되는 것이다.
리스트 확장하기
•
리스트끼리 더해서 확장할 수 있다.
nums = list(range(5))
nums += [5,6,7,8,9]
print(nums)
Python
복사
[0,1,2,3,4,5,6,7,8,9]
•
extend() : append() 와 달리 여러 원소를 더해 확장할 수 있다.
nums = list(range(5))
nums.extend([5,6,7,8,9])
print(nums)
nums.extend([10]) # nums.extend(10) 은 안됨!
print(nums)
Python
복사
[0,1,2,3,4,5,6,7,8,9]
[0,1,2,3,4,5,6,7,8,9,10]
리스트 아이템 삭제하기 - del / clear() / pop(인덱스) / remove(값)
•
del
중복된 원소 중에서는 하나만 삭제 가능
nums = list(range(10,100,10)) # [10,20,30,...,90]
del nums[7] # 8번째 값 삭제
Python
복사
[10, 20, 30, 40, 50, 60, 70, 90]
중복된 원소 중에서는 하나만 삭제 가능
•
clear() : 전체 원소를 삭제 → 초기화
nums.clear() # 모든 요소 삭제
nums
Python
복사
[]
•
pop() : 마지막 요소 제거
•
pop(x): x 인덱스 위치의 원소 제거 및 제거한 원소 반환
member = ['홍길동', '일지매', '박여인', '한사랑', '박여인', '강우동']
# 3번째 원소 삭제 및 삭제한 원소 저장
del_member = member.pop(2)
print(member)
print(del_member)
Python
복사
['홍길동', '일지매', '한사랑', '박여인', '강우동']
박여인
•
remove(x) : x 요소 삭제
member = ['홍길동', '일지매', '박여인', '한사랑', '박여인', '강우동']
member.remove('박여인')
print(member)
Python
복사
['홍길동', '일지매', '한사랑', '박여인', '강우동']
pop() 연산자는 제거한 값을 반환한다ex 1.
# 점수표에서 최고, 최저 점수를 제거한 점수만 남기자.
playerScore = [9.5,8.9,9.2,9.8,8.8,9.0]
min_score = min(playerScore)
min_idx = playerScore.index(min_score)
playerScore.pop(min_idx)
print(playerScore) # 최저 점수를 제거하고 난 뒤 출력
max_score = max(playerScore)
max_idx = playerScore.index(max_score)
playerScore.pop(max_idx)
print(playerScore) # 최고 점수를 제거하고 난 뒤 출력
Python
복사
remove() 연산자는 한 개의 값만 삭제한다. → 삭제하려는 값이 두개 이상일 경우 while 문을 이용해서 제거하면 된다.
# remove
students = ['홍길동','임선주','박찬호','강호동','박승철','김지은','강호동']
students.remove('강호동')
print(students)
while ('강호동' in students): # '강호동' 이 원소에 있을때까지만 반복
students.remove('강호동')
print(students)
Python
복사
리스트 복사
리스트 = 리스트 형태는 복사가 아니다.
범위를 지정한 복사가 완전한 복사의 의미를 갖는다.
nums = list(range(10))
nums_copy1 = nums # nums와 nums_copy1는 동일한 객체
nums_copy2 = nums[:] # nums_copy2는 nums의 모든 값과 동일한 전혀 다른 객체
Python
복사
•
copy() : 위의 프로세싱을 할 수 있는 로봇 메서드
nums_copy2 = nums[:]
nums2_copy2 = nums.copy()
Python
복사
리스트 관련 메서드
문자열 메서드와 다르게 리스트 관련 메서드는 원본에 바로 반영이 된다.
한편 그렇기 때문에 반환값이 없다.
reverse() : 리스트 원소들의 순서를 뒤바꾼다.
count() / index() 메서드
sort() : 리스트 안의 요소를 정렬한다.
7. 딕셔너리
집합과 마찬가지로 중괄호{} 를 사용해 선언한다.
하지만, key : value 형태를 가지기 때문에 집합과 다르다.
7-1. 딕셔너리 특징
•
순서의 의미가 없다.
•
인덱싱이 아닌, key를 이용해서 값(value)를 확인한다.
•
key는 중복될 수 없다.
◦
key가 같다면 마지막 key에 해당하는 value만 남기고 이전 key는 무시된다.
•
다양한 값을 value로 가질 수 있다.
•
key는 변경될 수 없기 때문에 리스트 값을 가질 수 없다.
member = {
['이름', '나이'] : ['홍길동', 20]
}
Python
복사
TypeError: unhashable type: 'list'
7-2. 딕셔너리로 자료형 변환
•
dict()
Key : Value 형태를 가질 수 있는 자료형을 딕셔너리로 변환한다.
대부분 리스트 → 딕셔너리로 변환할 때 사용된다.
### 리스트 -> 딕셔너리
members = [['홍길동', 100], ['일지매', 90], ['한여인', 90], ['강우동', 95]]
# 딕셔너리 변환
member_dic = dict(members)
member_dic
### 튜플 -> 딕셔너리
members = (('홍길동', 100), ('일지매', 90), ('한여인', 90), ('강우동', 95))
member_dic = dict(members)
Python
복사
{'홍길동': 100, '일지매': 90, '한여인': 90, '강우동': 95}
7-3. 딕셔너리 조회
Key를 사용해 Value값을 조회한다.
member = {'이름': '홍길동',
'취미': ['독서', '여행', '걷기']}
member['이름']
member['취미']
Python
복사
'홍길동'
['독서', '여행', '걷기']
•
in 연산자
특정 Key나 Value가 있는지 확인할 수 있다.
print('이름' in member) # True
print('홍길동' in member) # False
print('여행' in member['취미']) # True
Python
복사
# 개인 정보에 연락처와 주민등록번호가 있다면 삭제하는 코드
myInfo = {
'이름': '임선주',
'나이': 27,
'연락처': '010-5477-4582',
'주민등록번호': '970301-2945382',
'주소': '대한민국 경기도'
}
deleteItem = ['연락처','주민등록번호']
for item in deleteItem:
if item in myInfo:
del myInfo[item]
print(myInfo)
Python
복사
7-4. 딕셔너리 변경, 추가, 삭제
member = {
'이름': '홍길동',
'나이': 20
}
# 딕셔너리 요소 변경
member['나이'] = 30
# 딕셔너리 추가
member['취미'] = ['독서','여행']
# 딕셔너리 요소 삭제
## 1. del
del member['나이'] # {'이름': '홍길동', '취미': ['독서', '여행']}
## 2. pop
del_member = member.pop('취미')
print(del_member)
print(member)
Python
복사
['독서', '여행']
{'이름': '홍길동'}
# 하루에 몸무게와 신장이 -0.3kg, + 0.001m씩 변한다고 할 때, 30일 후의 몸무게와 신장의 값을 저장하고
# bmi 도 출력하는 프로그램을 만들자.
mybodyInfo = {
'이름':'gildong',
'몸무게': 83.0,
'신장':1.8
}
myBmi = mybodyInfo['몸무게'] / (mybodyInfo['신장']**2)
# 현재
print(f'mybodyInfo : {mybodyInfo}')
print(f'myBmi : {round(myBmi,2)}')
# 30일 후
mybodyInfo['몸무게'] = mybodyInfo['몸무게'] - 0.3*30
mybodyInfo['신장'] = mybodyInfo['신장'] + 0.001*30
myNewBmi = mybodyInfo['몸무게'] / (mybodyInfo['신장']**2)
print(f'mybodyInfo : {mybodyInfo}')
print(f'myBmi : {round(myNewBmi,2)}')
Python
복사
# while 문을 이용해보자.
mybodyInfo = {
'이름':'gildong',
'몸무게': 83.0,
'신장':1.8
}
myBmi = mybodyInfo['몸무게'] / (mybodyInfo['신장']**2)
# 현재
print(f'mybodyInfo : {mybodyInfo}')
print(f'myBmi : {round(myBmi,2)}')
n = 1
while n <= 30: # 30번 반복해야 되니까
mybodyInfo['몸무게'] = mybodyInfo['몸무게'] - 0.3
mybodyInfo['신장'] = mybodyInfo['신장'] + 0.001
n += 1
myNewBmi = mybodyInfo['몸무게'] / (mybodyInfo['신장']**2)
print(f'mybodyInfo : {mybodyInfo}')
print(f'myBmi : {round(myNewBmi,2)}')
Python
복사
•
popitem()
Key 지정 없이 마지막 요소 삭제
삭제된 요소의 key와 value를 튜플 형태로 반환
member = {'이름': '홍길동',
'나이': 20,
'지역':'서울',
'성별': 'M',
'등급': 'Gold'}
del_member = member.popitem()
print(del_member)
print(member)
Python
복사
('등급', 'Gold')
{'이름': '홍길동', '나이': 20, '지역': '서울', '성별': 'M'}\
•
딕셔너리 초기화
member = {}
# 또는 clear()
member.clear()
Python
복사
7-5. 딕셔너리 관련 메서드
•
keys()
딕셔너리의 key 정보를 확인한다.
member = {'이름': '홍길동',
'취미': ['독서', '여행', '걷기']}
member.keys()
# 딕셔너리 key만 뽑아 리스트로 만들기
member_keyws = list(member.keys())
Python
복사
dict_keys(['이름', '취미'])
[’이름’ , ‘취미’]
•
values()
딕셔너리의 Value 정보를 확인한다.
member.values()
# value만 뽑아 리스트로 만들기
member_values = list(member.values())
Python
복사
dict_values(['홍길동', ['독서', '여행', '걷기']])
['홍길동', ['독서', '여행', '걷기']]
•
items()
key와 value 정보를 확인한다.
member.items()
Python
복사
dict_items([('이름', '홍길동'), ('취미', ['독서', '여행', '걷기'])])
# for문을 이용한 조회
for key in meminfo.keys():
print(f'{key} : {meminfo[key]}')
Python
복사
# 학생의 점수가 60점 미만이면 '재시험' 으로 값을 변경하는 코드를 짜보자.
scores = {'kor':80, 'eng':55, 'mat': 60, 'sci':57, 'his': 90}
print(f'scores: {scores}')
minscore = 60
fStr = '재시험'
fDic = {}
for key in scores.keys(): # 또는 그냥 scores 해도 된다.
if scores[key] < minscore:
scores[key] = fStr
fDic[key] = fStr
print(f'scores : {scores}')
print(f'fDic : {fDic}')
# scores: {'kor': 80, 'eng': 55, 'mat': 60, 'sci': 57, 'his': 90}
# scores : {'kor': 80, 'eng': '재시험', 'mat': 60, 'sci': '재시험', 'his': 90}
# fDic : {'eng': '재시험', 'sci': '재시험'}
Python
복사
# 딕셔너리에 저장된 점수 중 최저 점수와 최고 점수를 삭제하는 프로그램
scores = {'score1':8.9, 'score2': 8.1, 'score3': 8.5, 'score4':9.8, 'score5': 8.8}
minScore = 10; minScoreKey = ''
maxScore = 0; maxScoreKey = ''
for key in scores.keys():
if scores[key] < minScore:
minScore = scores[key]
minScoreKey = key
if scores[key] > maxScore:
maxScore = scores[key]
maxScoreKey = key
del scores[minScoreKey]
del scores[maxScoreKey]
print('결과 : {}'.format(scores))
Python
복사
•
get()
Key를 지정해 원하는 Value값을 찾는다.
값이 없을 때 오류가 발생하지 않는다. 값이 없을 때 대신할 값을 지정할 수 있다.
member = {'이름': '홍길동', '취미': ['독서', '여행', '걷기']}
member.get('이름')
member.get('이메일') # 아무값도 반환하지 않는다.
member['이메일'] # error 발생
member.get('이메일', '없음') # 원하는 값이 없을 때 대체값으로 반환
Python
복사
홍길동
없음
8. 튜플

8-1. 튜플 특징
•
() 로 표현
•
원소들 변경 불가
•
괄호를 생략할 수 있지만 ‘ , ‘는 생략하면 안된다.
•
여러 변수에 동시에 값을 대입할 수 있다는 장점이 있다.
a, b, c = 10, 20, 30
print('a =', a)
print('b =', b)
print('c =', c)
Python
복사
a = 10
b = 20
c = 30
Plain Text
복사
8-2. 다양한 튜플 만들기
# 빈 튜플
score = ()
# 요소가 하나인 튜플
score = (90,)
# 또는
score = 90,
# 여러 형태의 튜플 만들기
score1 = (90, 85, 70)
score2 = 90, 85, 70
score3 = (90, 85, 70, ('A', 'B', 'D', 'F'))
Python
복사
(90, 85, 70)
(90, 85, 70)
(90, 85, 70, ('A', 'B', 'D', 'F'))
Plain Text
복사
8-3. 튜플 원소 조회하기
리스트와 마찬가지로 인덱스로 조회한다.
t = (1,2,3,4,5,[1,2,3,4,5])
print(t[-1])
t[-1][0] = 10 # 리스트 내 원소 바꾸기는 가능
print(t)
Python
복사
[1, 2, 3, 4, 5]
(1, 2, 3, 4, 5, [10, 2, 3, 4, 5])
8-4. range 와 tuple
range() 함수를 이용해서 튜플 만들기
nums = tuple(range(0,11))
print(nums)
Python
복사
(0,1,2,3,4,5,6,7,8,9,10)
8-5. 문자열로 튜플만들기
chars = tuple('PYTHON')
print(chars)
Python
복사
('P', 'Y', 'T', 'H', 'O', 'N')
8-6. 튜플의 성질 이용하기
•
함수 리턴값을 두 변수에 대입할 수 있다.
a,b = 45, 20
x, y = divmod(a, b) # a를 b로 나눴을 때의 몫과 나머지를 동시에 튜플로 반환
print(x, y)
Python
복사
2 5
8-7. ‘ + ‘ 연산자
•
‘ + ‘ 연산자를 사용해서 두 개의 튜플을 결합하여 새로운 튜플을 만들 수 있다.
score1 = (90, 85, 70, 95)
score2 = (80, 85, 65, 90)
score3 = score1 + score2
# 확인
score3
Python
복사
(90, 85, 70, 95, 80, 85, 65, 90)
# 튜플 요소 여러 번 반복
score1 = (90, 85, 70, 95)
score2 = score1 * 2
# 확인
score2
Python
복사
(90, 85, 70, 95, 90, 85, 70, 95)
# 나와 친구가 좋아하는 번호를 합치되 번호가 중복되지 않게 하는 프로그램
myNums = (1,3,5,6,7)
fdNums = (2,3,5,8,10)
print('myFavoriteNumbers = {}'.format(myNums))
print('friendFavoriteNumbers = {}'.format(fdNums))
for num in fdNums:
if num not in myNums:
myNums = myNums + (num, )
print('myNums : {}'.format(myNums))
# myFavoriteNumbers = (1, 3, 5, 6, 7)
# friendFavoriteNumbers = (2, 3, 5, 8, 10)
# addNumbers = (1, 3, 5, 6, 7, 2, 3, 5, 8, 10)
Python
복사
리스트에서 사용한 extend() 함수는 사용할 수 없다 → 기존의 튜플은 변경할 수 없으므로튜플 슬라이싱 - 인덱스, slice()
리스트와 마찬가지로 인덱스를 사용해서 특정 원소를 뽑거나 슬라이싱을 이용해서 여러 원소를 뽑아낼 수도 있다.

하지만, 슬라이싱을 이용해서 튜플의 값을 변경할 수는 없다. 리스트
리스트물론, 리스트의 슬라이싱에서 이렇게 사용하는 것은 가능하다.
students = ['임선주','강호동','나영석','김영철','나연서']
students[1:3] = ('유재석','김영석')
print('students: {}'.format(students))
print(type(students))
# students: ['임선주', '유재석', '김영석', '김영철', '나연서'] # -> 리스트 원소에 튜플이 들어가는 것은 아니다.
# <class 'list'>
Python
복사
•
slice() 함수를 이용해서 똑같이 슬라이싱 할 수 있다 ( = 리스트)
튜플 정렬 - 리스트 변환 후 sort() / sorted()
튜플을 정렬하는 두 가지 방식이 있다.
•
튜플은 정렬 함수를 쓸 수 없기 때문에, 리스트로 변환 후 정렬 한 뒤에 다시 튜플로 변환하면 된다.
◦
list() → 리스트 변환
◦
sort() → 정렬
◦
tuple() → 다시 튜플 변환
•
sorted() 함수
튜플에도 sorted() 함수를 적용할 수 있다. 하지만 적용 후 리스트로 반환한다. 따라서 튜플로 변환해줘야 한다.
◦
sorted() → 튜플에 정렬, 리스트로 반환(새로운 변수가 생성되는 것)
◦
tuple() → 튜플로 변환
playerScore = (9.5,8.9,9.2,9.8,8.8,9.0)
sorted_list = sorted(playerScore)
print('sorted 결과 값: {}'.format(sorted_list)
playerScore = tuple(sorted_list)
print('playerScore : {}.'format(playerScore))
# sorted 결과 값: [8.8, 8.9, 9.0, 9.2, 9.5, 9.8]
# playerScore : (8.8, 8.9, 9.0, 9.2, 9.5, 9.8)
Python
복사
튜플과 for문 (1)
리스트와 조회하는 방법은 모두 동일하다.
심지어, 아래 코드처럼 튜플 안 튜플원소들을 한꺼번에 조회하는 것도 동일하다.
studentCnts = (1,19),(2,20),(3,22),(4,18),(5,21)
for classNo, cnt in studnetCnts: # -> 리스트 원소의 리스트 아이템 0,1번째 인덱스에 바로 접근 가능
print('{}학급 학생수: {}'.format(classNo, cnt))
#1학급 학생수: 19
#2학급 학생수: 20
#3학급 학생수: 22
#4학급 학생수: 18
#5학급 학생수: 21
Python
복사
# 학급별 학생수, 전체 학생수, 평균 학생수를 출력
studentCnts = (1,19),(2,20),(3,22),(4,18),(5,21),(6,22),(7,17)
sum = 0
avg = 0
for classNo, cnt in studentCnts:
print('{}학급 학생수: {}명'.format(classNo, cnt))
sum += cnt
print('전체 학생 수 : {}명'.format(sum))
print('평균 학생 수 : %.2f명'%(sum / len(studentCnts)))
# 1학급 학생수: 19명
# 2학급 학생수: 20명
# 3학급 학생수: 22명
# 4학급 학생수: 18명
# 5학급 학생수: 21명
# 6학급 학생수: 22명
# 7학급 학생수: 17명
# 전체 학생 수 : 139명
# 평균 학생 수 : 19.86명
Python
복사
튜플과 for문(2)
# 국어, 영어, 수학, 과학, 국사 점수를 입력하면 과락 과목과 점수를 출력하는 프로그램
minScore = 60
kor = int(input('국어 점수 입력: '))
eng = int(input('영어 점수 입력: '))
mat = int(input('수학 점수 입력: '))
sci = int(input('과학 점수 입력: '))
his = int(input('국사 점수 입력: '))
scores = (
('국어',kor),
('영어',eng),
('수학',mat),
('과학',sci),
('국사',his)
)
for subj, score in scores:
if score < minScore:
print('과락 과목 : {}, 점수 : {}'.format(subj, score))
Python
복사
# 학급 학생 수가 가장 작은 학급과 가장 많은 학급을 출력하자
studentCnts = (
(1,18),
(2,19),
(3,23),
(4,21),
(5,20),
(6,22),
(7,17)
)
minCnt = 0; minClassNo = 0
maxCnt = 0; maxClassNo = 0
for classno, Cnt in studentCnts:
if minCnt == 0 or Cnt < minCnt: # 초기에는 minCnt = 0이라는 점을 고려해서
minCnt = Cnt
minClassNo = classno
if Cnt > maxCnt:
maxCnt = Cnt
maxClassNo = classno
print('학생 수가 가장 적은 학급(학생수): {}학급({}명)'.format(minClassNo,minCnt))
print('학생 수가 가장 많은 학급(학생수): {}학급({}명)'.format(maxClassNo,maxCnt))
Python
복사
4. Tips for Tuple
isinstance
자료형이 맞는지 틀리는지 (True/False) 를 반환
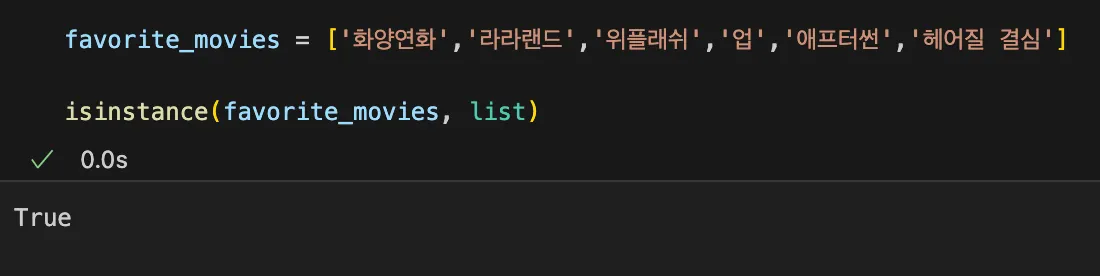 응용하기
응용하기 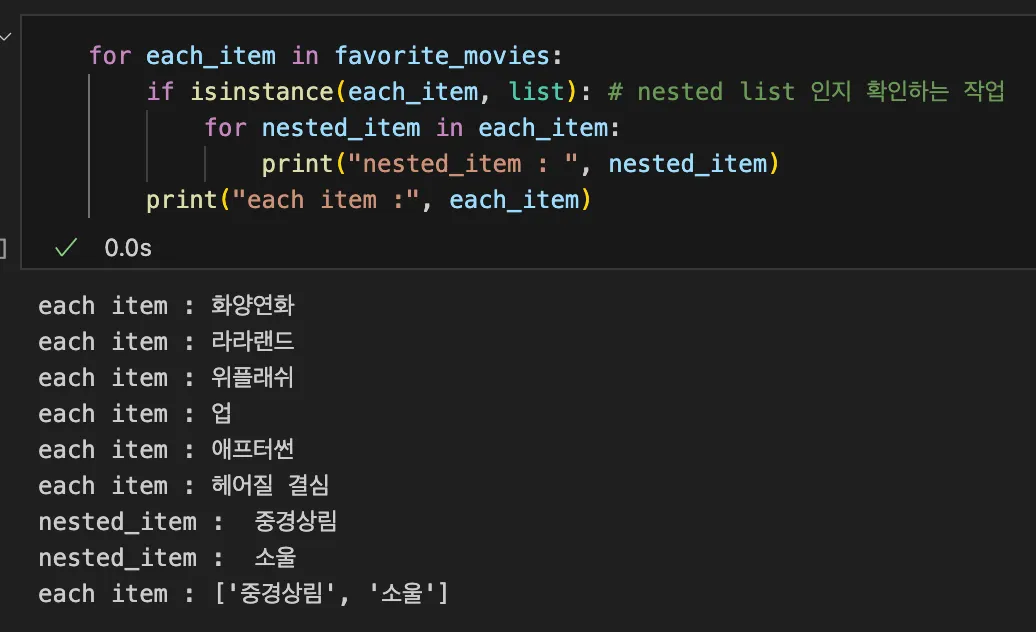
9. set 집합 자료형
•
집합 연산(교집합, 합집합, 차집합, 대칭 차집합)을 위한 자료형이다.
•
중복을 허용하지 않아 중복을 제거할 때 주료 사용된다.
•
순서의 의미가 없기때문에 인덱싱 / 슬라이싱 이용 불가다.
•
리스트를 원소로 가질 수 없다. (즉, 변동 가능한 자료형은 원소로 사용 불가)
9-1. 집합 만들기
nums = {1,2,3,4,5}
# 문자열을 갖는 집합
members = {'홍길동','일지매','강호동','한사랑'}
# 여러 자료형을 갖는 집합
etc = {'한사랑', 2, 3,'한국', True}
Python
복사
9-2. 집합으로 자료형 변환
•
set()
다른 자료형을 집합으로 변환한다.
개별 문자를 요소로 갖는 집합을 만들어준다.
# 문자열 -> 집합
hello = set('잘지내지요')
hello
# 리스트 -> 집합 (중복은 알아서 제거된다.)
member = ['홍길동', '한사랑', '홍길동', '일지매', '박여인']
member1 = set(member)
member1
# 튜플 -> 집합(중복은 알아서 제거된다)
member = ('홍길동', '한사랑', '홍길동', '일지매', '박여인')
member2 = set(member)
member2
Python
복사
{'내', '요', '잘', '지'}
{'박여인', '일지매', '한사랑', '홍길동'}
{'박여인', '일지매', '한사랑', '홍길동'}
•
range() 와 집합
nums = set(range(0,10))
nums
Python
복사
{0,1,2,3,4,5,6,7,8,9}
9-3. 집합 정보 확인
•
len()
집합 원소의 개수를 확인한다.
member1 = {'홍길동', '한사랑', '일지매', '박여인'}
member2 = {'김치국', '안경태', '이리와'}
# 확인
print(len(member1), len(member2))
Python
복사
4 3
•
in / not in
원소의 포함 여부를 확인한다.
print('홍길동' in member1)
print('홍길동' in member2)
Python
복사
True
False
9-4. 집합 응용하기
•
리스트 중복 요소를 제거할 때 사용
nums = [12, 45, 23, 21, 36, 28, 12, 36, 35, 28, 45, 63, 12, 21]
nums = set(nums)
nums = list(nums)
nums
Python
복사
[35, 36, 12, 45, 21, 23, 28, 63]
•
튜플 중복 요소 제거할 때 사용
nums = (12, 45, 23, 21, 36, 28, 12, 36, 35, 28, 45, 63, 12, 21)
nums = tuple(set(nums))
nums
Python
복사
(35, 36, 12, 45, 21, 23, 28, 63)
9-5. 집합 연산
•
합집합
union() 또는 | 기호를 사용한다.
member_set1 = {'홍길동', '한사랑', '일지매', '박여인'}
member_set2 = {'한사랑', '홍길민', '강우동'}
# 합집합 구하기 #
member_set3 = member_set1.union(member_set2)
member_set3 = member_set1 | member_set2 # 같은 결과
member_set3
Python
복사
{'강우동', '박여인', '일지매', '한사랑', '홍길동', '홍길민'}
•
교집합
intersection() 또는 & 기호를 사용한다.
# 교집합 구하기 #
member_set3 = member_set1 & member_set2
member_set3 = member_set1.intersection(member_set2)
Python
복사
{'한사랑'}
•
차집합
difference() 또는 - 기호를 사용한다.
# 차집합 구하기 #
member_set3 = member_set1 - member_set2
member_set3 = member_set1.difference(member_set2) # 순서 주의
Python
복사
{'박여인', '일지매', '홍길동'}
•
대칭차집합
대칭차집합은 ‘합집합 - 교집합’ 에 해당한다.
symmetric_difference() 또는 ^ 기호를 사용한다.
# 대칭 차집합 구하기 #
member_set3 = member_set1 ^ member_set2
member_set3 = member_set1.symmetric_difference(member_set2)
Python
복사
{'강우동', '박여인', '일지매', '홍길동', '홍길민'}
9-6. 집합 연산 응용
•
교집합을 이용해 두 리스트 사이의 중복된 요소를 확인
nums1 = [12, 23, 32, 36, 41, 48]
nums2 = [12, 19, 24, 32, 36, 47]
nums = set(nums1) & set(nums2)
nums = list(nums)
Python
복사
[32, 36, 12]
•
합집합을 이용해 두 리스트의 중복된 요소를 제거하면서 합칠 수 있다.
nums = set(nums1) | set(nums2)
nums = list(nums)
nums
Python
복사
[32, 36, 41, 12, 47, 48, 19, 23, 24]
9-7. 집합 관련 메서드
•
요소 하나 추가 : add()
member_set = {'홍길동', '한사랑', '일지매', '박여인'}
# 원소 하나 추가, 순서는 의미가 없음
member_set.add('강우동')
member_set
Python
복사
{'강우동', '박여인', '일지매', '한사랑', '홍길동'}
•
여러 요소 추가 : update()
member_set = {'홍길동', '한사랑', '일지매', '박여인'}
# 여러 원소(리스트, 튜플, 딕셔너리) 추가
member_set.update(['한국인', '나도야'])
member_set
Python
복사
{'나도야', '박여인', '일지매', '한국인', '한사랑', '홍길동'}
•
무작위로 한 요소 삭제 : pop()
리스트, 딕셔너리에서와 달리 집합에서 pop()은 무작위로 원소를 제거한다.
member_set = {'홍길동', '한사랑', '일지매', '박여인'}
del_member = member_set.pop()
print(member_set)
print(del_member)
Python
복사
{'일지매', '박여인', '한사랑'}
홍길동
Plain Text
복사
•
지정 요소 삭제 : remove()
삭제하려는 요소가 없을 경우, 에러난다.
member_set = {'홍길동', '한사랑', '일지매', '박여인'}
# 원소 하나 삭제
member_set.remove('일지매')
# 확인
member_set
member_set.remove('한국인')
# 확인
member_set
Python
복사
{'박여인', '한사랑', '홍길동'}
KeyError: '한국인'
•
지정 요소 삭제 : discard()
remove()와 달리 삭제하려는 요소가 없어도 오류가 발생하지 않는다.
member_set = {'홍길동', '한사랑', '일지매', '박여인'}
# 없는 원소를 삭제하면 무시
member_set.discard('홍길동')
member_set.discard('한국인') # 아무것도 반환하지 않음.
member_set
Python
복사
{'박여인', '일지매', '한사랑'}
•
집합 초기화 : clear()
member_set = {'홍길동', '한사랑', '일지매', '박여인'}
# 모든 원소 삭제
member_set.clear()
member_set
Python
복사
set()