
K-겹 교차 검증(K-Fold Cross - Validation)
다양한 유형의 교차 검증 방법이 있지만, 가장 일반적인 방법은 k - 겹 교차 검증이다.
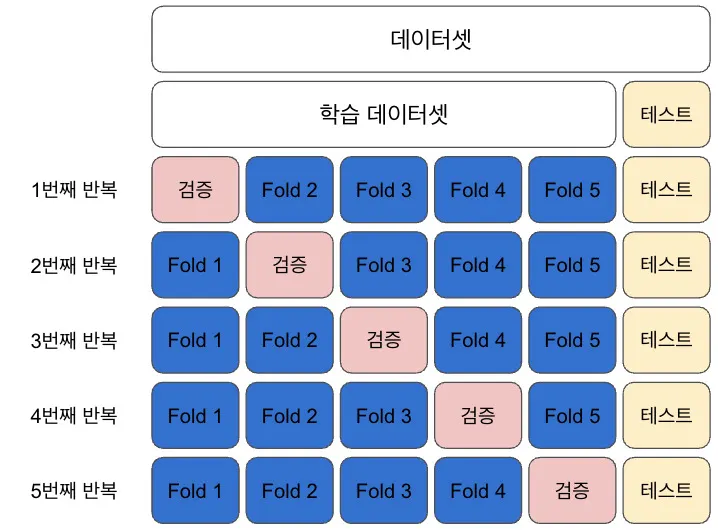
교차검증의 개수 k는 일반적으로 5 또는 10으로 설정한다.
사이킷런 KFold
from sklearn.model_selection import KFold
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
import numpy as np
# iris 데이터셋 로드
iris = load_iris()
X, y = iris.data, iris.target
# KFold 분할기 인스턴스 생성 (5-겹 교차 검증)
kf = KFold(n_splits=5, shuffle=True, random_state=42)
# 정확도 점수를 저장할 리스트
accuracy_scores = []
# KFold로 데이터를 분할
for train_index, test_index in kf.split(X):
# 분할된 훈련 및 테스트 데이터 생성
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
# 모델 생성 및 훈련
model = RandomForestClassifier(random_state=42)
model.fit(X_train, y_train)
# 예측 및 정확도 계산
predictions = model.predict(X_test)
accuracy = accuracy_score(y_test, predictions)
# 정확도 점수를 리스트에 추가
accuracy_scores.append(accuracy)
# 각 폴드에서의 정확도 출력
print("각 폴드에서의 정확도:", accuracy_scores)
# 평균 정확도 계산 및 출력
print("평균 정확도:", np.mean(accuracy_scores))
Python
복사
각 폴드에서의 정확도: [1.0, 0.9666666666666667, 0.9333333333333333, 0.9333333333333333, 0.9666666666666667]
평균 정확도: 0.9600000000000002
사이킷런 cross_val_score
cv 에 할당한 개수만큼 교차검증을 수행하고, 성능을 평가해 cv에 할당한 개수만큼의 점수를 반환한다.
매개변수
from sklearn.moedel_selection import cross_val_score
# 모델 초기화
model = RandomForestClassifier()
# 회귀 문제
scores = cross_val_score(model, X, y, scoring='neg_mean_squared_error',cv=10) # 교차검증 10개
모델_rmse_scores = np.sqrt(-scores)
print('평균 점수:', 모델_rmse_scores.mean())
Python
복사
※ 참고 ※

scoring 매개변수에서는 값이 클수록 좋은 결과라고 판단한다. 하지만 예를 들어 MSE 지표같은 경우에는 값이 작을수록 좋은 것이기 때문에 그대로 사용하면 잘못된 결과를 가져올 것이다. 따라서 이럴때는 neg_mean_squared_error 를 사용해서 scoring 매개변수의 정의에 맞게 사용한 다음 추후 실제 점수값을 확인할 때만 다시 ‘-’ 를 붙여주면 된다.
cross_val_predict() 함수는 cross_val_score() 과 마찬가지로 k겹 교차 검증을 수행하지만 평가 점수를 반환하는 것이 아니라 각 테스트 폴드에서 얻은 예측값을 반환한다.
•
적절한 임곗값 정하기
from sklearn.model_selection import cross_val_predict
# 훈련 세트에 있는 모든 샘플의 점수를 구하기
y_scores = cross_val_predict(estimator, X_train, y_train, cv=k, method='decision_function')
Python
복사
cv 값을 따로 지정해주지 않거나(default=5) 정수값으로 지정해줄 경우, estimator가 분류기이고 이진분류 또는 다중분류일 경우 알아서 StratifiedKFold 교차검증으로 진행한다. 하지만 그 외에는 KFold 교차검증으로 진행한다.
# precision_recall_curve() 로 모든 임곗값에 대해 정밀도와 재현율 계산하기
from sklearn.metrics import precision_recall_curve
precisions, recalls, thresholds = precision_recall_curve(y_train, y_scores)
Python
복사
precision_recall_curve() 는 이진분류에서만 사용 가능하다.
•
The last precision and recall values are 1. and 0. respectively and do not have a corresponding threshold. This ensures that the graph starts on the y axis.
# 임곗값의 함수로 정밀도와 재현율 그리기
def plot_precision_recall_vs_threshold(precisions,recalls,thresholds):
plt.plot(thresholds,precisions[:-1], 'b--', label='정밀도')
plt.plot(thresholds,precisions[:-1], 'g-', label='재현율')
plt.xlabel('임곗값')
plt.legend('best')
plt.grid(True)
plot_precision_recall_vs_threshold(precisions, recalss, thresholds)
plt.show()
Python
복사
# 재현율에 대한 정밀도 곡선을 그리기 -> 트레이드 오프 선택하기
# plot_precision_recall_curve() : 이진분류만 가능
from sklearn.metrics import plot_precision_recall_curve
plot_precision_recall_curve(모델, X_train, y_train, response_method='auto')
Python
복사
재현율 정밀도 곡선을 통해 그래프가 급격히 하강하는 직전을 트레이드오프로 선택하는 것이 좋다.
하지만 목표에 따라 트레이드오프를 선택하는 기준은 달라지는데, 예를 들어 정밀도 90% 를 달성하고 싶다고 하면 아래와 같이 임곗값을 설정해주고
# np.argmax() 는 최댓값의 첫 번째 인덱스를 반환해준다.
threshold_90_precision = thresholds[np.argmax(precisions >= 0.9)] # 정밀도 0.9 이상이 되는 최댓값(1=True)의 가장 첫번째 인덱스
Python
복사
훈련세트의 예측값은 다음과 같이 계산하게된다.
y_train_pred_90 = (y_scores >= threshold_90_precision)
Python
복사
해당 임곗값에서의 정밀도와 재현율을 확인해보면
precision_score(y_train, y_train_pred_90) # 임의의 임곗값에서의 정밀도
recall_score(y_train, y_train_pred_90) # 임의의 임곗값에서의 재현율
Python
복사
가끔, 교차 검증 과정을 더 많이 제어해야 할 필요가 있다. 이때는 교차 검증 기능을 직접 구현하는 것이 나은데, 사이킷런의 cross_val_score와 같은 작업을 수행하고 동일한 결과를 출력해준다.
StratifiedKFold 는 클래스별 비율이 유지되도록 폴드를 만들기 위해 계층적 샘플링을 해준다.
from sklearn.model_selection import StratifiedKFold
from sklearn.base import clone # 모델을 복제하기 위해서 사용하는 메소드
skfolds = StratifiedKFold(n_splits=3, random_state=0, shuffle=True)
for train_index, test_index in skfolds.split(X_train,y_train):
clone_model = clone(임의의model)
X_train_folds = X_train[train_index]
y_train_folds = y_train[train_index]
X_test_folds = X_test[test_index]
y_test_folds = y_test[test_index]
clone_model.fit(X_train_folds, y_train_folds)
y_pred = clone_model.predict(X_test_folds)
n_correct = sum(y_pred == y_test_folds)
print(n_correct / len(y_pred)) # 각 폴드에서의 예측 정확도를 출력
Python
복사
매 반복마다 분류기 객체를 복제해서 훈련 폴드로 훈련시키고 테스트 폴드로 예측을 만든다. 올바른 예측 수를 세어 정확한 예측 비율을 출력한다.