
올바른 웹크롤링에 대해 학습하기 위해 다음을 참고했다

수많은 블로그들이 css selector를 사용해서 원하는 텍스트와 정보를 가져오는데 쓰고 있다. css selector로 DOM을 직접 가져오면 정확하게 텍스트를 가져올 수 있지만 서비스의 UI가 조금만 변경돼도 크롤러는 엉뚱한 데이터를 갖고 올 것이다. 그렇다면 페이지 구조가 자주 바뀌어도 본문 텍스트를 가져올 수 있는 방법이 있을까?
페이지는 업데이트 된다. 예를들어, 어떤 벨로그 포스트를 크롤링하여 수집하였지만 나중에 그 포스트는 작성자가 삭제하거나 수정 할 수도 있다. 따라서 크롤러가 방문 했던 URL을 언젠가 또 방문해서 변경사항을 반영할 필요가 있는데 이렇게 페이지의 신선도(freshness)를 유지 해 주어야만 할 것이다.
크롤러는 그런 대규모 검색 서비스를 하는 곳에서나 쓰이는 기술이지 작은 개발자들이야 그냥  BeautifulSoup나 Selenium을 잘 쓰면서 원하는 정보만 일시적으로 스크래핑 하면 땡 아닐까? 실제로 직장이나 학교에서 맞닥뜨리는 요구사항은 어느 몇 페이지의 정보만 지속적으로 갖고 와야하는 일회성 작업들인 경우가 많다.
BeautifulSoup나 Selenium을 잘 쓰면서 원하는 정보만 일시적으로 스크래핑 하면 땡 아닐까? 실제로 직장이나 학교에서 맞닥뜨리는 요구사항은 어느 몇 페이지의 정보만 지속적으로 갖고 와야하는 일회성 작업들인 경우가 많다.
BeautifulSoup나 Selenium을 잘 쓰면서 원하는 정보만 일시적으로 스크래핑 하면 땡 아닐까? 실제로 직장이나 학교에서 맞닥뜨리는 요구사항은 어느 몇 페이지의 정보만 지속적으로 갖고 와야하는 일회성 작업들인 경우가 많다.www가 가진 특성 때문에 웹 크롤링에는 고도로 발달된 알고리즘과 시스템 디자인이 필요한데 아래에서 왜 웹 크롤링이 만만치 않은지 살펴보도록 하자.
가장 중요하다고 할 수 있는 robots.txt 같은 사회적 이슈가 있다. 수백 수천 개의 웹 사이트들을 탐험하면서 웹 서버와 상호작용하기 때문에 크롤러는 박살 나기 매우 쉬운 어플리케이션이다.
→ 방문해서 데이터를 함부로 가져가지 말라고 명시 해 둔 경로에 크롤러는 방문 해서는 안된다. 이 rule을 써 둔 곳이 바로 robots.txt인데 각 사이트의 루트 도메인에서 robots.txt를 조회 해 볼 수 있다.
하지만!
검색 엔진 서비스를 만들려는게 아닌이상 대부분의 상황에서는 크롤러를 만들기 보다는 웹 스크래퍼를 만드는 것으로 끝난다. 아래와 같은 상황을 생각 해 볼 수 있다.
•
정부 관련 사이트에서 엄청 많은 공시 정보를 가져와서 엑셀에 정리 해야 함
•
매일 기상청 사이트에서 업데이트 되는 날씨 정보를 가져와야 함
•
게시판에 새 글이 올라 왔는지 정기적으로 체크하고 알림이 와야함
→ 일회성 작업들은 굳이 크롤러를 만들 필요는 없다. 이런 상황에서는 스크래퍼가 더 적합하다. 그러나 스크래퍼를 '크롤러'라고 부르고 있는 실정이긴 하다.
그렇다면 웹스크래핑 시 주의점?


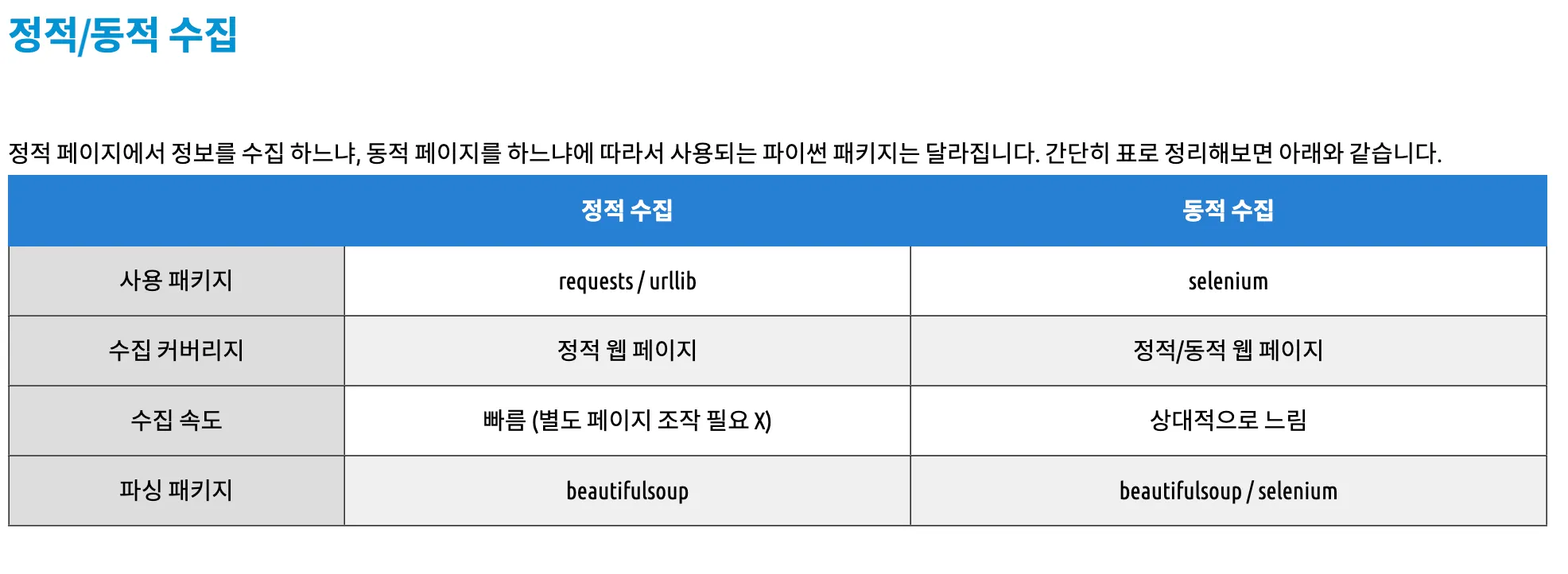
•
정적 페이지 : 웹 브라우저에 화면이 한번 뜨면 이벤트에 의한 화면의 변경이 없는 페이지
•
동적 페이지 : 웹 브라우저에 화면이 뜨고 이벤트가 발생하면(’더보기’ 등) 서버에서 데이터를 가져와 화면을 변경하는 페이지