

drop_duplicates([’기준 컬럼’], keep = ‘방식’)
특정 컬럼을 기준으로 중복되는 값들을 제거하고 싶을 때 사용한다.
ex) drop_duplicates([’date’], keep = ‘first’) : ‘date’ 가 중복될 경우, 맨 첫번째 값만 남기고 나머지는 제거한다.
•
모든 변수의 값이 중복될때 제거(default)
df.drop_duplicates()
Python
복사
TIP 1 : 중복되는 데이터값들(변수들)만 모아 하나의 행으로 만들고자 할 때
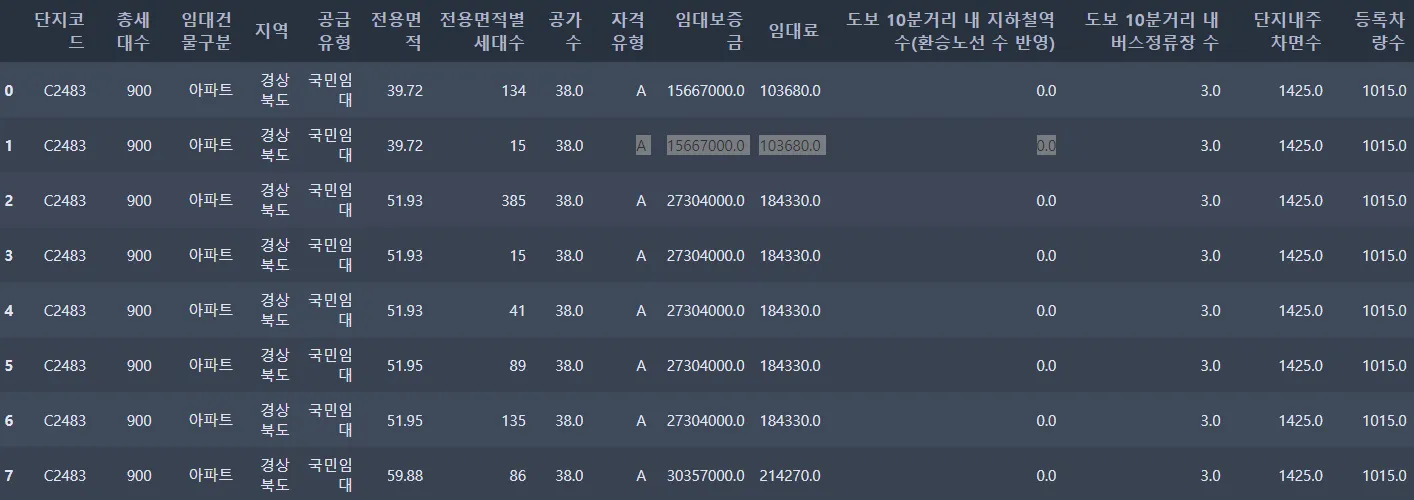
위와 같은 데이터에서 중복되는 값들이 있는 변수들이 있다.
원하는 데이터의 형태가 단지코드 별 하나의 행일 경우,
중복되는 데이터들을 따로 모아 중복을 제거해주고 단지코드가 key column 이 될 수 있도록 해주는 작업이 필요하다.
# 단지코드가 C2483 인 경우의 처리만 예시로
df.columns[df[df.단지코드=='C2483'].nunique()==1]
Python
복사