
데이터프레임의 구조
UCI 머신러닝 저장소에서 제공하는 자동차 연비(auto mpg)데이터셋을 사용한다. 총 데이터 398개로 구성된다.
~ head() / tail()
데이터프레임으로 정리된 데이터셋을 처음 접할 때 가장 먼저 실행하는 판다스 명령은 head()메소드일 가능성이 높다. 더 나아가서 tail()메소드를 사용하면 마지막 부분의 내용을 볼 수 있다.
head() 메소드 인자로 정수 n을 전달하면 처음 n개의 행을 보여준다. tail() 메소드 인자로 n을 전달하면 마지막 n개의 행을 보여준다. 두 메소드 모두 default는 n=5이다.
import pandas as pd
# read_csv() 함수로 df 생성
df = pd.read_csv("./auto-mpg.csv", header=None) # 첫행은 열을 나타내지 않는다.
# 열 이름 지정
df.columns = ['mpg','cylinders','displacement','horsepower','weight','acceleration',
'model year','origin','name']
# 데이터프레임 df의 내용을 일부 확인
print(df.head())
mpg cylinders displacement ... model year origin name
0 18.0 8 307.0 ... 70 1 chevrolet chevelle malibu
1 15.0 8 350.0 ... 70 1 buick skylark 320
2 18.0 8 318.0 ... 70 1 plymouth satellite
3 16.0 8 304.0 ... 70 1 amc rebel sst
4 17.0 8 302.0 ... 70 1 ford torino
[5 rows x 9 columns]
print('\n')
print(df.tail())
mpg cylinders displacement ... model year origin name
393 27.0 4 140.0 ... 82 1 ford mustang gl
394 44.0 4 97.0 ... 82 2 vw pickup
395 32.0 4 135.0 ... 82 1 dodge rampage
396 28.0 4 120.0 ... 82 1 ford ranger
397 31.0 4 119.0 ... 82 1 chevy s-10
[5 rows x 9 columns]
Python
복사
~ display()
•
display() : 보통 데이터프레임을 여러개 확인할 수는 없다. 하지만, 그러고 싶을 경우 이 display() 함수를 이용해주면 된다.
ex) 만약, df1, df2, df3 를 모두 한번에 출력하고 싶다면
display(df1)
display(df2)
display(df3)
Python
복사
데이터프레임의 기본 정보
info() 메소드를 데이터프레임에 적용하면 데이터프레임에 관한 기본 정보를 화면에 출력한다. ( 클래스 유형, 행 인덱스의 구성, 열 이름의 종류와 개수, 각 열의 자료형과 개수, 메모리 할당량에 관한 정보가 포함된다.
~ 데이터프레임의 기본 정보 출력 : df.info()
print(df.info())
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 398 entries, 0 to 397
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 mpg 398 non-null float64
1 cylinders 398 non-null int64
2 displacement 398 non-null float64
3 horsepower 398 non-null object
4 weight 398 non-null float64
5 acceleration 398 non-null float64
6 model year 398 non-null int64
7 origin 398 non-null int64
8 name 398 non-null object
dtypes: float64(4), int64(3), object(2)
memory usage: 28.1+ KB
None
Python
복사
 판다스는 넘파이를 기반으로 만들어졌기 때문에 넘파이에서 사용하는 자료형을 기본적으로 사용할 수 있다. 파이썬의 기본 자료형과 비슷하지만 시간을 나타내는 datetime64와 같은 자료형이 있다는 점에서 일부 차이가 있다.
판다스는 넘파이를 기반으로 만들어졌기 때문에 넘파이에서 사용하는 자료형을 기본적으로 사용할 수 있다. 파이썬의 기본 자료형과 비슷하지만 시간을 나타내는 datetime64와 같은 자료형이 있다는 점에서 일부 차이가 있다.판다스 자료형 | 파이썬 자료형 | 비고 |
int64 | int | 정수형 데이터 |
float64 | float | 실수형 데이터 |
object | string | 문자열 데이터 |
datetime64, timedelta64 | 없음 | 시간 데이터 |
~ dtypes()
추가적으로 데이터프레임 클래스의 dtypes 속성을 사용하면 각 열의 자료형을 확인할 수 있다. 특정 열만 선택하여 적용하는 것도 가능하다.
# 데이터프레임 df의 자료형 확인
print(df.dtypes)
print('\n')
mpg float64
cylinders int64
displacement float64
horsepower object
weight float64
acceleration float64
model year int64
origin int64
name object
dtype: object
# 시리즈(mpg 열)의 자료형 확인
print(df.mpg.dtypes)
float64
Python
복사
데이터프레임의 기술 통계 정보 요약
~ describe()
describe() 메소드를 적용하면 숫자 데이터를 갖는 열에 대한 주요 기술 통계 정보(평균, 표준편차, 최댓값, 최솟값, 중간값 등)을 요약하여 출력한다.
•
데이터프레임의 기술 통계 정보 요약 : df.describe()
연속형 변수뿐만 아니라 범주형 변수에 대한 정보도 포함하고 싶을 때는 include=’all’ 옵션을 추가한다. 이때 추가되는 정보는 unique(고윳값 개수), top(최빈값), freq(빈도수) 들이다. 이들은 오직 숫자 데이터가 아닌 열에 대해서만 값을 가지고 숫자 데이터에는 이 값들이 모두 NaN으로 표시된다.# 데이터프레임 df의 기술 통계 정보 확인
print(df.describe())
mpg cylinders ... model year origin
count 398.000000 398.000000 ... 398.000000 398.000000
mean 23.514573 5.454774 ... 76.010050 1.572864
std 7.815984 1.701004 ... 3.697627 0.802055
min 9.000000 3.000000 ... 70.000000 1.000000
25% 17.500000 4.000000 ... 73.000000 1.000000
50% 23.000000 4.000000 ... 76.000000 1.000000
75% 29.000000 8.000000 ... 79.000000 2.000000
max 46.600000 8.000000 ... 82.000000 3.000000
[8 rows x 7 columns]
print('\n')
print(df.describe(include='all'))
mpg cylinders ... origin name
count 398.000000 398.000000 ... 398.000000 398
unique NaN NaN ... NaN 305
top NaN NaN ... NaN ford pinto
freq NaN NaN ... NaN 6
mean 23.514573 5.454774 ... 1.572864 NaN
std 7.815984 1.701004 ... 0.802055 NaN
min 9.000000 3.000000 ... 1.000000 NaN
25% 17.500000 4.000000 ... 1.000000 NaN
50% 23.000000 4.000000 ... 1.000000 NaN
75% 29.000000 8.000000 ... 2.000000 NaN
max 46.600000 8.000000 ... 3.000000 NaN
[11 rows x 9 columns]
print(df.describe(include = np.object)) # 범주형 데이터에 대해서만 확인하고 싶을 경우
# 변수들이 많을 경우, 보기 쉽게 transpose() 해주면 좋다.
df.describe().transpose()
Python
복사
데이터 개수 확인
각 열의 데이터 개수 - count()
info() 메소드는 각 열의 데이터 개수 정보를 출력하지만 반환해주는 값은 없기 때문에 재사용하기에 어렵다. 반면, count() 메소드는 데이터프레임의 각 열이 가지고 있는 데이터 개수를 시리즈 객체로 반환한다. 물론, 유효한 값의 개수만을 계산한다.(NaN 값은 제외한다)
•
열 데이터 개수 확인 : df.count()
# 데이터프레임 df의 각 열이 가지고 있는 원소 개수 확인
print(df.count()) # 결과는 시리즈
print('\n')
mpg 398
cylinders 398
displacement 398
horsepower 398
weight 398
acceleration 398
model year 398
origin 398
name 398
dtype: int64
# df.count()가 반환하는 객체 타입 출력
print(type(df.count()))
<class 'pandas.core.series.Series'>
Python
복사
•
df.shape : 행과 열 개수 확인 바로 가능
각 열의 고윳값 개수(범주형 변수)
1) unique() / nunique()
unique() 함수를 범주형 데이터에 사용하면 어떤 고유값들이 있는지 리스트로 확인가능하다.
#범주형 컬럼 안에는 어떤 내용이 들어있을까?
print('Education: ', bk['Education'].unique())
print('Personal Loan: ', bk['Personal Loan'].unique())
print('Securities Account: ', bk['Securities Account'].unique())
print('CD Account: ', bk['CD Account'].unique())
print('Online: ', bk['Online'].unique())
print('CreditCard: ', bk['CreditCard'].unique())
Python
복사
2) value_counts()
value_counts() 메소드는 시리즈 객체의 고유값 개수를 세는 데 사용한다. 각 열의 고유값의 종류와 개수를 확인할 수 있다. 고유값이 행 인덱스가 되고, 고유값의 개수가 데이터 값이 되는 시리즈 객체를 반환한다.
value_counts 는 기본적으로 null 값도 하나의 고유값으로 처리한다. dropna=True 옵션을 설정하면 데이터 값 중에서 NaN을 제외하고 개수를 계산한다. 옵션을 따로 지정하지 않으면 dropna=False 옵션이 기본 적용된다. 이때는 NaN이 포함된다.
•
열 데이터의 고유값 개수 : df[”열 이름”].value_counts()
df의 ‘origin’열에 value_counts() 메소드를 적용해서 고유값의 종류와 개수를 확인해보자.
# df의 특정칼럼 고유값 종류만 확인
df['특정 칼럼'].unique()
# df의 특정칼럼 고유값 종류 개수 확인
df['특정 칼럼'].nunique()
# df의 특정 열이 가지고 있는 고유값의 종류와 종류별 개수 확인
unique_values = df["origin"].value_counts()
print(unique_values)
print('\n')
1 249 # 미국
3 79 # 유럽
2 70 # 일본
Name: origin, dtype: int64
# value_counts 메소드가 반환하는 객체 타입 출력
print(type(unique_values))
<class 'pandas.core.series.Series'> # 반환되는 타입은 시리즈
Python
복사
3) nlargest(n,’var’)
특정 변수의 최대값 n 에 해당하는 데이터들을 뽑기
top10_review = df.nlargest(10, 'reviews_per_month')
top10_review
Python
복사
reviews_per_month 의 최대값 10개의 데이터에 해당하는 데이터만 추출해서 top10_review 데이터프레임으로 저장
Null 값 개수 확인
•
특성별 결측치 개수 확인 : df.isnull().sum()
•
데이터셋의 전체 결측치 개수 확인 : df.isnull().sum().sum()
•
결측치가 존재하는 컬럼 확인 : df.isnull().any(axis=0)
# 전체 데이터셋에서 결측치 비율 확인하기
print("총 결측치 수: {} = 전체 데이터의 {:.2f}% ".format(df.isnull().sum().sum(), (df.isnull().sum().sum()*100)/(df.shape[0]*df.shape[1])))
Python
복사
중복 데이터 확인하기
# 중복되는 데이터가 있는지 확인하기
df.duplicated().sum()
Python
복사
분석하기 쉬운 변수 이름으로 변경해주는 tip
#컬럼명 변경하기
df.columns = ['var1','var2',...'varN']
df.columns
Python
복사
필요없는 변수 제거해주기
df1 = df.drop(['var1','var2'], axis=1) # 기본 : inplace=False
Python
복사
통계 함수 적용
~ 평균값
mean() 메소드를 적용하면 산술 데이터를 갖는 모든 열의 평균값을 각각 계산하여 시리즈 객체로 반환한다. 물론, 특정 열을 선택해서 평균값을 계산할 수도 있다.
•
모든 열의 평균값 : df.mean() → Series 형태로 반환
•
특정 열의 평균값 : df[”열 이름”].mean() 또는 df.열 이름.mean() → 값으로 반환
# 평균값
print(df.mean())
print('\n')
mpg 23.514573
cylinders 5.454774
displacement 193.425879
weight 2970.424623
acceleration 15.568090
model year 76.010050
origin 1.572864
dtype: float64
print(df['mpg'].mean()) # mpg 열에 대해서만 평균 계산
23.514572864321615
print(df.mpg.mean()) # 위와 같은 결과
23.514572864321615
print('\n')
print(df[['mpg','weight']].mean()) # 두 열에 대해서만 평균 계산
mpg 23.514573
weight 2970.424623
dtype: float64
Python
복사
~ 중간값
median() 메소드를 적용하면 산술 데이터를 갖는 모든 열의 중앙값을 각각 계산하여 시리즈로 반환한다. 물론, 특정 열을 선택해서 중앙값을 계산할 수도 있다.
•
모든 열의 중앙값 : df.median()
•
특정 열의 중앙값 : df[”열 이름”].median()
df.열 이름.median 하면 같은 결과가 나오지 않음에 주의 # 중앙값
print(df.median())
print('\n')
mpg 23.0
cylinders 4.0
displacement 148.5
weight 2803.5
acceleration 15.5
model year 76.0
origin 1.0
dtype: float64
print(df['mpg'].median())
23.0
Python
복사
~ 최대값
max() 메소드를 적용하면 각 열이 갖는 데이터 값 중에서 최대값을 계산하여 시리즈로 반환한다. 물론, 특정 열을 선택해서 계산할 수도 있다.
•
모든 열의 최대값 : df.max()
•
특정 열의 최대값 : df[”열 이름”].max()
문자열 데이터의 비교는 문자열을 ASCII 숫자로 변환하여 크고 작음을 비교한다. # 최대값
print(df.max())
print('\n')
mpg 46.6
cylinders 8
displacement 455.0
horsepower ? # 문자열 데이터
weight 5140.0
acceleration 24.8
model year 82
origin 3
name vw rabbit custom # 문자열 데이터
dtype: object
print(df['mpg'].max())
46.6
Python
복사
위에서 horsepower 열은 데이터값에 ‘?’ 문자가 포함되어 있어서 다른 숫자값까지 전부 문자열로 만들어버린다. 따라서 ASCII 코드로 변환하여 크기비교를 하면 ‘?’가 최대값이 되는 것이다.
•
idxmax()
최댓값의 인덱스를 출력
# 지역(var1)별로 가격(var2)의 최댓값을 구한다.
df.groupby(['neighbourhood_group'])['price'].idxmax()
Python
복사
~ 최소값
min() 메소드를 적용하여 각 열이 갖는 데이터 값 중에서 최소값을 계산하여 시리즈로 반환한다. 물론, 특정 열을 선택해서 계산할 수도 있다.
•
모든 열의 최소값 : df.min()
•
특정 열의 최소값 : df[”열 이름”].min()
마찬가지로 문자열 데이터에 대해서는 ASCII코드로 변환하여 크기 비교한다.
# 최소값
print(df.min())
print('\n')
mpg 9.0
cylinders 3
displacement 68.0
horsepower 100.0
weight 1613.0
acceleration 8.0
model year 70
origin 1
name amc ambassador brougham
dtype: object
print(df['mpg'].min())
9.0
Python
복사
사실상, horsepower같은 경우에는 숫자값 데이터에 괜히 “?” 값이 있어서 문자열 데이터로 변환된 경우다 . 따라서, 제대로 분석하려면 ?값을 제거하거나 다른값으로 변경 후, 숫자형 데이터로 변환해서 분석해야 한다.
•
idxmin()
최솟값의 인덱스를 출력한다.
# 지역(var1)별로 가격(var2)의 최댓값을 구한다.
df.groupby(['neighbourhood_group'])['price'].idxmin()
Python
복사
~ 표준편차
std() 메소드를 적용하면 산술 데이터를 갖는 열의 표준편차를 계산하여 시리즈로 반환한다. 물론 특정 열을 선택하여 계산할 수도 있다.
•
모든 열의 표준편차 : df.std()
•
특정 열의 표준편차 : df[”열 이름”].std()
문자열 데이터를 갖는 열에 대해서는 계산을 하지 않는다.
# 표준편차
print(df.std())
print('\n')
mpg 7.815984
cylinders 1.701004
displacement 104.269838
weight 846.841774
acceleration 2.757689
model year 3.697627
origin 0.802055
dtype: float64
print(df['mpg'].std())
7.815984312565782
Python
복사
~ 상관계수
corr() 메소드를 적용하면 두 열 간의 상관계수를 계산한다. 산술 데이터를 갖는 모든 열에 대해서 2개씩 서로 짝을 짓고, 각각의 경우에 대하여 상관계수를 계산한다.
•
모든 열의 상관계수 : df.corr()
•
특정 열의 상관계수 : df[열 이름의 리스트].corr()
문자열 데이터는 제외한다. 결과는 행렬 형태로 데이터프레임으로 나오게 된다.
# 상관계수
print(df.corr())
print('\n')
mpg cylinders ... model year origin
mpg 1.000000 -0.775396 ... 0.579267 0.563450
cylinders -0.775396 1.000000 ... -0.348746 -0.562543
displacement -0.804203 0.950721 ... -0.370164 -0.609409
weight -0.831741 0.896017 ... -0.306564 -0.581024
acceleration 0.420289 -0.505419 ... 0.288137 0.205873
model year 0.579267 -0.348746 ... 1.000000 0.180662
origin 0.563450 -0.562543 ... 0.180662 1.000000
[7 rows x 7 columns]
print(df[['mpg','weight']].corr()) #특정 열에 대해서 상관행렬 구하기
mpg weight
mpg 1.000000 -0.831741
weight -0.831741 1.000000
Python
복사
왜도 / 첨도 확인
왜도와 첨도를 확인하는 방식은 여러 가지가 있다.
먼저 왜도와 첨도를 어떻게 판단할지 보자
•
첨도 : 정규분포 m=0 을 기준으로, 정규분포보다 뾰족한 경우 m>0 , 정규분포보다 완만한 경우 m<0 으로 값을 계산한다.
•
왜도 : 비대칭도 라고도 하며, 평균에 비해 최빈값이 얼마나 치우쳐져있는지를 나타내는 척도다. 우측으로 치우칠수록 음의값, 좌측으로 치우칠수록 양의 값을 가진다.
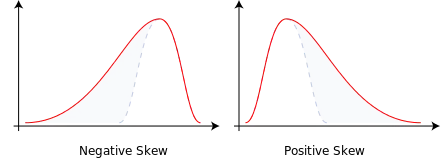
1) mean() 과 median() 차이 확인하기
단순히 평균과 중앙값의 차이가 크다면 이상치가 많은 분포라고 추론할 수 있고, 차이가 적다면 이상치가 적은 데이터라고 생각할 수 있다.
2) 왜도와 첨도 값 확인하기
파이썬에서는 왜도와 첨도값을 계산해주는 내장 함수가 있다.
•
df.kurt(axis=None, skipna=True, level=None, numeric_only=None, kwargs)
◦
axis : 축
◦
skipna : 계산할 때 결측치를 무시할지의 여부
◦
level : 멀티인덱스의 경우 레벨 지정 인자
◦
numeric_only : float, int, bool 형식만 포함할지의 여부
•
df.skew(axis=None, skipna=True, level=None, numeric_only=None, kwargs)
< 인자 동일 >