

캐글의 산탄데르 고객 만족 데이터를 가지고 XGBoost와 LightGBM을 활용해 예측을 해보겠다. 먼저, 이 데이터는 370개의 피처로 이루어져 있고, 고객 만족 여부를 예측하는 것이다.
피처 이름은 모두 익명 처리로 되어있기 때문에 어떤 속성인지는 추정할 수 없다.
클래스 레이블 명은 TARGET이며, 1이면 불만을 가진 고객, 0이면 만족한 고객이다.
모델의 성능 평가는 ROC-AUC로 평가한다. 레이블이 불균형할 경우에는(불만족한 고객의 수가 적을 가능성이 더 크기 때문에) 정확도보다는 ROC-AUC로 평가하는 것이 좋다.
train.csv를 다운받고 데이터 전처리를 시작한다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
cust_df = pd.read_csv('train_santander.csv',encoding='latin-1')
print('dataset shape:',cust_df.shape) # 전체 데이터수와 피처 수를 확인할 수 있다.
cust_df.head(3)
Python
복사
전체 371개의 피처와 76020개의 데이터가 있다는 것을 확인.
좀더 요약된 정보를 확인해본다.
cust_df.info()
'''
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 76020 entries, 0 to 76019
Columns: 371 entries, ID to TARGET
dtypes: float64(111), int64(260)
memory usage: 215.2 MB
'''
Python
복사
모든 피처가 숫자형이고, null값은 없다.
클래스 레이블의 분포를 살펴본다. (TARGET값의 분포를 확인한다.)
print(cust_df['TARGET'].value_counts())
unsatisfied_cnt = cust_df[cust_df['TARGET']==1].TARGET.count()
total_cnt = cust_df.TARGET.count()
print('unsatisfied 비율은 {0:.2f}'.format((unsatisfied_cnt/total_cnt)))
'''
0 73012
1 3008
Name: TARGET, dtype: int64
unsatisfied 비율은 0.04
'''
Python
복사
대부분 만족이고 불만족인 고객은 전체에서 4%밖에 되지 않는다.
마지막으로 describe() 메서드를 사용해서 다른 피처들의 분포도 확인한다.
cust_df.describe()
Python
복사
전체 피처들의 분포에 대한 요약값으로 Nan값이나 이상치들을 확인할 수 있다.
먼저, var3같은 경우 min이 -999999로 되어있는데, 전체 분포를 확인해보면 이상치라는 것을 확인할 수 있다. 너무 편차가 심한 값이므로 가장 값이 많은 2로 변환해본다.
ID피처는 단순히 식별자이기 때문에 drop 한다.
cust_df['var3'].replace(-999999,2,inplace=True) #'var3'의 이상치 변환
cust_df.drop('ID',axis=1,inplace=True) # 'ID' 열 제거
Python
복사
이제, 피처세트와 레이블 세트를 분리한다.
X_feautures = cust_df.iloc[:,:-1] # 맨 마지막 열 제외하고 전체
y_labels = cust_df.iloc[:,-1]
print('피처 데이터 shape:{0}'.format(X_features.shape))
'''
피처 데이터 shape:(76020, 369)
'''
Python
복사
이제, 학습데이터와 테스트데이터를 분리해보겠다. 참고로, 레이블값 분포가 비대칭이라서 TARGET값 분포도가 각 데이터세트에 모두 비슷하게 추출됐는지 확인도 해준다.
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X_features,y_labels,test_size=0.2,random_state=0)
train_cnt = y_train.count() # 전체 데이터 개수
test_cnt = y_test.count() # 전체 데이터 개수
print('학습 세트 shape:{0}, 테스트 세트 shape:{1}'.format(X_train.shape,X_test.shape))
'''
학습 세트 shape:(60816, 369), 테스트 세트 shape:(15204, 369)
'''
print('학습 세트 레이블 값 분포 비율')
print(y_train.value_counts()/train_cnt)
print('\n 테스트 세트 레이블 값 분포 비율')
print(y_test.value_counts()/test_cnt)
'''
학습 세트 레이블 값 분포 비율
0 0.960964
1 0.039036
Name: TARGET, dtype: float64
테스트 세트 레이블 값 분포 비율
0 0.9583
1 0.0417
Name: TARGET, dtype: float64
'''
Python
복사
학습세트와 테스트세트 모두 원본 TARGET 레이블 값의 분포와 유사하게 4%정도의 불만족 값을 가지고 있는 것을 확인할 수 있다.
XGBoost의 모델 학습과 하이퍼 파라미터 튜닝
n_estimators를 500으로, early_stopping_rounds를 100으로 , eval_metric을 ‘auc’로 , eval_set=[(X_train,y_train), (X_test, y_test)] 로 설정한다.
from xgboost import XGBClassifier
from sklearn.metrics import roc_auc_score
# n_estimators는 500, random_state는 예제 수행 시마다 동일 예측 결과를 위해 설정.
xgb_clf = XGBClassifier(n_estimators=500, random_state=156)
# 성능 평가 지표를 auc, 조기 중단 파라미터는 100으로 설정하고 학습 수행.
xgb_clf.fit(X_train,y_train,early_stopping_rounds=100,eval_metric='auc',eval_set=[(X_train,y_train),(X_test,y_test)])
xgb_roc_score = roc_auc_score(y_test,xgb_clf.predict_proba(X_test)[:,1],average='macro')
print('ROC AUC: {0:.4f}'.format(xgb_roc_score))
'''
[0] validation_0-auc:0.82005 validation_1-auc:0.81157
[1] validation_0-auc:0.83400 validation_1-auc:0.82452
[2] validation_0-auc:0.83870 validation_1-auc:0.82746
[3] validation_0-auc:0.84419 validation_1-auc:0.82922
[4] validation_0-auc:0.84783 validation_1-auc:0.83298
[5] validation_0-auc:0.85125 validation_1-auc:0.83500
[6] validation_0-auc:0.85501 validation_1-auc:0.83653
[7] validation_0-auc:0.85831 validation_1-auc:0.83782
[8] validation_0-auc:0.86143 validation_1-auc:0.83802
[9] validation_0-auc:0.86452 validation_1-auc:0.83914
[10] validation_0-auc:0.86717 validation_1-auc:0.83954
[11] validation_0-auc:0.87013 validation_1-auc:0.83983
[12] validation_0-auc:0.87369 validation_1-auc:0.84033
[13] validation_0-auc:0.87620 validation_1-auc:0.84054
[14] validation_0-auc:0.87799 validation_1-auc:0.84135
[15] validation_0-auc:0.88072 validation_1-auc:0.84117
[16] validation_0-auc:0.88238 validation_1-auc:0.84101
[17] validation_0-auc:0.88354 validation_1-auc:0.84071
[18] validation_0-auc:0.88458 validation_1-auc:0.84052
[19] validation_0-auc:0.88592 validation_1-auc:0.84023
[20] validation_0-auc:0.88790 validation_1-auc:0.84012
[21] validation_0-auc:0.88846 validation_1-auc:0.84022
[22] validation_0-auc:0.88980 validation_1-auc:0.84007
[23] validation_0-auc:0.89019 validation_1-auc:0.84009
[24] validation_0-auc:0.89195 validation_1-auc:0.83974
[25] validation_0-auc:0.89255 validation_1-auc:0.84015
[26] validation_0-auc:0.89332 validation_1-auc:0.84101
[27] validation_0-auc:0.89389 validation_1-auc:0.84088
[28] validation_0-auc:0.89420 validation_1-auc:0.84074
[29] validation_0-auc:0.89665 validation_1-auc:0.83999
[30] validation_0-auc:0.89741 validation_1-auc:0.83959
[31] validation_0-auc:0.89916 validation_1-auc:0.83952
[32] validation_0-auc:0.90106 validation_1-auc:0.83901
[33] validation_0-auc:0.90253 validation_1-auc:0.83885
[34] validation_0-auc:0.90278 validation_1-auc:0.83887
[35] validation_0-auc:0.90293 validation_1-auc:0.83864
[36] validation_0-auc:0.90463 validation_1-auc:0.83834
[37] validation_0-auc:0.90500 validation_1-auc:0.83810
[38] validation_0-auc:0.90519 validation_1-auc:0.83810
[39] validation_0-auc:0.90533 validation_1-auc:0.83813
[40] validation_0-auc:0.90575 validation_1-auc:0.83776
[41] validation_0-auc:0.90691 validation_1-auc:0.83720
[42] validation_0-auc:0.90716 validation_1-auc:0.83684
[43] validation_0-auc:0.90737 validation_1-auc:0.83672
[44] validation_0-auc:0.90759 validation_1-auc:0.83674
[45] validation_0-auc:0.90769 validation_1-auc:0.83693
[46] validation_0-auc:0.90779 validation_1-auc:0.83686
[47] validation_0-auc:0.90793 validation_1-auc:0.83678
[48] validation_0-auc:0.90831 validation_1-auc:0.83694
[49] validation_0-auc:0.90871 validation_1-auc:0.83676
[50] validation_0-auc:0.90892 validation_1-auc:0.83655
[51] validation_0-auc:0.91070 validation_1-auc:0.83669
[52] validation_0-auc:0.91240 validation_1-auc:0.83641
[53] validation_0-auc:0.91354 validation_1-auc:0.83690
[54] validation_0-auc:0.91389 validation_1-auc:0.83693
[55] validation_0-auc:0.91408 validation_1-auc:0.83681
[56] validation_0-auc:0.91548 validation_1-auc:0.83680
[57] validation_0-auc:0.91560 validation_1-auc:0.83667
[58] validation_0-auc:0.91631 validation_1-auc:0.83664
[59] validation_0-auc:0.91729 validation_1-auc:0.83591
[60] validation_0-auc:0.91765 validation_1-auc:0.83576
[61] validation_0-auc:0.91788 validation_1-auc:0.83534
[62] validation_0-auc:0.91876 validation_1-auc:0.83513
[63] validation_0-auc:0.91896 validation_1-auc:0.83510
[64] validation_0-auc:0.91900 validation_1-auc:0.83508
[65] validation_0-auc:0.91911 validation_1-auc:0.83518
[66] validation_0-auc:0.91975 validation_1-auc:0.83510
[67] validation_0-auc:0.91986 validation_1-auc:0.83523
[68] validation_0-auc:0.92012 validation_1-auc:0.83457
[69] validation_0-auc:0.92019 validation_1-auc:0.83460
[70] validation_0-auc:0.92029 validation_1-auc:0.83446
[71] validation_0-auc:0.92041 validation_1-auc:0.83462
[72] validation_0-auc:0.92093 validation_1-auc:0.83394
[73] validation_0-auc:0.92099 validation_1-auc:0.83410
[74] validation_0-auc:0.92140 validation_1-auc:0.83394
[75] validation_0-auc:0.92148 validation_1-auc:0.83368
[76] validation_0-auc:0.92330 validation_1-auc:0.83413
[77] validation_0-auc:0.92424 validation_1-auc:0.83359
[78] validation_0-auc:0.92512 validation_1-auc:0.83353
[79] validation_0-auc:0.92549 validation_1-auc:0.83293
[80] validation_0-auc:0.92586 validation_1-auc:0.83253
[81] validation_0-auc:0.92686 validation_1-auc:0.83187
[82] validation_0-auc:0.92714 validation_1-auc:0.83230
[83] validation_0-auc:0.92810 validation_1-auc:0.83216
[84] validation_0-auc:0.92832 validation_1-auc:0.83206
[85] validation_0-auc:0.92878 validation_1-auc:0.83196
[86] validation_0-auc:0.92883 validation_1-auc:0.83200
[87] validation_0-auc:0.92890 validation_1-auc:0.83208
[88] validation_0-auc:0.92928 validation_1-auc:0.83174
[89] validation_0-auc:0.92950 validation_1-auc:0.83160
[90] validation_0-auc:0.92958 validation_1-auc:0.83155
[91] validation_0-auc:0.92969 validation_1-auc:0.83165
[92] validation_0-auc:0.92974 validation_1-auc:0.83172
[93] validation_0-auc:0.93042 validation_1-auc:0.83160
[94] validation_0-auc:0.93043 validation_1-auc:0.83150
[95] validation_0-auc:0.93048 validation_1-auc:0.83132
[96] validation_0-auc:0.93094 validation_1-auc:0.83090
[97] validation_0-auc:0.93102 validation_1-auc:0.83091
[98] validation_0-auc:0.93179 validation_1-auc:0.83066
[99] validation_0-auc:0.93255 validation_1-auc:0.83058
[100] validation_0-auc:0.93296 validation_1-auc:0.83029
[101] validation_0-auc:0.93370 validation_1-auc:0.82955
[102] validation_0-auc:0.93369 validation_1-auc:0.82962
[103] validation_0-auc:0.93448 validation_1-auc:0.82893
[104] validation_0-auc:0.93460 validation_1-auc:0.82837
[105] validation_0-auc:0.93494 validation_1-auc:0.82815
[106] validation_0-auc:0.93594 validation_1-auc:0.82744
[107] validation_0-auc:0.93598 validation_1-auc:0.82728
[108] validation_0-auc:0.93625 validation_1-auc:0.82651
[109] validation_0-auc:0.93632 validation_1-auc:0.82650
[110] validation_0-auc:0.93673 validation_1-auc:0.82621
[111] validation_0-auc:0.93678 validation_1-auc:0.82620
[112] validation_0-auc:0.93726 validation_1-auc:0.82591
[113] validation_0-auc:0.93797 validation_1-auc:0.82498
[114] validation_0-auc:0.93809 validation_1-auc:0.82525
ROC AUC: 0.8413
'''
Python
복사
예측시 ROC AUC가 약 0.8413이다.
이제, XGBoost의 하이퍼 파라미터 튜닝을 진행해보자. 칼럼의 개수가 많으니(371개) 과적합 가능성을 가정하고
max_depth, min_child_weight(GBM의 min_samples_leaf와 유사), colsample_bytree 하이퍼 파라미터만 일차 튜닝 대상으로 해보자.
일반적으로 max_depth는 3~10사이의 값으로 지정한다.
복잡한 모델일수록 하이퍼 파라미터의 튜닝 팁은 먼저 2~3개 정도의 파라미터를 결합해 최적 파라미터를 찾아낸 다음, 이 최적 파라미터를 기반으로 다시 1~2개 파라미터를 결합해 파라미터 튜닝을 진행한다.
이제 GridSearchCV를 통해서 하이퍼파라미터 최적의 조합을 찾아보자. 먼저 파라미터의 경우의 수가 8개나 되므로 일단 n_estimators를 100으로 줄이고 early_stopping_rounds도 30으로 줄인다.
from sklearn.model_selection import GridSearchCV
# 하이퍼 파라미터 테스트의 수행 속도를 향상시키기 위해 n_estimators를 100으로 감소
xgb_clf = XGBClassifier(n_estimators=100)
params = {
'max_depth':[5,7],
'min_child_weight':[1,3],
'colsample_bytree':[0.5,0.75],}
# cv는 3으로 지정
gridcv = GridSearchCV(xgb_clf,param_grid=params,cv=3)
gridcv.fit(X_train,y_train,early_stopping_round=30,eval_metric='auc',eval_set=[(X_train,y_train),(X_test,y_test)])
print('GridSearchCV 최적 파라미터:',gridcv.best_params_)
xgb_roc_score = roc_auc_score(y_test,gridcv.predict_proba(X_test)[:,1],average='macro')
print('ROC AUC:{0:.4f}'.format(xgb_roc_score))
'''
GridSearchCV 최적 파라미터: {'colsample_bytree': 0.5, 'max_depth': 5, 'min_child_weight': 3}
ROC AUC:0.8445
'''
Python
복사
앞의 결과는 0.8413에서 0.8445로 조금 개선되었다.
이제, 이 파라미터를 가지고 다시 다른 하이퍼 파라미터를 추가해 최적화를 진행해보자. n_estimators는 1000으로 늘리고, learning_rate=0.02로 감소시키고, reg_alpha=0.03을 추가해 과적합을 제어하기로 한다.
# n_estimators는 1000으로 증가시키고, learning_rate는 0.02로 감소, reg_alpha=0.03을 추가함.
xgb_clf = XGBClassifier(n_estimators=1000,learning_rate=0.02,max_depth=5,min_child_weight=3,colsample_bytree=0.5,reg_alpha=0.03,random_state=156)
# 성능 평가 지표를 auc로, 조기 중단 파라미터값은 200으로 설정하고 학습 수행.
xgb_clf.fit(X_train,y_train,early_stopping_rounds=200,eval_metric='auc',eval_set=[(X_train,y_train),(X_test,y_test)])
xgb_roc_score = roc_auc_score(y_test,xgb_clf.predict_proba(X_test)[:,1],average='macro')
print('ROC AUC:{0:.4f}'.format(xgb_roc_score))
'''
ROC AUC:0.8463
'''
Python
복사
결과는 0.8463으로 이전보다 좀 더 개선되었다. 단점은 그냥 GBM보다는 나아졌지만 여전히 GBM을 기반으로 하고있기 때문에 수행 시간이 오래 걸린다는 점이다.
일반적으로 앙상블모델은 하이퍼 파라미터 튜닝을 통한 개선 정도가 그렇게 급격하지는 않다. 기본적으로 과적합이나 잡음에 뛰어난 알고리즘이기 때문이다.
이제, 튜닝된 모델을 가지고 각 피처의 중요도를 그래프로 나타내겠다. xgboost모듈의 plot_importance() 메서드를 사용한다.
참고로 plot_importance(booster, ax=None, height=0.2, xlim=None, ylim=None, title=’Feature importance’, xlabel=’F score’, ylabel=’Features’, fmap=’’, importance_type=’weight’, max_num_features=None, grid=True, show_values=True, **kwargs) 에서 중요한 파라미터를 확인해보면,
•
importance_type : str, default=’weight’ , 중요도가 평가되는 방법(’gain’,’cover’)
◦
weight : 트리에서 얼마나 자주 특성이 등장했는지
◦
gain : the average gain of splits which use the feature
◦
cover : average coverage of splits which use the feature
•
max_num_features : int, default=None, 그림에 나타낼 특성의 최대 수를 지정, None이면 모든 피처를 다 나타냄.
•
height : float, default=0.2, 막대 두께를 지정
from xgboost import plot_importance
import matplotlib.pyplot as plt
%matplotlib inline
fig, ax= plt.subplots(1,1,figsize=(10,8))
plot_importance(xgb_clf, ax=ax, max_num_features=20,height=0.4)
Python
복사
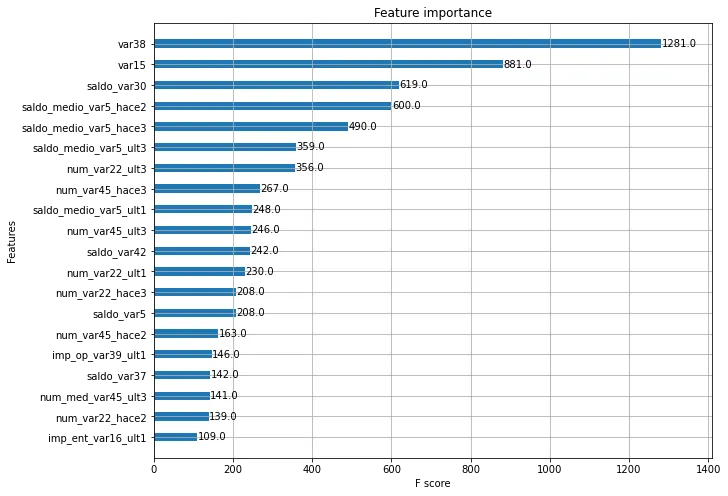
LightGBM 모델 학습과 하이퍼 파라미터 튜닝
이제, LightGBM으로 학습을 수행하고 ROC-AUC를 측정해보겠다. 앞과 동일하게 n_estimators는 500으로 지정, early_stopping_rounds는 100, 평가 데이터 세트는 테스트 데이터 세트로 하고, eval_metric은 auc로 지정하겠다.
from lightgbm import LGBMClassifier
lgbm_clf = LGBMClassifier(n_estimator=500)
evals=[(X_test,y_test)]
lgbm_clf.fit(X_train,y_train,early_stopping_rounds=100,eval_metric='auc',eval_set=evals,verbose=True)
lgbm_roc_score = roc_auc_score(y_test,lgbm_clf.predict_proba(X_test)[:,1],average='macro')
print('ROC AUC:{0:.4f}'.format(lgbm_roc_score))
'''
ROC AUC:0.8409
'''
Python
복사
참고로, roc_auc_score(y_true,y_score,*, average=’macro’, sample_weight=None, max_fpr=None, multi_class=’raise’, labels=None)
결과는 확실히 XGBoost보다 수행 시간이 단축되었다.
이제, 하이퍼 파라미터에 대한 튜닝을 수행해보자. num_leaves, max_depth, min_child_ samples, subsample을 튜닝해보겠다.
from sklearn.model_selection import GridSearchCV
# 하이퍼 파라미터 테스트의 수행 속도를 향상시키기 위해 n_estimators를 200으로 감소
lgbm_clf = LGBMCalssifier(n_estimators=200)
params = {
'num_leaves':[32,64],
'max_depth':[128,160],
'min_child_samples':[60,100],
'subsample':[0.8,1],
}
# cv는 3으로 지정
gridcv = GridSearchCV(lgbm_clf,param_grid=params, cv=3)
gridcv.fit(X_train,y_train, early_stopping_rounds=30, eval_metric='auc',eval_set=[(X_train,y_train),(X_test,y_test)])
print('GridSearchCV 최적 파라미터:',gridcv.best_params_)
lgbm_roc_score = roc_auc_score(y_test,gridcv.predict_proba(X_test)[:,1], average='macro')
print('ROC AUC: {0:.4f}'.format(lgbm_roc_score))
'''
GridSearchCV 최적 파라미터: {'max_depth': 128, 'min_child_samples': 100, 'num_leaves': 32, 'subsample': 0.8}
ROC AUC: 0.8417
'''
Python
복사
위의 최적 하이퍼 파라미터를 적용하고 다시 ROC-AUC 측정 결과를 도출해보자.
lgbm_clf = LGBMClassifier(n_estimators=1000, num_leaves=32, subsample=0.8, min_child_samples=100, max_depth=128)
evals = [(X_test,y_test)]
lgbm_clf.fit(X_train,y_train,early_stopping_rounds=100,eval_metric='auc',eval_set=evals,verbose=True)
lgbm_roc_score = roc_auc_score(y_test,lgbm_clf.predict_proba(X_test)[:,1],average='macro')
print('ROC AUC :{0:.4f}'.format(lgbm_roc_score))
'''
Early stopping, best iteration is:
[11] valid_0's auc: 0.841659 valid_0's binary_logloss: 0.14327
ROC AUC :0.8417
'''
Python
복사
LightGBM의 경우는 테스트 데이터 세트에서 ROC-AUC가 약 0.8442로 측정되었다.